精炼回答
AST(抽象语法树)是源代码的树状结构化表示,它剥离了语法细节(如括号、分号),只保留程序的逻辑结构。在代码理解中,AST让我们能够精确地分析代码语义而非文本,比如识别函数调用关系、变量作用域、代码复杂度等,这是IDE代码提示、重构工具、静态分析、代码转译的基础。
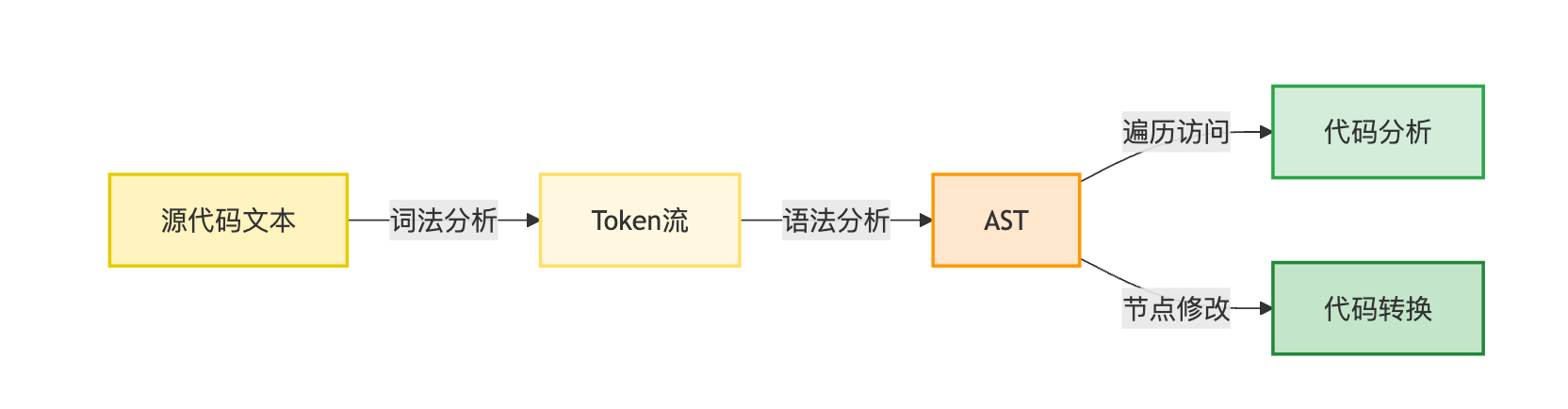
解析AST通常分两步:词法分析和语法分析。词法分析器(Lexer)把源码拆成token流,比如把const a = 1拆成['const', 'a', '=', '1'];语法分析器(Parser)根据语言语法规则将token组装成树结构。实际开发中,你不需要从零实现,直接用现成的解析器库就行——JavaScript用@babel/parser或acorn,Python用ast标准库,Java用JavaParser。
举个实际场景:你要统计项目中所有未使用的import语句。拿到AST后,遍历所有ImportDeclaration节点收集导入的标识符,再遍历所有Identifier节点检查引用情况,对比两者就能找出未使用的导入。如果用正则匹配文本,会被字符串中的假代码、注释干扰,而AST直接给你准确的代码结构。解析后你可以用visitor模式遍历节点,针对不同节点类型执行不同逻辑,这就是各种代码分析工具的核心原理。
扩展分析
AST的本质与价值
面试时展开讲AST,最怕掉进纯理论陷阱。要把AST的本质说透,你可以这样切入:AST是源代码的树形中间表示,它把代码的语法结构抽象出来,去掉那些对理解程序逻辑没用的符号。这里要强调"中间表示"这个词,说明AST处在源代码和机器执行之间,既不是纯文本,也不是字节码,而是一种方便分析的结构化形式。
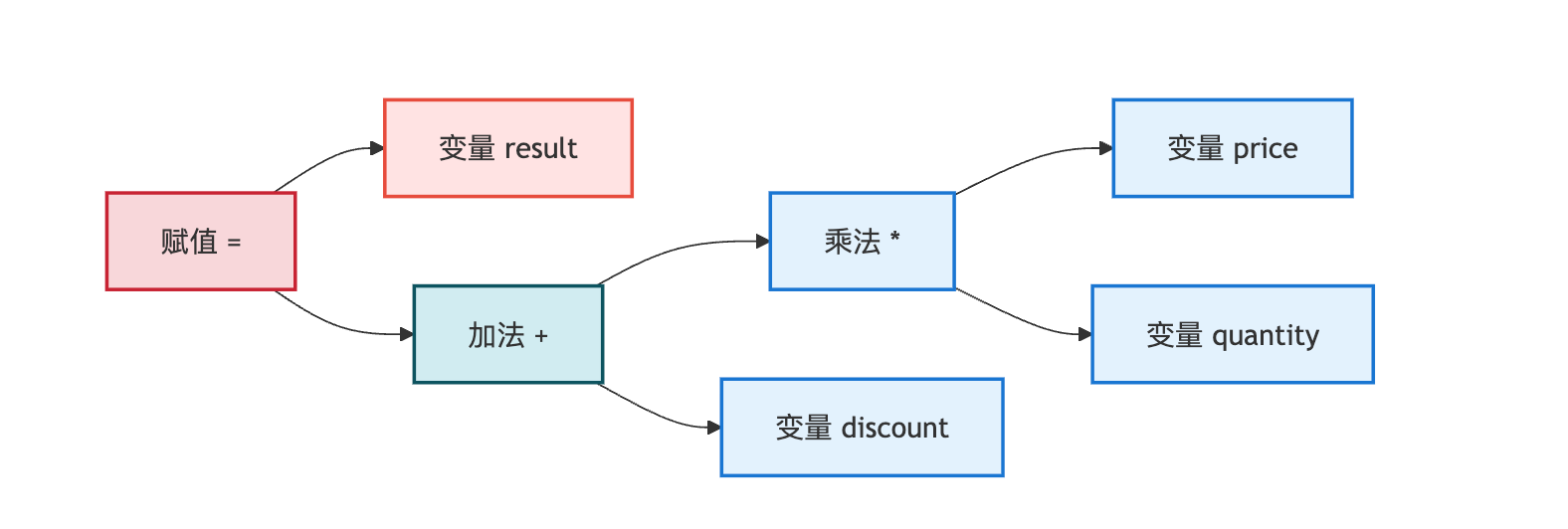
假设有这样一行代码:result = (price * quantity) + discount。AST会把它解析成一个树形结构,根节点是赋值操作,左子树是变量result,右子树是加法操作,加法操作又分解成乘法和discount变量。那些括号、空格、分号在AST里全都消失了,因为树的结构本身就已经表达了优先级和层次关系。这个设计的初衷很明确——为了后续分析的高效,而不是为了还原源代码的每个字符。
有个容易混淆的概念需要澄清:AST和Parse Tree有什么区别?Parse Tree是完全按照文法推导生成的,每个语法规则都对应一个节点,信息很冗余。AST是抽象过的,只保留语义相关的节点,比如括号这种纯粹为了消除歧义的符号就不会出现在AST里。这个对比能证明你理解AST设计的初衷。
说清楚代码理解为什么离不开AST,核心点是:文本匹配只能做表面分析,AST能让我们理解代码的语义结构。用一个反例来说明文本匹配的局限性:假设你要找出所有调用某个函数的地方,用正则搜索函数名会匹配到注释里的、字符串里的、甚至变量名恰好相同的位置,全是误报。但如果用AST,你遍历所有FunctionCall节点,检查callee属性是否匹配目标函数名,得到的结果是100%准确的。
AST让很多高级分析成为可能。IDE的代码补全需要AST来判断当前光标在哪个作用域,才能提示正确的变量;重构工具重命名函数时,要通过AST找到所有调用点,确保改名不会影响其他同名标识符;静态分析工具检查空指针异常,需要沿着AST的数据流追踪变量状态。这些场景的共同点是,它们都需要理解代码的语法关系和作用域规则,这是纯文本正则根本做不到的。
2025年大模型在代码生成上已经很成熟了,但生成的代码能不能真正运行,还得靠AST来保证。传统的代码分析把代码当成token序列喂给模型,但这样会丢失结构信息。如果先解析成AST,然后对树做遍历生成路径序列,或者直接用Graph Neural Network编码AST的结构,模型就能学到更深层的语义特征。这种方法在代码搜索、克隆检测、漏洞挖掘上都有应用。
现在的AI编程助手不只是补全代码片段,还能根据需求描述生成完整函数。但生成的代码经常缺依赖、变量名冲突、类型不匹配。这时候就需要解析生成代码的AST,和项目已有代码的AST做合并检查:自动添加缺失的import语句、根据上下文推断变量类型、检测命名冲突自动重命名。ESLint的自动修复功能就是这个原理,它不是简单的文本替换,而是修改AST节点后重新生成代码。
漏洞检测也是个有说服力的例子。假设要检测SQL注入风险,传统方式是搜索字符串拼接的代码模式,但容易漏报。如果基于AST分析,可以追踪用户输入变量的数据流,检查它是否未经过滤就拼接到SQL语句里,这种污点分析只有通过AST才能实现。
AST的每个节点都有type属性标识节点类型,比如IfStatement、BinaryExpression,然后有特定的子属性存储语义信息。举个实际的节点结构例子:
// 代码: const sum = a + b
{
type:"VariableDeclaration",
kind:"const",
declarations:[{
type:"VariableDeclarator",
id:{type:"Identifier",name:"sum"},
init:{
type:"BinaryExpression",
operator:"+",
left:{type:"Identifier",name:"a"},
right:{type:"Identifier",name:"b"}
}
}]
}
这个嵌套结构的逻辑是:声明节点里有声明符列表,声明符包含标识符和初始值,初始值是个二元表达式,表达式又包含操作符和左右操作数。这种层层拆解能证明你理解AST的递归性。
遍历方式是核心操作。拿到AST后,写一个访问器对象,为每种节点类型定义处理函数,然后递归遍历整棵树,访问到对应节点时调用相应的处理逻辑。像Babel的插件系统就是这个机制,你写个visitor.FunctionDeclaration方法就能拦截所有函数声明。深度优先遍历是最常用的策略,但不同遍历顺序有不同适用场景:计算表达式的值用后序遍历,因为要先算出子表达式;做依赖分析用前序遍历,先处理import语句再处理代码体。
最后用一个对比收尾:文本分析只能看到代码的表面形式,遇到宏定义、模板生成、混淆代码就完全失效了。AST分析的是代码的逻辑结构,不管代码怎么格式化、怎么重命名,只要逻辑不变,AST的结构就是稳定的。举个跨语言转译的例子能更直观:现在很多项目需要把TypeScript转成JavaScript,或者把JSX转成纯JS。这个过程不是字符串替换,而是把源代码解析成AST,修改特定类型的节点(比如把TypeScript的类型标注节点删掉,把JSX节点转成createElement调用),最后从修改后的AST重新生成代码。Babel、TypeScript Compiler都是这么工作的。
实战操作与工程应用
工程上我们不会从零写Parser,都是用成熟的解析库。Python开发者最省心,标准库自带ast模块,不用装任何依赖就能解析Python代码。Java的话JavaParser是主流选择,Maven加个依赖就能用,它支持Java 8到17的所有语法特性。JavaScript生态更丰富,Babel的@babel/parser功能最全,支持各种实验性语法,Acorn轻量快速适合简单场景。如果跨语言的通用方案,可以用Tree-sitter,它是GitHub开发的增量解析器,支持几十种语言,VSCode的语法高亮就用它。
解析分两个阶段,先是词法分析把源代码切成token流,比如把int sum = 10;切成['int', 'sum', '=', '10', ';']这样的序列,每个token带上类型标签,像关键字、标识符、运算符。然后语法分析器按照语言的文法规则把token流组装成树,这个树就是AST,节点类型对应语法结构,比如赋值语句、函数调用。
来个完整的Java代码演示,假设要统计代码里所有方法的参数个数:
importcom.github.javaparser.JavaParser;
importcom.github.javaparser.ast.CompilationUnit;
importcom.github.javaparser.ast.body.MethodDeclaration;
importcom.github.javaparser.ast.visitor.VoidVisitorAdapter;
publicclassMethodAnalyzer{
publicstaticvoidmain(String[] args){
String code ="""
public class OrderService {
public Order createOrder(Long userId, Long productId, Integer quantity) {
return orderRepository.save(userId, productId, quantity);
}
public void cancelOrder(Long orderId) {
orderRepository.delete(orderId);
}
public List<Order> getUserOrders(Long userId, Integer page, Integer size) {
return orderRepository.findByUserId(userId, page, size);
}
}
""";
// 解析代码生成AST
CompilationUnit cu =newJavaParser().parse(code).getResult().get();
// 使用Visitor模式遍历AST
cu.accept(newVoidVisitorAdapter<Void>(){
@Override
publicvoidvisit(MethodDeclaration md,Void arg){
String methodName = md.getNameAsString();
int paramCount = md.getParameters().size();
System.out.printf("方法 %s 有 %d 个参数%n", methodName, paramCount);
super.visit(md, arg);
}
},null);
}
}
这个例子完整展示了解析-遍历-分析的流程。用VoidVisitorAdapter写访问器,重写visit方法处理方法声明节点。getNameAsString拿方法名,getParameters拿参数列表。运行这段代码会输出:
方法 createOrder 有 3 个参数
方法 cancelOrder 有 1 个参数
方法 getUserOrders 有 3 个参数AST在代码工程领域有几个不可替代的应用。静态分析是最常见的场景,比如检测未使用的变量、循环复杂度超标、潜在的空指针异常。这些工具都要先构建AST,然后做数据流分析或控制流分析。自动重构也离不开AST,IDE的"提取方法"功能要先解析选中代码块的AST,检查变量依赖关系,然后生成新的函数定义并修改调用点,最后重新生成代码。
代码搜索是个更实用的例子。电商项目代码量很大,如果要找所有调用某个废弃API的地方,用文本搜索会漏掉继承关系的调用、反射调用,用AST分析能精确定位。具体操作是遍历所有方法调用节点,解析调用链,匹配目标方法签名。比如我们要找所有调用OrderService.calculatePrice的地方:
cu.accept(newVoidVisitorAdapter<Void>(){
@Override
publicvoidvisit(MethodCallExpr mce,Void arg){
if(mce.getNameAsString().equals("calculatePrice")){
mce.getScope().ifPresent(scope ->{
if(scope.toString().contains("OrderService")){
System.out.println("找到调用: "+ mce +" 在第 "+
mce.getBegin().get().line +" 行");
}
});
}
super.visit(mce, arg);
}
},null);
克隆检测是另一个有技术深度的场景。传统的代码查重基于文本相似度,但改个变量名就能绕过。基于AST的检测会先做归一化,把所有变量名替换成统一的占位符,然后比较两段代码的AST结构。如果树的形状和节点类型序列一致,就说明逻辑相同。
现在大模型生成代码很火,但生成的代码质量不稳定,AST能帮我们做后处理。比如GitHub Copilot生成的代码片段可能缺import语句,你可以解析生成代码的AST,提取所有未定义的标识符,然后在项目的已有代码中搜索对应的定义,自动补全import。这个过程需要同时解析生成代码和项目代码的AST,做符号表匹配。
结构化提示是另一个前沿应用。传统方式是把代码直接喂给大模型,但代码的结构信息会在Tokenization时丢失。现在有些方案先把代码解析成AST,然后按照树的层次生成结构化描述,比如"这是一个类,包含三个方法,第一个方法有两个参数",这种描述能帮助模型更好地理解代码逻辑。
性能优化是大规模应用的关键点。AST解析很耗时,大型项目要做好缓存策略。具体来讲就是解析完一个文件后把AST序列化存起来,只有文件修改时才重新解析。增量解析更高级,Tree-sitter支持这个特性,修改代码时只重新解析变化的部分,其他节点复用旧的AST。VSCode能做到实时语法检查就是因为用了增量解析,否则每次敲键盘都全量解析代码,编辑器会卡死。
深度思考与技术趋势
面试官抛出AST这道题,表面上考的是编译原理知识,实际上在测试你对代码理解技术栈的掌握深度。他们想知道你是不是真的能把这个技术用起来解决工程问题。能把AST和实际业务场景结合起来说清楚,立刻就能把你和那些纸上谈兵的候选人区分开。不需要讲太复杂的系统,哪怕只是个几百行的小工具,只要能说清楚为什么选AST、怎么解决的具体问题、遇到过什么坑,就足以证明你有实战经验。
有些候选人会提到做过代码规范检查插件,自动扫描项目中不符合规范的写法并给出修改建议。比如电商项目中要求所有金额字段必须用BigDecimal类型,不允许用double。这种检查就可以通过遍历AST,找到所有字段声明节点,检查字段名包含"price"、"amount"等关键词的是否使用了正确的类型。这种场景特别能体现AST的实用性。
面试官很可能会追问AST和其他程序表示形式的关系,比如控制流图CFG或者数据流图DFG。你要能说清楚它们的区别和配合方式:AST关注语法结构,CFG关注执行路径,DFG关注数据依赖。实际分析时往往需要先解析AST,再基于它构建CFG和DFG做更深层的分析。AST是基础表示,很多高级分析都要先拿到AST再做转换。这种分层理解能让面试官觉得你不是孤立地看技术点,而是理解整个技术体系。
如果面试官是架构师或者技术leader,可能会问到跨语言的代码理解方案。这时候可以提到统一AST表示的思路,比如把Java、Python、JavaScript的AST都转成一个通用的中间格式,这样同一套分析逻辑就能处理多种语言。Tree-sitter就是这个方向的代表,它定义了一套语言无关的AST schema。如果你参与过多语言项目的代码分析工具开发,这会是个很好的加分点。
AI代码生成工具遍地开花的今天,AST在代码大模型中有两个重要作用。一是结构化增强,把AST的结构信息编码进模型输入,帮助模型理解代码的层次关系和语义结构,提升生成质量。二是后处理验证,生成代码后用AST做语法检查和依赖补全,保证代码能真正跑起来。这两个方向都是2025年的研究热点,提到这些能展现你对前沿趋势的关注。
最后要做好被追问工程细节的准备。大型项目中AST解析的性能瓶颈怎么解决?可以提前准备一些优化策略:并行解析多个文件、缓存AST避免重复解析、用增量更新减少计算量。如果能结合具体数字说"我们项目有十万行代码,全量解析要30秒,加了缓存后秒级响应",这种量化的描述会让面试官对你的经验深度有更清晰的判断。面试中光讲理论面试官不会买账,他们更想看到你真的会用AST解决问题,这才是把你和其他候选人区分开的关键。