精炼回答
代码语法修复的核心其实是一个错误检测加修正的闭环过程。当生成的代码存在语法错误时,我们需要依靠静态分析和AST(抽象语法树)操作来定位问题,然后根据错误的复杂程度选择合适的修复策略。
从技术实现上看,整个过程可以分成三个层次来处理。语法解析层是基础,通过编译器或解析器获取精确的错误位置和类型信息。Python的ast模块、JavaScript的Babel、Java的JavaParser都是常用的工具,它们能把SyntaxError异常转换成结构化的错误信息。规则修复层处理那些模式明确的简单错误,比如缺少括号就补全配对、缺少分号就插入、缩进错误就按上下文调整。IDE里的Quick Fix功能本质上就是这个思路,用预设规则快速响应高频错误。智能修复层则是用大语言模型来处理复杂场景,把报错信息和问题代码一起作为输入让模型理解意图,像GPT-4或CodeLlama这类经过代码训练的模型能直接输出修正后的版本。
工程上最实用的做法是迭代式修复:生成代码后立即进行语法检查,如果发现错误就把错误信息反馈给修复引擎,简单错误走规则通道快速处理,复杂错误调用模型重新生成,最多循环3-5次防止死循环。这种分层策略既能保证响应速度又能应对各种复杂情况,在实际的AI代码生成服务中已经被广泛采用。
扩展分析
错误诊断与分层修复策略
语法错误其实有明显的层次区别,理解这种区别对选择修复方案至关重要。结构性错误是最容易处理的一类,比如括号不匹配、缺少冒号分号这种,编译器一眼就能看出来,错误信息非常明确。上下文相关错误需要结合周围代码才能判断,像缩进问题、作用域混乱、类型不匹配,这些错误的修复往往需要理解代码的逻辑结构。语义模糊错误最为棘手,表面上语法合法但逻辑不对,比如调用了不存在的方法、参数顺序颠倒,这类问题有时候编译器都能通过但运行时会报错。
所有现代编译器做语法检查本质上都是在构建和遍历AST。当代码输入进来,词法分析器先把字符流切成token,然后语法分析器按照语言的文法规则尝试构建树结构。一旦某个token放不进合法的树节点位置,就会抛SyntaxError并定位到具体行列号。整个检测和修复的闭环关系可以用这个流程来理解:
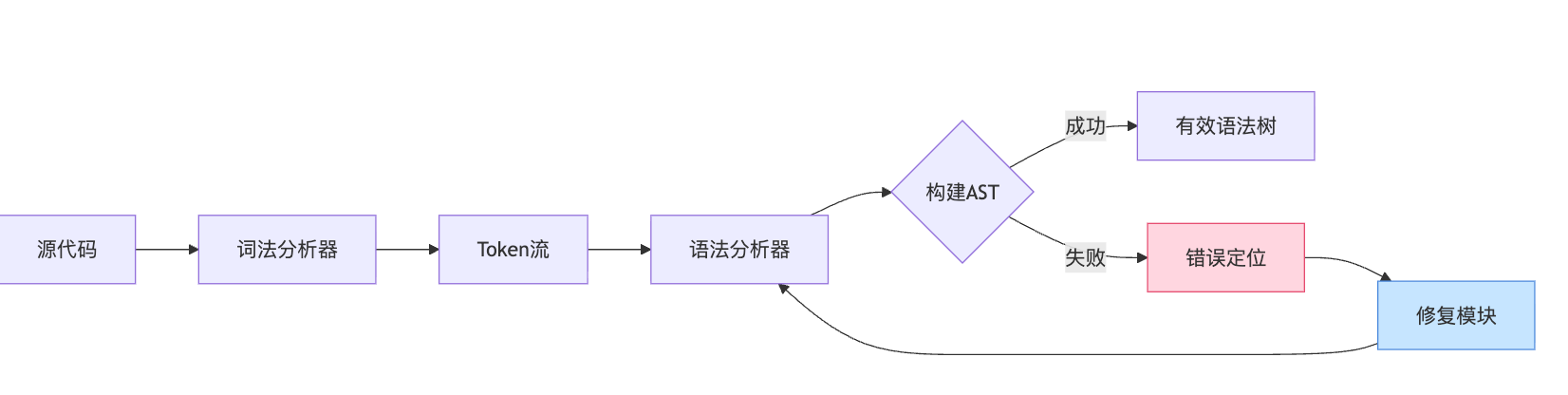
拿Java举例,编译器发现if (x > 0这行代码时,在构建if语句节点时发现条件表达式后面应该跟右括号,结果遇到了换行符,这时就会定位到具体位置并报告'expected )'。有了这个精确信息,修复模块才能介入。
传统的规则引擎方案在实际项目里能解决70%的语法错误,因为它快速稳定且可解释。典型的做法是维护一个错误模式到修复动作的映射表,检测到Missing semicolon错误就在当前语句末尾插入分号,发现Unmatched parenthesis就向上扫描找到最近的未闭合括号并配对。这种方案的设计可以用策略模式来实现:
publicclassSyntaxFixer{
privateMap<String,FixStrategy> strategyMap;
publicStringfix(String code,CompilerError error){
String errorType = error.getType();
FixStrategy strategy = strategyMap.get(errorType);
if(strategy !=null){
return strategy.apply(code, error.getPosition());
}
return code;// 无法修复则返回原始代码
}
}
classMissingSemicolonFiximplementsFixStrategy{
@Override
publicStringapply(String code,int position){
StringBuilder fixed =newStringBuilder(code);
fixed.insert(position,';');
return fixed.toString();
}
}
但规则引擎的局限在于只能处理局部结构性错误,遇到需要理解代码意图的场景就无能为力了。这时候就需要引入大语言模型。现在主流的代码模型像GPT-4、Claude或者开源的CodeLlama都是经过海量代码训练的,它们不是在做简单的模式匹配,而是理解了代码的语义和上下文,能根据程序员的意图来推断正确的修复方式。
假设AI生成了这样一段Python代码存在多处语法错误:
defcalculate_discount(price, level)
if level =='vip'
discount = price *0.8
else:
discount = price *0.9
return discount
传统规则引擎可能只能修复其中一个错误,因为它按行处理。但把错误信息和代码一起喂给LLM,构造这样的prompt:"以下代码存在SyntaxError,请修复使其可运行:",模型能一次性输出正确版本。关键是要把编译器的错误诊断结果作为上下文传给模型,这样修复的准确率会大幅提升。
工程上需要设计一个反馈循环来保证修复质量:
publicclassIterativeFixingEngine{
privatestaticfinalint MAX_ATTEMPTS =3;
privatefinalSyntaxChecker checker;
privatefinalLLMFixerService llmFixer;
publicFixResultfixWithRetry(String code){
String currentCode = code;
List<String> attemptHistory =newArrayList<>();
for(int attempt =0; attempt < MAX_ATTEMPTS; attempt++){
SyntaxError error = checker.check(currentCode);
if(error ==null){
returnFixResult.success(currentCode, attempt +1);
}
attemptHistory.add(error.getMessage());
String prompt =buildIterativePrompt(currentCode, error, attemptHistory);
currentCode = llmFixer.fixWithPrompt(prompt);
// 防止模型陷入重复错误
if(attemptHistory.size()>=2&&
attemptHistory.get(attemptHistory.size()-1)
.equals(attemptHistory.get(attemptHistory.size()-2))){
break;// 连续两次同样的错误说明修复策略失效
}
}
returnFixResult.failure(currentCode, attemptHistory);
}
}
这个重试机制很关键,把历史错误信息也传给模型,让它知道之前的尝试失败了,这样能显著提高收敛速度。通常3轮以内就能收敛到正确结果。
方案选择的判断标准主要看三个维度。错误复杂度是首要考虑因素,如果是缺分号这种明确的结构性错误,用规则引擎处理延迟低成本也低;如果涉及到逻辑重构或者需要理解业务意图的,必须上LLM。实时性要求也很重要,像IDE里的实时提示必须毫秒级响应,这时候只能用预编译的规则库;如果是离线的代码审查工具,调用一次模型API完全可以接受。可解释性需求在金融或医疗这类对安全要求高的场景特别关键,每次修复都要能追溯原因,规则引擎天然满足这个要求,而模型输出的修复有时候是"黑盒"的。
工程落地的完整方案
把修复系统真正在生产环境跑起来,需要考虑的远不止算法本身。我会把整个系统拆成四个关键模块:错误检测层负责精准定位问题,修复引擎层根据错误类型选择处理策略,验证评估层确保修复质量,反馈优化层持续改进修复能力。这样的架构设计既保证了各模块的独立性,也便于根据实际情况灵活调整策略:
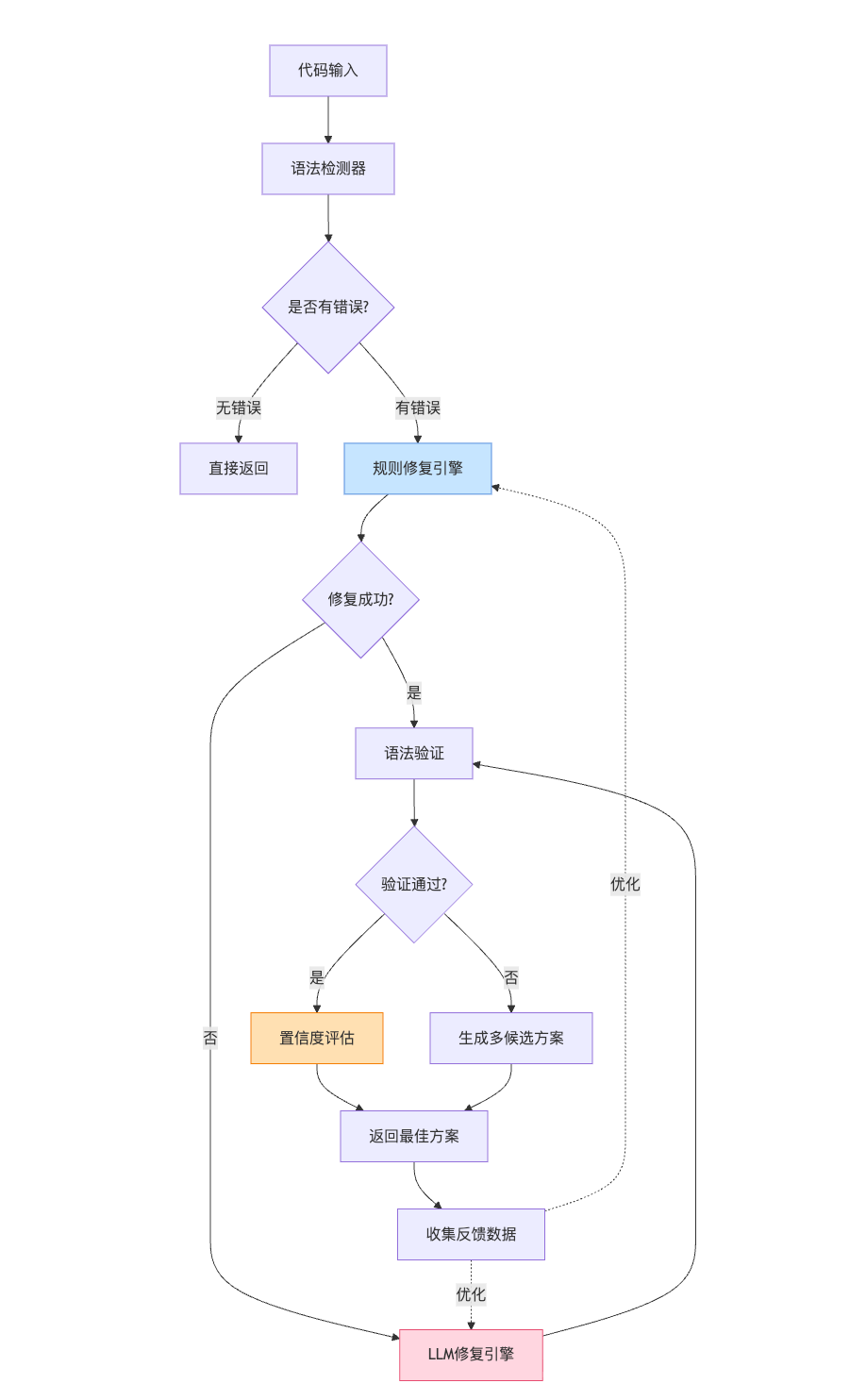
这样设计的好处是不同复杂度的错误可以走不同通道,简单问题快速响应,复杂问题保证准确率。降级策略也很明确,规则引擎处理不了才调LLM,既能控制成本也能保证实时性。
AST操作的具体实现需要针对不同语言选择合适的工具。拿Java举例,可以利用JavaParser这个库来检测和修复括号缺失问题:
publicclassParenthesisFixer{
publicStringfix(String code,SyntaxError error){
String[] lines = code.split("\n");
int lineIndex = error.getLine()-1;
String problemLine = lines[lineIndex];
// 找到语句结束位置插入右括号
int insertPos =findStatementEnd(problemLine, error.getColumn());
String fixed = problemLine.substring(0, insertPos)+")"
+ problemLine.substring(insertPos);
lines[lineIndex]= fixed;
returnString.join("\n", lines);
}
privateintfindStatementEnd(String line,int errorColumn){
// 向后扫描找分号或左花括号
for(int i = errorColumn; i < line.length(); i++){
if(line.charAt(i)==';'|| line.charAt(i)=='{'){
return i;
}
}
return line.length();
}
}
这个实现看起来简单,但实际要考虑很多边界情况,比如注释里的括号、字符串字面量里的括号,这些都不能误判。工程上需要先做Token级别的过滤,排除掉这些干扰项。
集成LLM的关键在于构造高质量的上下文,不能只把错误代码扔给模型。prompt工程需要包含错误的完整信息和修复要求:
publicclassLLMFixerService{
privatefinalOpenAIClient client;
publicStringfixWithLLM(String code,SyntaxError error){
String prompt =buildPrompt(code, error);
CompletionRequest request =CompletionRequest.builder()
.model("gpt-4")
.messages(List.of(
Message.system("You are an expert code fixer. "
+"Fix syntax errors while preserving original logic."),
Message.user(prompt)
))
.temperature(0.2)// 低温度保证稳定性
.build();
CompletionResponse response = client.complete(request);
returnextractFixedCode(response.getChoices().get(0).getMessage());
}
privateStringbuildPrompt(String code,SyntaxError error){
returnString.format(
"The following code has a %s error at line %d, column %d:\n\n"
+"```\n%s\n```\n\n"
+"Error message: %s\n\n"
+"Please fix this error and return only the corrected code "
+"without explanations.",
error.getType(), error.getLine(), error.getColumn(),
code, error.getMessage()
);
}
}
修复完成后不能直接返回,必须经过严格的验证流程。我会计算一个置信度分数来决定是否采用这个修复方案:
publicclassConfidenceEvaluator{
publicdoubleevaluate(String originalCode,String fixedCode,
FixMethod method){
double score =0.0;
// 语法正确性检查(必须满足)
if(!syntaxChecker.isValid(fixedCode)){
return0.0;
}
score +=0.4;
// 代码相似度(修改越少越好)
double similarity =calculateEditDistance(originalCode, fixedCode);
score += similarity *0.3;
// 修复方法置信度(规则引擎比LLM更可靠)
if(method ==FixMethod.RULE_BASED){
score +=0.3;
}else{
score +=0.15;// LLM修复的置信度打折
}
return score;
}
privatedoublecalculateEditDistance(String s1,String s2){
int distance =LevenshteinDistance.getDefaultInstance()
.apply(s1, s2);
int maxLength =Math.max(s1.length(), s2.length());
return1.0-(double) distance / maxLength;
}
}
当置信度低于阈值时,生成多个候选方案让用户选择,而不是强行使用一个不确定的修复结果。这种设计体现了对用户体验的考虑。
实际项目里不需要从零开始造轮子,很多成熟工具都可以直接集成。比如你在做Java代码修复,SonarQube可以提供非常详细的错误报告和修复建议。我会先接入SonarQube的API来做初步检测,它的规则引擎已经覆盖了大部分常见错误。对于它处理不了的复杂场景,再调用自己的LLM修复服务。这样的混合方案最能体现工程实用主义。
性能优化方面需要设定明确的目标,比如规则引擎修复必须在50毫秒内完成,LLM调用控制在2秒以内。具体的优化手段包括对高频错误类型预先缓存修复模板避免重复计算,对大文件只解析出错的代码块而不是整个文件,对LLM调用使用批处理策略把多个小错误合并成一次请求。修复失败的时候不能让用户一头雾水,提供清晰的错误解释和手动修复指引,在前端界面高亮显示错误位置,旁边给出修复建议和一键应用按钮。如果自动修复失败,提供"查看相似案例"或"咨询技术文档"的快捷入口。
跨领域思考与未来演进
代码语法修复这个问题巧妙地横跨了编译原理和AI两个领域,既需要掌握传统的静态分析方法,也要理解现代语言模型的能力边界。传统编译器能精准定位错误,但修复策略有限;AI模型能理解意图,但可能引入新的不确定性。关键是找到两者的最佳结合点。
语法错误修好了,语义错误怎么办?这个问题比语法错误复杂一个量级,因为它需要理解业务逻辑。比如一个商品库存扣减的函数,语法完全正确但扣减逻辑写反了,这种错误只能靠单元测试加上代码审查来发现。如果要用AI来辅助检测,需要把业务规则和测试用例作为上下文一起输入,让模型判断代码行为是否符合预期。从我之前做过的代码自动生成项目经验来看,专门处理前端表单的CRUD代码时,刚开始模型生成的代码经常缺分号或者变量名拼错。后来加了一层自动修复机制,先用ESLint跑一遍静态检查,能自动fix的就直接修复,修不了的就把错误信息反馈给模型重新生成,这样大幅降低了人工干预的次数。
安全性问题在生产环境必须考虑。自动修复会不会引入安全漏洞是很现实的风险。我会在修复流程里嵌入安全扫描环节,用静态分析工具检测修复后的代码是否引入了SQL注入、XSS这类常见漏洞。对于敏感度高的代码模块,可以设置白名单机制,只允许特定类型的修复操作。更严格的做法是把自动修复的结果标记为待审核状态,必须经过人工review才能合入主分支。
跨语言支持的核心挑战在于每种语言的语法规则和错误类型差异很大。我的思路是设计一个抽象的修复框架,把语言相关的部分做成插件。比如错误检测层调用不同语言的编译器API,修复策略层针对每种语言维护独立的规则库,但验证流程和置信度评估逻辑可以复用。如果用LLM做修复,现在主流的代码模型像CodeLlama、DeepSeek-Coder都是多语言训练的,可以统一处理。关键是在prompt里明确指定语言类型,并在系统消息里强调要遵守该语言的编码规范。
未来的方向是Agent化的开发助手,不只是修复语法错误,而是能理解开发者的意图,主动发现潜在问题并给出优化建议。比如结合项目的代码库和文档搭建RAG系统,当开发者写出有问题的代码时,Agent不仅能修复错误,还能告诉你为什么这样改,并推荐项目里类似场景的最佳实践。现在很多团队在探索用Agent的方式来做代码修复,不是简单调一次模型,而是让Agent能够自主调用编译器、查询文档、甚至跑测试用例,通过多轮交互来确定最佳修复方案。配合MCP这种模型上下文协议,不同的开发工具可以共享上下文信息,形成更连贯的开发体验。这种前瞻性的演进方向,代表着AI辅助编程从工具到伙伴的转变。