GraphRAG是将知识图谱与检索增强生成相结合的技术方案。传统RAG通过向量相似度检索文档片段,但这种方式容易丢失实体间的关系信息。GraphRAG则先将文档构建成知识图谱,把实体作为节点、关系作为边存储,检索时不仅能找到相关实体,还能沿着图结构获取多跳关系和上下文信息。
知识图谱对RAG的增强主要体现在三个方面。首先是关系推理能力,比如查询"某药物的副作用"时,可以通过图谱遍历药物-成分-副作用的路径,获得比单纯文本检索更完整的答案。其次是消除歧义,当检索到"苹果"这个实体时,图谱中的关系边能明确区分是水果还是公司。最后是知识一致性,图谱的结构化特性避免了向量检索可能带来的矛盾信息。
如果你在面试中遇到这个问题,第一句话非常关键。建议直接点明本质:"GraphRAG是在RAG的检索环节引入知识图谱,让系统不仅能找到相关内容,还能理解内容之间的关联关系。"这句话能立即让面试官知道你理解了这个技术的核心定位。接下来可以用对比的方式回答:传统RAG就像用搜索引擎找资料,找到的都是独立的文档片段,系统并不知道这些片段之间有什么联系;而GraphRAG会先把知识整理成一张关系网络,检索的时候能顺着这张网找到更多相关信息。
说到价值点时,别急着列举一堆技术术语。面试官更关心的是"解决了什么实际问题"。你可以举个直观的例子:用户问"这款手机适合学生吗",传统RAG可能只返回产品参数,但GraphRAG能沿着"手机-价格区间-目标人群"这条路径,结合"学生-预算敏感"的关系,给出更贴合需求的回答。实际应用中,金融领域用GraphRAG分析企业关联关系,医疗场景用它构建疾病-症状-药物的知识网络来辅助诊断。技术实现上通常采用混合架构:向量检索负责召回候选节点,图遍历算法扩展相关子图,最后将子图序列化后送入LLM生成答案。这种方式让RAG系统从"检索相似文本"进化到"理解知识关联"。
扩展分析
传统RAG的根本困境
从传统RAG的痛点切入最容易让人产生共鸣。传统RAG的工作流程其实很直接:用户输入问题后,系统会把问题编码成向量,然后在文档向量库里找最相似的几段文本,最后把这些文本拼接起来喂给大模型生成答案。这个过程看起来没问题,但实际使用中会遇到一个根本性困境——向量相似度只能代表"语义接近",却无法表达"知识关联"。
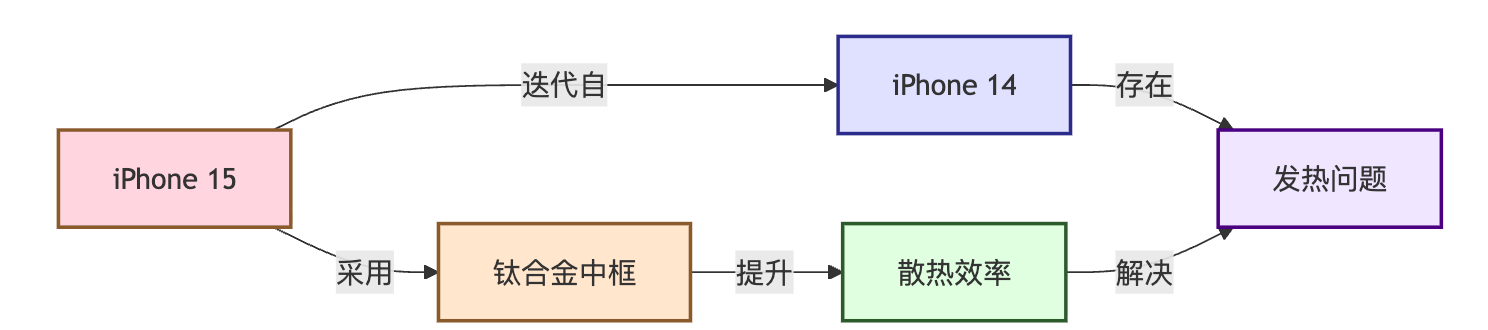
举个具体场景会更有说服力:用户问"iPhone 15的散热方案是否解决了前代发热问题",传统RAG可能会检索到一段介绍iPhone 15散热设计的文本,和另一段提到iPhone 14发热的用户评论,但系统并不知道这两个产品之间是迭代关系,也不清楚散热方案和发热问题之间的因果联系。检索回来的内容就像散落的拼图碎片,缺少把它们组织起来的框架。
GraphRAG的核心设计思路是在文本进入系统之前,先做一次知识抽取和结构化。具体来说,会通过NER(命名实体识别)和关系抽取技术,把文档中的关键信息转化成"实体-关系-实体"的三元组。比如从"iPhone 15采用钛合金中框提升散热效率"这句话中,可以抽取出【iPhone 15】-(采用)->【钛合金中框】和【钛合金中框】-(提升)->【散热效率】两条关系。这些三元组会被存储到图数据库中,形成一张可以遍历的知识网络。
图结构检索和向量检索有什么本质区别?这是个关键问题。向量检索本质上是在做"相似度匹配",它会把所有文本都压缩成几百维的数字向量,通过计算向量间的距离来判断相关性。这种方式的问题在于,语义相近的内容不一定是逻辑相关的内容。比如"苹果手机销量下滑"和"华为手机销量上涨"这两句话的向量可能很接近,因为它们都在讨论手机销量,但如果用户问的是"苹果公司的业务风险",后者其实是更有价值的关联信息。
图结构检索则完全不同,它是在做**"路径查找"**。当检索到"苹果公司"这个节点后,系统会沿着图谱中定义的边去遍历,比如顺着【竞争对手】这条边找到华为,再顺着【市场份额】关系找到销量数据。这种检索方式遵循的是人类的认知逻辑,而不是统计学上的相似性。
多跳推理的实现原理
多跳推理能力的实现原理是GraphRAG最打动人的地方。可以用一个医疗场景来说明:假设用户问"糖尿病患者能否服用布洛芬",传统RAG可能检索到糖尿病的症状说明和布洛芬的药品说明书,但很难建立两者的关联。GraphRAG会这样工作:首先找到【糖尿病】这个疾病节点,沿着【常见并发症】关系找到【肾功能不全】,再从【布洛芬】节点出发,沿着【禁忌症】关系找到【肾功能损伤】,最后通过图遍历算法发现这两条路径在"肾脏相关风险"这个概念上产生了交集。这就是所谓的多跳推理——系统不是直接检索答案,而是沿着知识图谱走了"糖尿病→并发症→肾脏→禁忌症→布洛芬"这样一条推理路径。
知识图谱增强RAG的核心优势要避免空洞的理论描述。关系感知能力是第一个优势,图谱中显式存储的边让系统能理解实体之间不仅仅是"相关",还有具体的关系类型——是因果关系、包含关系还是对立关系。这种区分在生成答案时非常关键。消歧能力是第二个优势,当检索到"苹果"这个词时,传统向量检索可能会把水果和科技公司的内容混在一起,但在知识图谱中,【苹果公司】节点会连接着【科技】【股票】【产品】这些边,而【苹果水果】节点连接的是【食品】【营养成分】这些边,系统可以根据查询上下文选择正确的子图。推理可解释性是第三个优势,当系统给出答案时,可以同步返回它在图谱上走过的路径,这让生成结果不再是黑盒。
GraphRAG解决的典型问题场景要具体到问题特征。它特别适合需要理解间接关联的场景,比如风控系统要判断一家企业的隐藏关联方,需要通过股权关系、高管任职、资金往来等多层关系网络去追溯。它也适合需要整合多源异构信息的场景,比如智能客服要回答"这款手机和上一代比有什么升级",需要整合产品知识库、用户评论、技术白皮书中的分散信息,而这些信息之间的关联关系正是知识图谱擅长表达的。
实践落地
场景适配性判断
当你觉得GraphRAG应该怎么落地时,千万别急着说"选个图数据库、抽取实体、建立关系"这种教科书式流程。真正重要的是识别什么场景适合用这个技术,以及对实施难度的预判能力。
从场景适配性入手是最稳妥的策略。可以先说一个判断标准:如果业务问题需要理解多层关联才能给出答案,那GraphRAG的价值就会比较明显。比如金融风控场景,当要判断一笔贷款申请的风险时,不能只看申请人本身的征信记录,还要看他的关联企业是否有异常、股东之间是否存在交叉担保、资金流向是否涉及高风险行业。这种需要"顺藤摸瓜"的分析逻辑,正是图结构擅长表达的。传统RAG在这种场景下会遇到困境:即使检索到了"申请人担任A公司法人"和"A公司有逾期记录"这两段信息,系统也很难自动建立起"申请人风险因A公司牵连"的推理链条。而在知识图谱中,这种关联路径是显式存储的,系统可以通过图遍历直接找到。
电商场景中的商品关系推理也是个很好的例子。当用户问"买了这台相机还需要配什么",GraphRAG能沿着商品图谱找到"相机-兼容-镜头型号"、"相机-常用配件-存储卡规格"、"相机-适用场景-三脚架类型"这些关系,给出的推荐会比单纯基于"购买相机的用户还买了"这种协同过滤更有解释性。
技术实现的关键决策
谈到技术实现时要展现对工程权衡的认知。知识抽取是第一步,这里有两种思路:一种是基于规则的方法,适合领域知识结构稳定的场景,比如医疗领域的疾病-症状关系,可以通过正则表达式或依存句法分析来抽取;另一种是基于模型的方法,用预训练的NER模型识别实体,用关系分类模型判断实体间的关系类型。实际项目中通常会混用,先用规则抽取高置信度的核心关系,再用模型补充长尾部分,这样既保证了准确率又控制了人工标注成本。
图数据库的选择是个容易展现技术视野的点。Neo4j的优势在于对复杂图遍历的性能优化,它的Cypher查询语言对多跳路径查询的表达很直观,社区生态也成熟,但如果数据规模到了千万级节点且需要频繁更新,可能要考虑分布式方案,比如JanusGraph或者ArangoDB这种支持水平扩展的图数据库。虽然理论上可以用邻接表的方式在MySQL里存储图数据,但当查询"找出3度以内的所有关联实体"这种需求时,需要多次自连接操作,SQL会写得很复杂且性能很差,图数据库的原生图存储引擎在这方面有数量级的性能优势。
检索策略的设计是最能体现工程能力的部分。GraphRAG的检索不是简单的图遍历,而是需要设计一套混合策略。一个典型的实现思路是:首先用向量检索做粗召回,从知识图谱中找到与查询最相关的TopK个节点作为起点,然后以这些节点为中心,通过广度优先或深度优先遍历扩展出相关子图。这里有个关键的工程问题是**"扩展多大的子图合适"**,如果子图太小可能丢失关键信息,太大又会引入噪声且影响LLM的处理效率。通常会设置跳数限制(比如2-3跳)和节点数上限(比如50个节点),同时根据边的类型设置不同的遍历优先级,比如因果关系的边权重高于一般关联关系。
publicclassGraphRAGRetriever{
privateVectorSearchEngine vectorSearch;
privateGraphDatabase graphDB;
publicRetrievalResultretrieve(String query,int topK){
// 第一阶段:向量召回起始节点
List<GraphNode> startNodes = vectorSearch.search(
embedQuery(query), topK
);
// 第二阶段:从起始节点扩展子图
SubGraph resultGraph =newSubGraph();
for(GraphNode node : startNodes){
SubGraph relatedSubGraph = graphDB.traverse(
TraverseConfig.builder()
.startNode(node)
.maxDepth(2)
.maxNodes(50)
.edgeFilter(e ->
e.getType().equals("因果")||
e.getType().equals("包含")||
e.getType().equals("对立")
)
.build()
);
resultGraph.merge(relatedSubGraph);
}
// 第三阶段:子图序列化
String serializedGraph =serializeGraph(resultGraph);
returnnewRetrievalResult(resultGraph, serializedGraph);
}
privateStringserializeGraph(SubGraph graph){
StringBuilder sb =newStringBuilder();
// 转换为自然语言描述
for(Triple triple : graph.getTriples()){
sb.append(String.format("%s %s %s。\n",
triple.getSubject(),
triple.getPredicate(),
triple.getObject()
));
}
return sb.toString();
}
}子图序列化也是个值得一提的细节。当从图数据库中检索出子图后,需要把图结构转换成LLM能理解的文本格式。有两种常见做法:一种是把子图转换成自然语言描述,比如"iPhone 15采用钛合金中框,钛合金中框可以提升散热效率";另一种是保留结构化的三元组格式,在prompt中告诉LLM如何解读这些三元组。各有优劣,前者更接近LLM的训练分布但丢失了部分结构信息,后者保留了完整语义但需要LLM有较好的结构化理解能力。
混合架构的设计
GraphRAG是不是要完全替代向量检索?实际工程中通常是互补使用。向量检索的优势在于能处理模糊查询和语义泛化,比如用户问"性价比高的拍照手机",这种描述性需求很难直接映射到图谱的实体节点上,这时候向量检索能快速找到候选范围。而图谱检索的价值在于精准的关系推理,当用户问"这款手机的处理器和去年旗舰机是同款吗",就需要在图谱中查找产品-芯片-型号这条确定性路径。
可以描述一个两阶段架构:第一阶段用向量检索做语义召回,找到可能相关的实体集合;第二阶段以这些实体为起点,在图谱中扩展子图获取关系上下文;最后把向量检索的文本片段和图谱的结构化知识一起送给LLM做融合生成。

最后要坦诚地谈成本和复杂度。知识图谱的构建成本是最大的挑战,需要持续的知识抽取、质量校验和图谱更新。如果是从零开始建图谱,人工标注和规则编写的工作量会很大。可以考虑从垂直领域的小规模图谱开始,比如先构建核心品类的商品知识图谱,验证效果后再逐步扩展。图数据库的运维也比传统数据库复杂,需要团队有图算法和分布式系统的经验。
扩展思考
当面试官问到GraphRAG这个话题时,他真正想考察的不是你能不能背出这个概念,而是你对前沿技术的敏感度和判断力。这道题的深层意图在于了解你是不是真的在关注AI技术的演进方向,能不能识别出一项技术什么时候该用、什么时候不该用。
面试官最常见的一个追问是**"GraphRAG的性能瓶颈在哪里"**,这个问题其实是在考察你有没有工程实践的意识。可以这样回答:图谱构建阶段的知识抽取速度是第一个瓶颈,尤其是用深度学习模型做实体识别和关系抽取时,处理海量文档的时间成本会很高。检索阶段的图遍历性能是第二个瓶颈,当子图规模达到几千个节点时,多跳查询的计算复杂度会指数级增长。可以补充实践思路:我们可以通过预计算常见路径、对热点子图做缓存、用近似算法代替精确遍历这些方式来优化。
另一个高频追问是**"如何评估是否需要引入GraphRAG"**,这是在考察你的技术选型判断力。千万别说"GraphRAG很先进所以应该用",而要说出评估标准。首先要看业务查询是否需要多跳推理,如果大部分问题都能通过一次向量检索解决,引入图谱的收益可能不明显。其次要看知识结构是否稳定,如果业务规则每周都在变,维护图谱的成本会很高。最后要看团队能力储备,如果团队没有图算法和知识工程的经验,上手难度会成为阻碍。
如果你有过相关项目经历,这是最好的展示机会。其实不一定要做过GraphRAG才能回答好,关键是展现你对RAG技术的思考深度。比如你做过一个问答系统的项目,哪怕用的是传统RAG方案,也可以说:在项目中我发现当用户问一些需要关联多个知识点的问题时,向量检索经常会遗漏关键信息,当时我们是通过人工规则补充的,但如果用GraphRAG的思路,可以把这些知识点的关联关系显式建模出来。这种表达方式既展示了你的项目经验,又体现了你在思考技术演进方向。
谈到AI和知识工程的融合趋势时,要展现出你对技术发展脉络的理解。大模型的出现让我们有了强大的语义理解能力,但纯端到端的黑盒模型在某些场景下缺少可控性和可解释性,这时候把符号化的知识图谱和神经网络结合起来,就成了一个很自然的演进方向。GraphRAG其实代表了一种更广泛的趋势,就是用结构化知识去引导和约束大模型的生成过程,让AI系统既有灵活性又有可靠性。这种回答能让面试官感受到你不只是在学一个个孤立的技术点,而是在理解技术演进的内在逻辑。