精炼回答
大模型的上下文长度指的是模型在一次推理中能处理的最大token数量,这个限制来源于Transformer架构中自注意力机制的计算特性。
在自注意力计算时,每个token都要与上下文中所有其他token进行交互,计算复杂度是O(n²),这意味着序列长度翻倍,计算量会增长四倍。同时,模型需要在显存中存储所有token的KV缓存用于推理,这个内存占用也随序列长度线性增长。比如你用GPT-4处理一份10万字的合同,如果超出上下文窗口,模型就无法一次性读取全文进行分析,只能分段处理或采用检索增强方案。
为什么不能无限扩展?首先是硬件资源约束,更长的上下文需要成倍的显存和算力;其次是训练成本问题,模型在训练时使用特定位置编码,超出训练长度后位置信息会失效,需要重新训练或使用特殊技术如RoPE外推、ALiBi等来扩展;最后还有注意力稀释问题,上下文过长时模型可能难以准确捕捉关键信息。
现在行业在通过稀疏注意力、滑动窗口、分层记忆等技术突破这个限制,像Claude已经支持200K token,但计算成本和推理延迟依然是核心瓶颈,所以token限制本质上是架构设计和资源成本之间的权衡结果。
深入理解
从Token机制说起
面试时遇到这个问题,千万别一上来就扯Transformer细节,面试官最想先听到的是你对问题的理解框架。先开门见山说清楚什么是上下文长度——它就是模型一次能"看"多少内容的限制。这里要自然引出Token的概念,模型不是直接处理文字,而是把文本切成一个个Token,可以理解成词或者子词单元。比如"我爱AI"可能被切成3个Token,一个中文字一般是1到2个Token,所以GPT-4的128K上下文差不多能处理十几万汉字。
很多同学会说"Token就是词",这其实不够准确。模型采用Token而不是字符,主要是为了在词汇量和表达效率之间找平衡。如果用字符级别,英文就26个字母,看起来词表很小,但表达一个概念需要很多步,比如"understanding"需要处理13个字符;如果用完整单词,词表会爆炸到几十万,而且处理不了新词。Token化用了类似BPE这种子词算法,把常见词保留为整体,不常见的拆成子词单元。这样GPT-3.5的词表大概5万个Token,既能高效表达,又保证了泛化能力。比如"ChatGPT"这个词,可能被切成"Chat"和"GPT"两个Token,因为它们都是常见单元;而一个生僻的中文人名可能每个字都是一个Token。
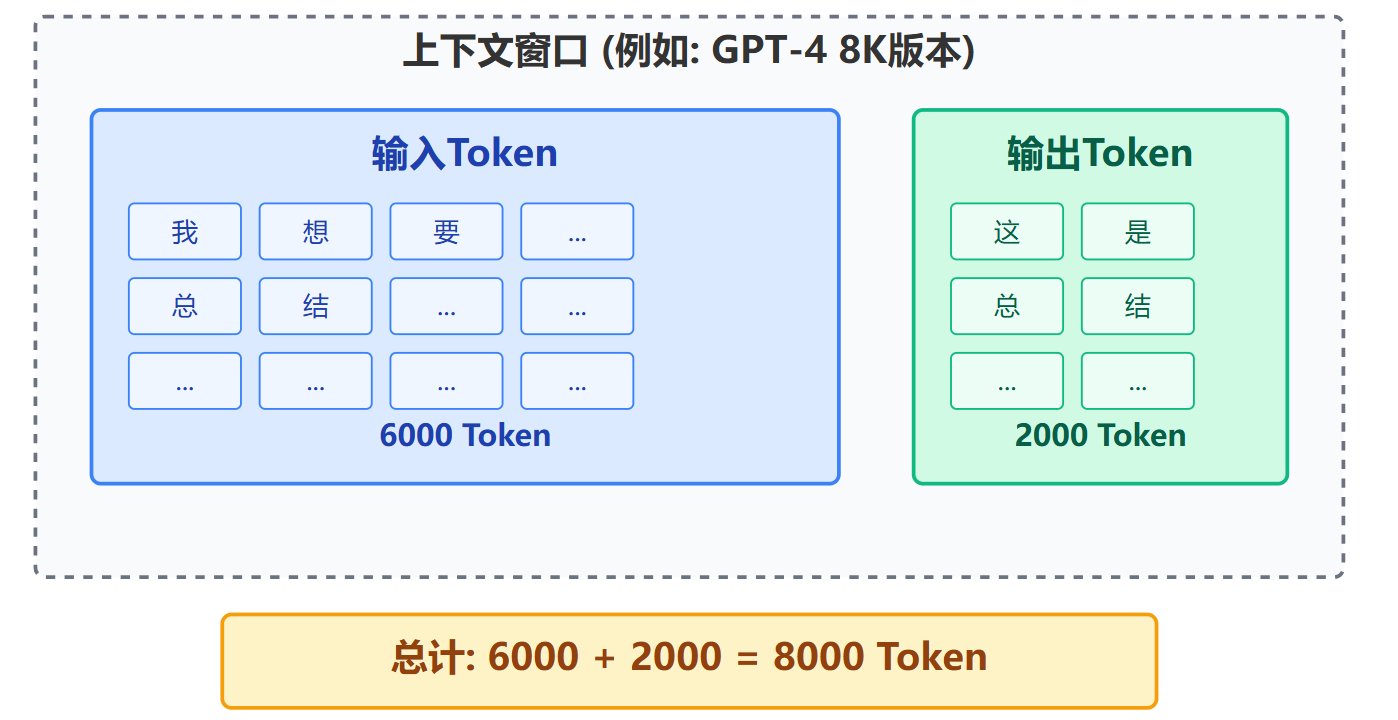
这里有个容易踩的坑要特别注意:上下文窗口是输入Token和输出Token的总和,不是只算输入。很多同学以为GPT-4的8K版本能输入8000个Token,其实如果你输入了6000个Token的文档,模型最多只能生成2000个Token的回复。假设你让模型总结一份产品需求文档,文档本身占了7000 Token,你设置最大生成2000 Token,这就超了8K的限制,实际使用时需要预留输出空间。
计算复杂度的本质约束
那为什么会有这个限制呢?核心原因主要来自两方面——计算和存储。Transformer的自注意力机制要让每个Token跟所有其他Token交互,序列越长计算量增长越快,这是平方级的复杂度;同时模型推理时需要在显存里缓存所有Token的中间状态,序列翻倍显存占用也翻倍。
自注意力机制的本质是让每个Token都能"看到"其他所有Token,并计算它们之间的关联强度。想象一个10个人的会议,每个人都要跟其他9个人握手,总共45次握手;如果会议有20个人,就需要190次握手,翻倍的人数导致握手次数增长了4倍多。这就是为什么说复杂度是O(n²)。具体来说,对于长度为n的序列,自注意力需要计算n×n的注意力矩阵,每个位置都要算一遍相似度。序列长度从1K到2K,计算量就从1M跳到4M量级。这还只是注意力得分计算,后面还有加权求和、多头处理,实际计算量更可观。

显存占用这块也要讲透。推理阶段有个重要的优化叫KV Cache,为了避免重复计算,模型会把每一层每个Token的Key和Value向量缓存下来。这个缓存大小跟序列长度成正比。拿GPT-3.5举例,96层Transformer,每层的K和V向量假设各4096维,用float16存储。如果处理4K长度的序列,光KV Cache就要占4096 × 2 × 96 × 4000 × 2字节,大概6GB显存。长度翻倍到8K,这部分显存直接翻倍到12GB。所以你会看到即使是A100这种80GB显存的卡,支持超长上下文时也得小心,batch size只能开很小,不然直接OOM。
位置编码的隐藏约束
很多人以为上下文长度只是算力问题,其实位置编码也是个硬约束。Transformer本身没有位置概念,靠位置编码告诉模型Token的先后关系。早期GPT用的绝对位置编码,训练时见过0到2048的位置,推理时突然给它位置3000,模型就懵了,没见过的位置编码会导致性能断崖式下降。后来出现RoPE这种相对位置编码,理论上可以外推,但外推到训练长度的2倍以上效果也会劣化。所以你看Claude 100K或者GPT-4 Turbo 128K,都是真金白银用长序列数据训练出来的,不是简单调个参数就能实现的。
对比不同模型时要说出差异背后的意义。GPT-3.5最早是4K上下文,后来推出16K版本;GPT-4刚发布时8K和32K两个版本,现在Turbo已经到128K;Claude走得更激进,直接上100K甚至200K。这个演进不只是技术炫耀,背后是应用场景的拓展。4K上下文大概3000英文单词,够处理常规对话;32K能装下一篇中等长度的论文;100K以上就可以分析整本书或者完整的代码仓库了。拿电商场景举例,4K可能只够分析一两个商品的评论,但如果要做整个品类的舆情分析,汇总几百条评论,就需要更长的上下文窗口。当然实际业务中可能会用RAG这种检索增强方案,不会真把所有评论都塞进去。
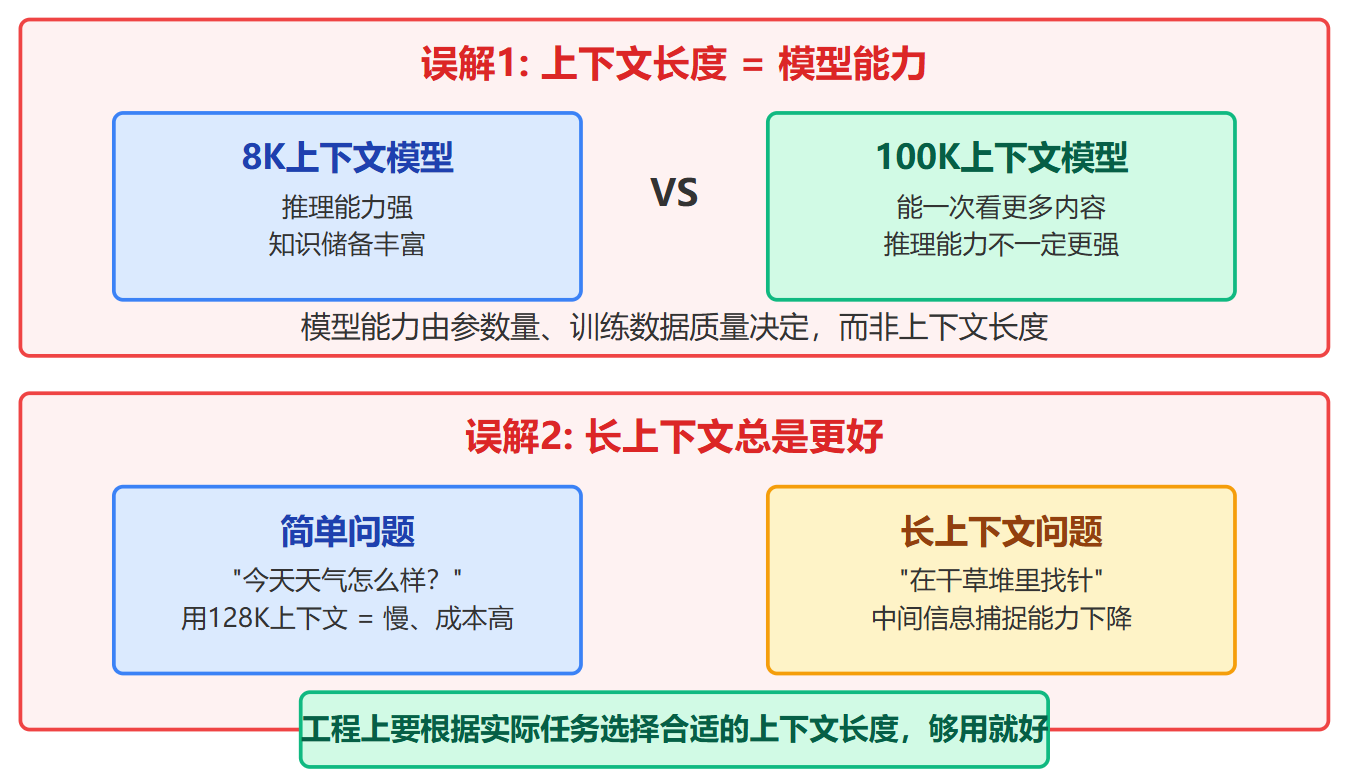
这里要澄清两个常见误解。上下文长度不等于模型能力。一个100K上下文的模型不一定比8K的模型更聪明,它只是能一次看更多内容,但推理能力、知识储备是由模型参数量、训练数据质量决定的。另外,长上下文也不是总是更好。假设你只是问"今天天气怎么样",用128K上下文的模型反而会更慢、成本更高,因为模型要维护更大的计算图和缓存空间,但这个简单问题根本用不到长上下文。而且研究发现,上下文太长时,模型对中间部分信息的捕捉能力会下降,出现"在干草堆里找针"的问题。所以工程上要根据实际任务选择合适的上下文长度,够用就好,不是越长越好。
实战应用与未来展望
实际项目中的处理策略
实际使用大模型API时,应该先估算Token消耗,避免超限或者浪费成本。这里要强调一个很多人忽略的点——不同模型的Token化方式不一样,中英文比例也不同。英文文本大概4个字符对应1个Token,所以1000个英文单词差不多1300到1500 Token;中文密度高一些,一个汉字通常1到2个Token,1000个汉字大概1500 Token左右。OpenAI提供了tiktoken这个Python库可以精确计算,我在对接API前一般会先用这个工具测一下样本数据,心里有个底。
比如GPT-4的8K版本,我会把可用上下文按7:3分配,最多用5600 Token输入,预留2400 Token给输出。如果是生成代码或者长文本摘要这种输出密集的任务,甚至会按6:4来预留,宁可保守一点也别让模型生成到一半被截断。
import tiktoken
# 使用tiktoken计算token数量
defestimate_tokens(text, model="gpt-4"):
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(text)
returnlen(tokens)
# 实际应用示例
product_reviews ="用户评论文本..."
token_count = estimate_tokens(product_reviews)
# 根据模型上下文限制决策
MAX_CONTEXT =8000
RESERVED_OUTPUT =2400
max_input = MAX_CONTEXT - RESERVED_OUTPUT
if token_count > max_input:
# 需要分块处理或采用RAG方案
print(f"内容过长({token_count} tokens),需要分块")
else:
# 可以直接调用
print(f"内容适中({token_count} tokens),直接处理")遇到超长文本,最简单的处理是分块。假设要分析一份2万Token的用户调研报告,可以按主题或段落切成5个4000 Token的块,分别调用模型总结,最后再汇总这些总结。这种方法的问题是丢失了跨块的上下文关联,比如第2块提到的概念可能在第1块已经解释过,分开处理就断了。所以工程上会用滑动窗口,每块重叠一部分内容,比如1000 Token的overlap,这样能保持上下文的连贯性。
如果文本量特别大,比如要从100篇商品评论中找出质量问题,可以用RAG的思路。先把评论切块做embedding,存到向量库;用户问"这款手机有什么质量问题"时,先用这个问题检索最相关的10到20条评论,再把这些相关内容喂给大模型分析。原本10万Token的评论全塞进去肯定爆了,检索后可能只需要3000 Token,完全在窗口范围内。
成本控制的实战经验
大模型API按Token计费,上下文管理直接影响成本。GPT-4的定价大概是输入0.03美元/1K Token,输出0.06美元/1K Token。如果做一个客服对话系统,每轮对话都把完整历史带上,10轮对话后上下文可能累积到8000 Token,单次调用成本就是0.24美元;但如果只保留最近3轮关键对话,压缩到2000 Token,成本降到0.06美元,差了4倍。实际项目中会做上下文管理,比如保留开场的系统设定(200 Token)、最近3轮对话(1500 Token)、用户明确提到的关键信息(300 Token),总共控制在2000 Token以内,既保证对话连贯性又控制了成本。
场景化应用这里最能展示理解深度。客服对话场景下,4K到8K上下文基本够用,因为单次对话很少超过10轮,关键是上下文管理策略,要判断哪些历史信息该保留。但文档分析就不一样了,比如分析一份几十页的产品规格书,可能需要32K甚至更长的上下文,才能一次性把完整信息喂进去,避免分块后丢失关联。代码生成很特殊,一个复杂函数可能就几百Token,但如果要重构整个模块,需要看到相关的十几个函数和接口定义,这时候16K到32K上下文就很关键了。不过代码密度高,同样的Token数能承载的代码量比自然语言多。
技术演进与未来方向
任何技术选型都不是完美的,Transformer选择了全局自注意力获得强大的语义理解能力,代价就是平方级的计算复杂度。比如RNN和LSTM的对比,它们处理长序列时计算是线性的,但信息传递容易衰减;Transformer反过来,信息流动没问题,但计算成本限制了长度。这其实是个经典的时间-空间权衡问题。
目前有几个主流的突破方向。稀疏注意力不是让每个Token都跟所有Token交互,而是设计某种模式,比如局部窗口加全局landmark,把O(n²)降到O(n√n)甚至O(n)。像Longformer、BigBird这些模型就是这个思路,已经能支持几万Token的上下文了。线性注意力机制,像RWKV这种模型用了类似RNN的递归结构,但保留了并行训练的优势,理论上可以处理无限长的序列。不过这些方案都有代价——要么牺牲了一定的表达能力,要么在某些任务上效果不如标准Transformer。
还有一个方向是从架构层面重新思考,就是检索增强生成。与其让模型死记硬背所有信息,不如给它配个外部记忆库,需要的时候再检索进来。这样模型本身的上下文窗口可以不用太大,通过检索把相关知识动态注入。现在很多企业级应用都在用这个思路,因为它不仅能突破长度限制,还能让模型获取实时更新的知识,不用频繁重训练。我个人觉得未来可能不是单纯追求更长的上下文窗口,而是混合方案——模型有个合理的窗口处理核心推理,外挂检索系统提供扩展知识,两者配合起来既高效又灵活。
从架构演进的角度看,Transformer这种统一架构处理所有任务的思路很优雅,但现在大家发现没有银弹——对话、检索、推理可能需要不同的注意力机制和上下文策略。所以下一代模型可能会朝模块化、可组合的方向走,针对不同任务动态调整计算图。当然这只是我的个人理解,技术演进总是超出预期。关键是理解在限制条件下做选择的能力,技术没有完美方案,工程师的价值就是权衡利弊、找到当下最优解。