精炼回答
代码大模型和文本大模型在架构上本质相同,都基于Transformer,核心区别在于训练数据和优化目标。代码模型专门在编程语言语料上训练,学习的是代码的语法结构、API调用模式、变量命名规范这些编程特有的模式,而文本模型学习的是自然语言的语义和语法。
代码预训练会收集GitHub、StackOverflow等平台的开源代码仓库,清洗掉注释不完整、代码质量差的样本后,将代码文件按token切分输入模型。预训练任务主要有几种:最常见的是自回归预测下一个token,就像GPT那样根据前文生成后续代码;还有填空式预训练(Fill-in-the-Middle),随机mask掉中间代码让模型补全,这对代码补全场景特别有效;有些模型会做双向编码来理解代码语义,用于代码搜索或漏洞检测。
训练时会特别处理代码的结构化特征,比如保留缩进、识别函数边界、理解跨文件的import关系。像Copilot这类模型还会把代码和对应的注释、文档关联起来一起训练,让模型既能写代码也能理解需求。预训练完成后通常还要在高质量的代码-注释对上做指令微调,这样才能准确响应"写一个快速排序函数"这类编程需求。
扩展分析
代码与文本的本质差异
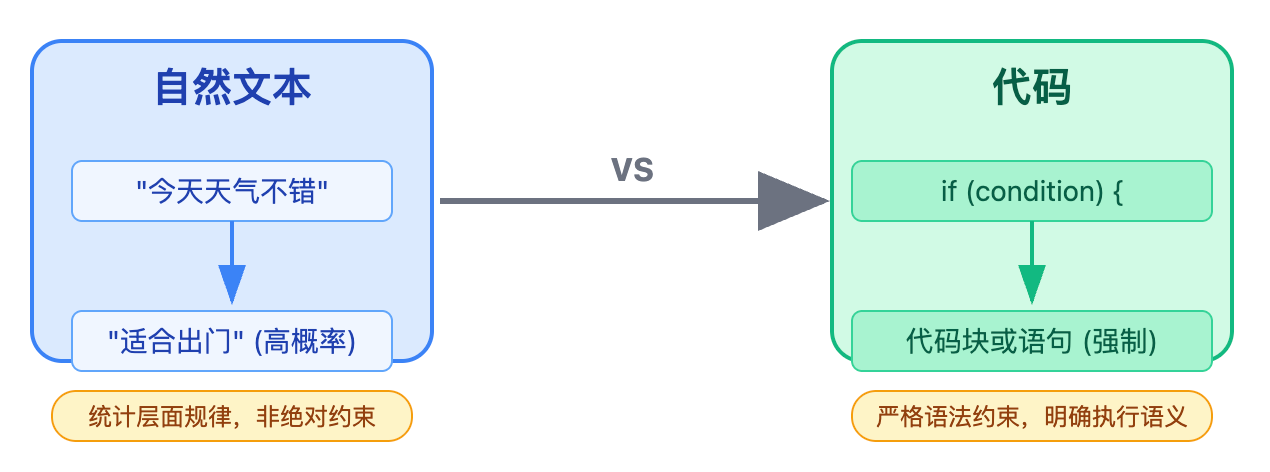
代码和自然文本最大的区别是它有严格的语法约束和明确的执行语义。自然语言更多是统计层面的规律。
比如"今天天气不错"后面接"适合出门"的概率比较高,但不是绝对的语法约束。而代码如果写了if (condition) 后面必须跟一个代码块或语句,这是编译器强制要求的。更重要的是代码有结构化的语义,一个变量的作用域是由花括号边界决定的,函数调用涉及参数类型匹配和返回值处理,这些都是可以用抽象语法树精确表达的结构。
举个电商系统的例子,在写价格计算逻辑时,BigDecimal discount = price.multiply(rate) 这行代码,模型需要知道参数类型必须匹配,返回值也是BigDecimal,这种API调用的类型约束是代码特有的。当你在IDE里敲完函数名按下左括号,代码模型能准确提示参数类型和顺序,这依赖它对API签名的深度理解,这种能力是纯文本模型很难具备的。
早期的代码模型会显式地把AST或控制流图编码到模型输入里,比如先用编译器解析出语法树,再把树结构转成序列喂给模型。但这种方式工程复杂度很高,现在主流做法是让Transformer隐式地学习这些结构。代码的结构信息其实蕴含在缩进、关键字、括号匹配这些表面特征里,只要训练数据量够大,Transformer的自注意力机制能够学到变量作用域、函数调用层级这些隐含关系。像Codex这样的模型,虽然输入就是纯文本序列,但它确实能准确推断出一个变量在哪里被定义、在哪里被使用。
比如在代码补全时,当你写到list.然后按tab,模型需要推荐add、get这些方法。这要求模型知道list的类型是ArrayList还是LinkedList,这个类型信息可能是在几十行之前的变量声明处定义的。模型要做对这个任务,就必须学会从上下文里追踪变量类型,这本质上是在学习代码的数据流语义。
预训练任务的设计理念
自回归预训练就是让模型根据前面的代码预测下一个token,这个任务对生成场景很有效,但有个问题——它只能看到前文。而程序员实际写代码时,经常是先写函数签名和主逻辑框架,再回过头补充中间的实现细节。Fill-in-the-Middle预训练正是模拟这种场景,随机把代码中间一段mask掉,让模型根据前后文补全。
假设有这样一段订单处理代码:
publicOrderprocessOrder(int orderId, BigDecimal amount){ // [MASK] - 中间逻辑被遮盖 return order; }
java
纯自回归模型只能看到函数签名,很难准确推断中间要干什么。但如果模型能看到后面的return order,它就能推断中间应该有创建订单、计算金额、初始化订单对象的逻辑。这种双向上下文理解对代码补全特别重要,因为它更接近程序员真实的编码习惯。
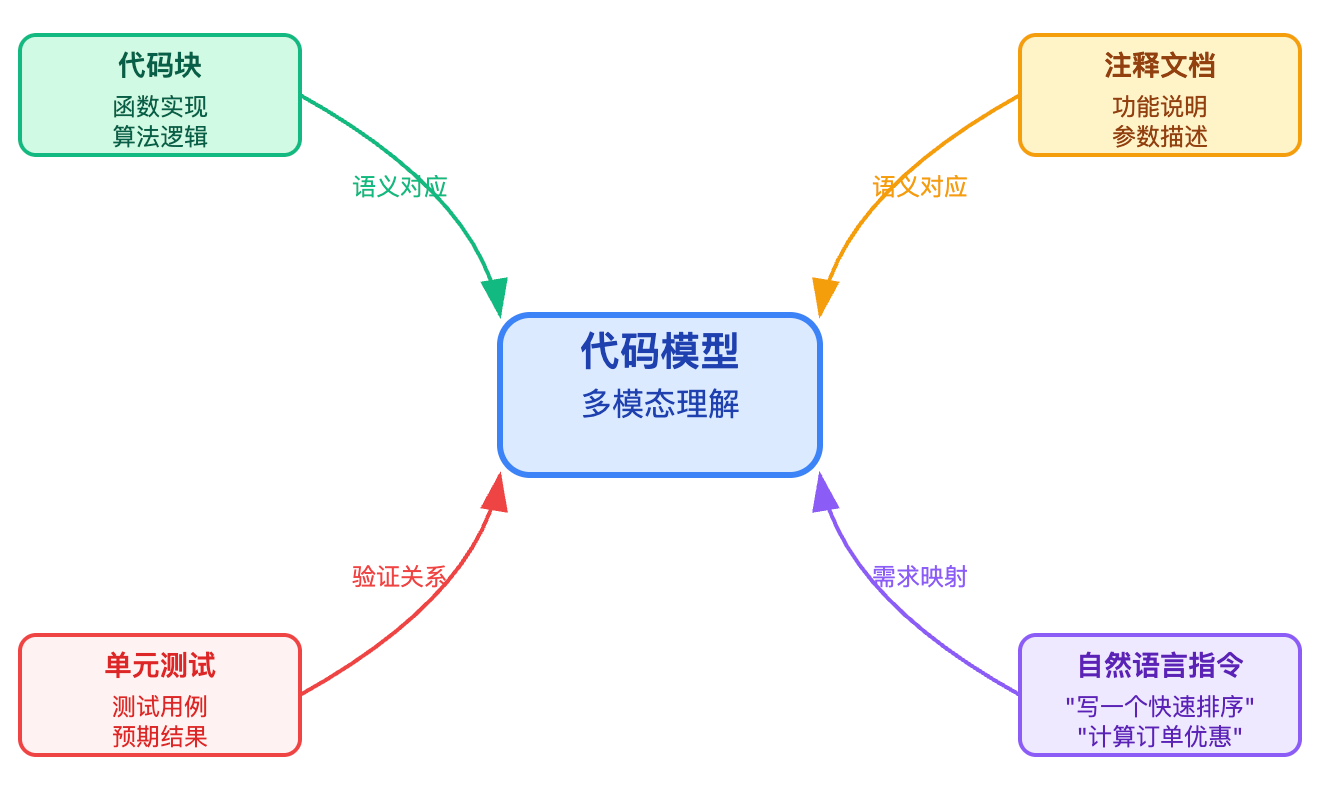
代码其实不是孤立存在的,它总是和注释、文档、单元测试绑定在一起。一个好的代码模型需要理解这三者之间的对齐关系。当你在代码里写了一个函数注释 // 计算订单优惠后的实付金额,紧接着写函数实现,模型需要学到注释和代码之间的语义对应关系。GitHub Copilot这类模型就是这样训练的,它会把代码块和它对应的注释、文档字符串作为样本对一起学习,这样当你在IDE里写了注释后,模型就能根据注释意图生成符合预期的代码实现。
这种多模态对齐还体现在代码和自然语言指令之间。用户说"写一个快速排序",模型要能把这个自然语言需求映射到具体的代码实现。这需要在预训练阶段见过大量的代码-文档对,学到编程术语和代码模式的对应关系。很多模型在预训练完成后还会专门在指令数据集上做微调,比如收集LeetCode题目的描述和标准答案,或者从技术博客里抽取"如何实现xx"这种问答对,这样才能让模型准确响应编程指令。
文本模型的核心目标是语言流畅性和语义连贯性,只要生成的句子读起来通顺、意思合理就算成功。但代码模型不仅要生成看起来像代码的序列,更重要的是生成的代码要能通过编译、正确执行。现在越来越多的代码模型引入执行反馈来增强训练,比如生成一段代码后直接跑单元测试,测试通过的样本给更高权重。AlphaCode这类模型会生成多个候选代码方案,通过执行测试用例来筛选出正确的。代码正确性是个离散的、可验证的指标,要么能跑通要么报错,不像文本质量是个模糊的连续评价。这就导致代码模型很适合用强化学习来优化,把能否通过测试作为reward信号,引导模型生成更准确的代码。
工程实践
模型选型与数据准备
主流代码大模型在技术路线上各有侧重,选型时需要结合具体场景来判断。GitHub Copilot背后的Codex是典型的闭源商业方案,它的优势在于训练数据质量高,GitHub自己的数据就包含了上亿级别的高质量仓库,而且模型经过大量用户反馈迭代,对IDE补全场景的准确率很高。但问题是闭源,没法针对特定领域做深度定制。StarCoder和CodeLlama是目前开源里效果最好的两类,StarCoder更强调多语言平衡性,在80多种编程语言上训练,特别适合需要跨语言代码理解的场景,比如做代码搜索或者漏洞检测。CodeLlama则是基于Llama2继续在代码上训练的,它的优势是长上下文能力强,支持16K甚至更长的输入,如果你要理解大型项目的代码依赖关系,这个能力就很关键。
如果是做通用IDE插件,直接用Copilot的API最省事,但成本高而且数据要上传到外部;如果公司对代码安全性要求严格,就得选开源模型自己部署,CodeLlama是不错的起点,可以拿公司内部的代码库继续做预训练,增强对特定业务领域的理解。
代码数据清洗的复杂度远不止抓取这么简单。GitHub上很多仓库其实是玩具项目或者教学demo,代码质量参差不齐。工业界通常会用star数、fork数、contributor数量这些指标做初筛,只保留活跃度高的仓库。然后要做去重,因为很多代码是fork过来的,完全相同的代码片段会污染训练分布。更细致的做法是按文件级别算哈希去重,还要识别自动生成的代码,比如protobuf编译出来的Java类,这些代码模式固定,学习价值不高,通常会过滤掉。
代码文件不能简单拼接,需要保留仓库结构信息。比如一个Java类引用了另一个包里的工具类,模型要学到这种跨文件依赖关系,就需要在训练样本里体现。StarCoder的做法是把整个仓库的文件按依赖关系排序后拼接,这样模型能学到import语句和实际调用之间的关联。
任务适配与落地优化
自回归预训练适合生成完整的代码片段,比如你给一个函数描述,模型从头开始写实现,这种场景自回归效果最好。但如果是IDE里的实时补全,用户写到一半停下来,期望模型接着往下写,这时候Fill-in-the-Middle就更合适,因为它见过中间被挖空的训练样本,知道怎么根据前后文推断缺失部分。假设在写一个订单处理函数,用户写完了函数签名和最后的return语句,中间空着等模型补全。自回归模型只能看到函数签名,可能会生成一些通用逻辑。但Fill-in-the-Middle模型能看到后面返回了一个Order对象,就能推断中间应该有创建和初始化Order的逻辑,补全的准确性会高很多。
现在不少模型开始用多任务混合训练,同时优化代码生成、代码补全、代码解释这几个目标。比如在一个batch里既有"根据注释生成代码"的样本,也有"给代码写注释"的反向任务,这种双向对齐能让模型既会写代码也能理解代码意图,对代码review或者自动化测试生成这类下游任务很有帮助。
预训练模型虽然有代码能力,但直接用在生产环境效果往往不够好,需要针对具体任务做指令微调。比如代码补全任务,我们会收集真实IDE里的补全日志,把用户输入的前文和最终采纳的补全结果作为训练对,这样微调出来的模型更贴合实际使用习惯。微调时一个关键优化是调整采样温度temperature,代码补全需要确定性强的输出,temperature要调低到0.2左右,而代码生成可能需要多样性,temperature可以设到0.6-0.8。
部署代码大模型最大的挑战是推理延迟,IDE补全要求100毫秒内返回结果,大模型很难达到。工业界常见的优化手段包括模型量化、KV cache复用、投机采样这几种。投机采样是2025年比较火的优化技术,用一个小模型快速生成候选token,再用大模型并行验证,这样能把生成速度提升2-3倍。在代码补全场景特别有效,因为很多补全是高频模式,小模型基本能猜对,只有复杂逻辑才需要大模型介入。
另一个挑战是成本控制,大模型推理很贵。实际的做法是做智能路由,简单的补全请求走本地小模型,复杂的代码生成才调用云端大模型。判断复杂度可以用启发式规则,比如用户输入超过10行或者包含复杂的嵌套结构,就认为是复杂请求。这样能把API调用量降低60%以上,同时保证关键场景的效果。
进阶思考
代码模型没法像文本模型那样只看困惑度就行,最关键的指标是pass@k,也就是生成k个候选代码里至少有一个能通过测试用例的概率。工业界更看重的是首次采纳率,也就是模型补全的代码用户直接接受不做修改的比例,这个指标能直接反映模型在真实场景的可用性。还有个容易被忽略的指标是代码风格一致性,生成的代码要符合团队的命名规范、缩进习惯,否则即使逻辑正确也会被拒绝。现在很多团队开始用代码可维护性作为评估维度,不只看能不能跑通,还要看生成的代码是否容易理解、方便后续修改,这种长期质量的评估才是真正有价值的。

处理多语言有两种典型思路,一种是混合训练,把所有语言的代码放在一起学,这样可以迁移共性的编程思维,比如循环、条件判断这些基础结构在各语言都类似。但问题是不同语言的数据量差异很大,Python和Java的代码远多于Ruby或Kotlin,容易导致长尾语言效果很差。另一种是先训练一个通用代码基座模型,再针对每种语言做专门的adapter微调,这样既保留了跨语言的共性知识,又能针对特定语言的语法特点做优化。
代码模型最大的安全隐患是训练数据污染,GitHub上很多代码其实包含硬编码的密钥、内网地址这些敏感信息,模型如果学到了可能在生成时泄露出来。工业界的做法是在数据清洗阶段用正则表达式过滤掉API key、密码这类高危pattern,训练完成后还要做红队测试,故意用prompt诱导模型生成不安全的代码,检查是否有注入漏洞或权限绕过这类问题。像金融或医疗这种高敏感行业,代码模型生成的代码上线前必须经过人工审核和静态安全扫描,模型只是提效工具不是最终决策者。