精炼回答
角色设定确实有用,但效果取决于具体场景和模型能力。这不是玄学,而是有明确技术原理支撑的机制。
从技术层面看,"You are..." 这类指令会影响模型的上下文理解和采样分布。模型在训练时见过大量"角色-行为"的对应模式,比如"你是Python专家"会激活更多与Python相关的token权重,让模型倾向于使用技术术语、代码示例等专业表达方式。本质上是通过角色描述来调整模型输出的概率空间,引导它从训练数据中调取对应的表达模式。
实际应用中,明确的角色设定在某些任务上效果显著。让模型扮演代码审查者,它会更关注边界条件、性能问题;扮演技术文档撰写者,输出会更结构化、术语准确。同样让模型写一段商品评价,如果Prompt是"帮我写个评价",输出可能很平淡;但如果设定"你是资深数码评测博主",模型会更倾向于输出参数对比、使用场景分析这类专业内容。
不过也要注意,过于复杂或矛盾的角色设定可能适得其反。"你是严谨的测试工程师但要快速给出答案"这种冲突描述会降低输出质量,因为两种要求在训练数据中很少同时出现。更关键的是,角色设定无法让模型突破知识边界。如果模型本身没有某领域的训练数据,再怎么设定角色也生成不出专业内容。更有效的做法是配合Few-shot示例、明确的任务指令和输出格式要求。关键还是整体Prompt设计的质量,包括上下文信息的完整性和指令的精确度。
扩展分析
模型的能力来源于预训练阶段见过的海量文本。在这些文本里,存在大量"角色-回答方式"的固定搭配模式。比如当文本里出现"作为资深工程师"这类描述后,通常会跟着技术细节、架构分析这类内容;而"作为客服人员"后面往往是礼貌用语、问题确认等话术。模型通过Transformer的注意力机制学到了这些统计关联。
当Prompt里出现"You are a Java expert"这样的角色设定时,这些token会在注意力计算中获得较高权重。后续生成每个词的时候,模型会通过自注意力机制反复参考这个角色设定,就像有个持续生效的上下文锚点。这导致生成阶段的概率采样会倾向于选择那些在训练数据中与"Java expert"共现频率高的token,比如"JVM"、"并发"、"Spring"这类专业词汇,而不是泛泛的"编程语言"、"代码"。
我自己做过一个简单测试,让模型生成关于Redis的技术文档。第一次Prompt就直接问"介绍下Redis的持久化机制",输出大概300字,涵盖了RDB和AOF的基本概念。第二次在前面加上"你是一位精通分布式系统的高级后端工程师",输出明显变化了——不仅详细对比了两种机制的性能影响,还主动提到了主从复制场景下的持久化策略,甚至给出了配置建议。内容深度和专业性都有显著提升。
不过这个效果差异在不同任务上表现不一样。如果问的是"Redis是什么"这种基础问题,加不加角色设定差别就不大,因为这个问题本身的答案空间就很窄。但如果是开放性任务,比如让模型设计缓存架构方案,角色设定的引导作用就会非常明显。

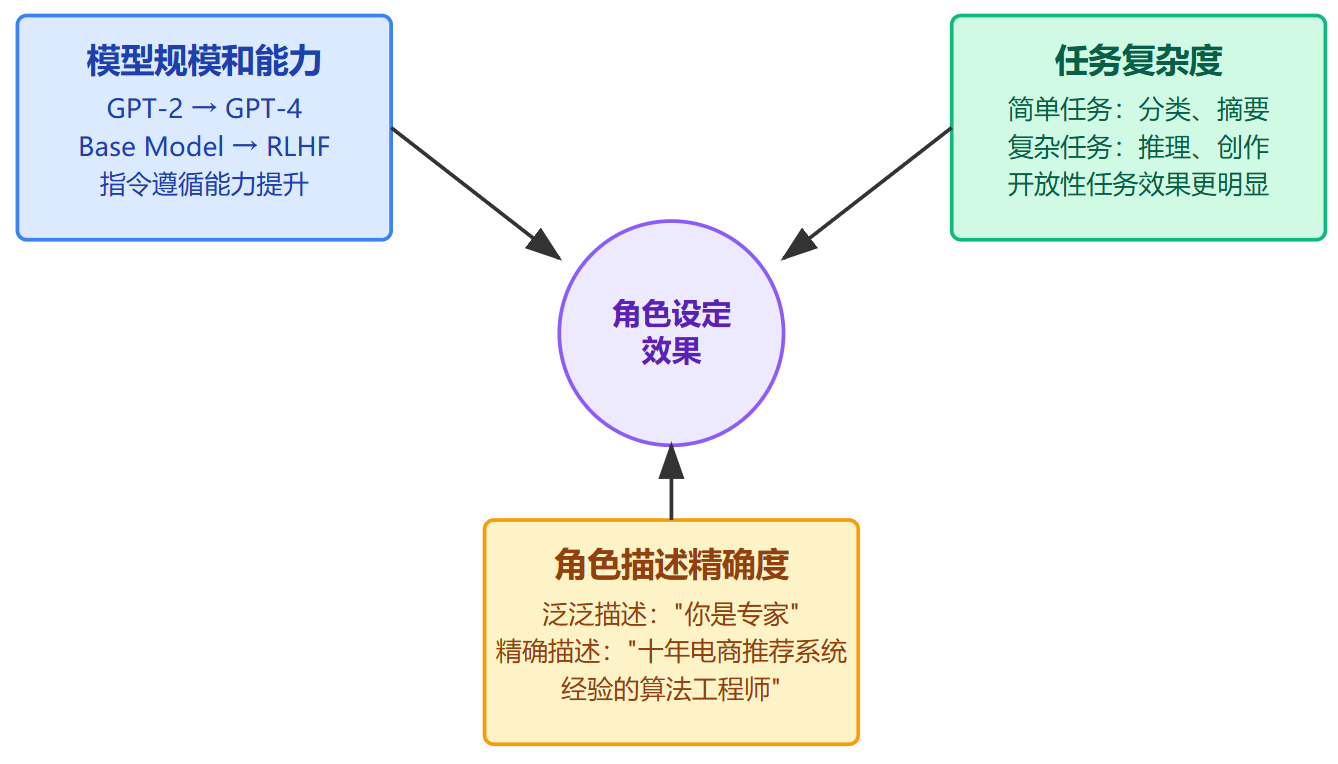
效果强弱主要看三个维度。第一是模型本身的规模和能力,像早期GPT-2可能角色设定作用就很有限,但到GPT-4这个级别,同样的角色描述能激活的知识深度完全不是一个量级。现在经过RLHF训练的版本,对角色指令的遵循能力明显比早期base model强,因为强化学习阶段专门优化了指令跟随这个目标。第二是任务复杂度,简单的分类、摘要任务角色设定帮助不大,但需要推理、创作的任务就很依赖角色引导。第三是角色描述的精确度,泛泛地说"你是专家"远不如说"你是有十年电商推荐系统经验的算法工程师",后者能激活的上下文信息更具体。
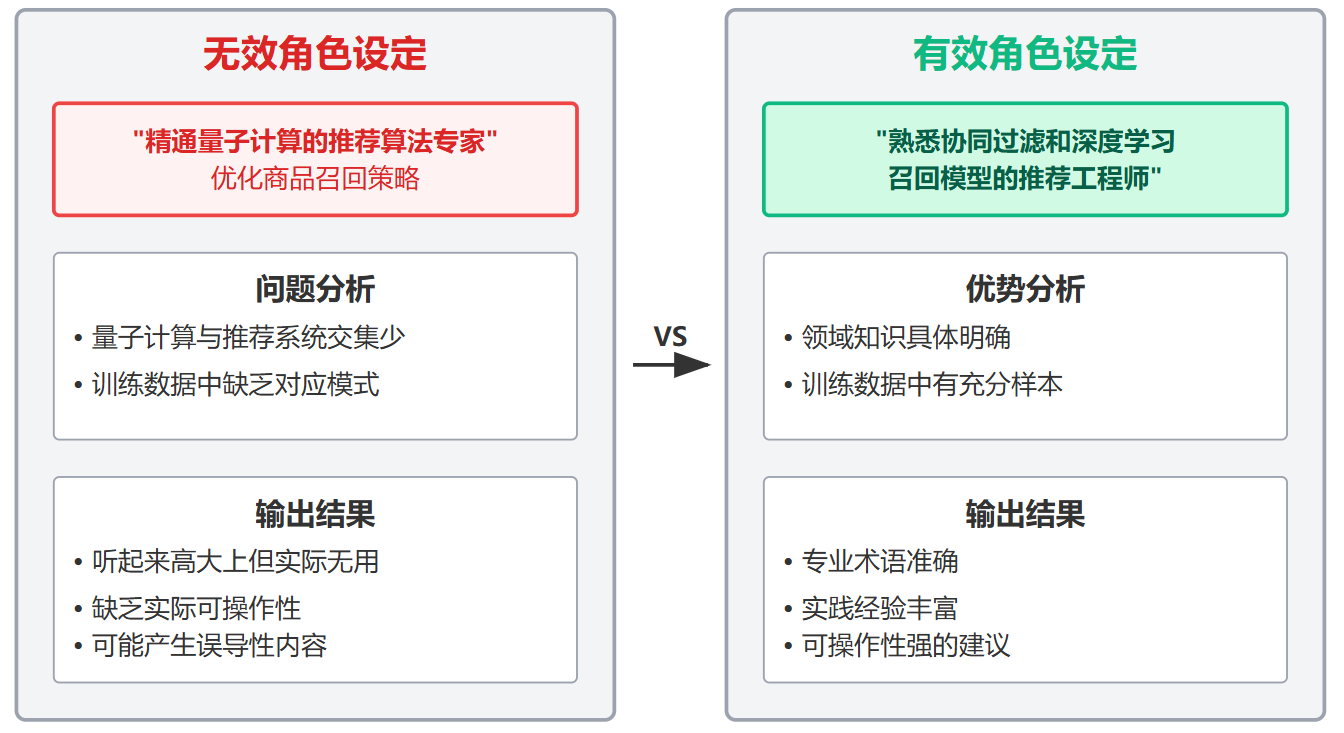
这里可以用个电商场景的反例来说明失效情况。比如让模型扮演"精通量子计算的推荐算法专家"去优化商品召回策略,这就属于无效设定。因为主流模型的训练数据里,量子计算和推荐系统基本没什么交集,这个组合角色在预训练语料里根本不存在对应模式。模型可能会生成一些听起来高大上但实际没用的内容。真正有效的角色设定应该是"熟悉协同过滤和深度学习召回模型的推荐工程师",这才是训练数据中有充分样本的角色定位。
单用角色设定确实不够,实际工作中会组合使用。比如设定角色后,再通过Few-shot给几个示例,告诉模型期望的输出格式和质量标准。或者配合Chain-of-Thought,让模型以这个角色的思考方式逐步推理。举个例子,要生成商品描述,可以这样设计Prompt:先设定角色"你是专业的电商文案策划",然后给两个优质示例作为Few-shot,最后加上CoT提示"请先分析商品核心卖点,再组织文案结构"。这种组合拳的效果远超单独使用任何一种技术。
有些论文专门研究过这个现象,比如Wei等人的工作发现,角色设定对于需要特定领域知识的任务提升明显,但对于纯逻辑推理任务帮助有限。还有研究表明,角色设定的效果在Instruction-tuned的模型上比base model更显著,因为指令微调阶段专门强化了模型对角色指令的遵循能力。
实践应用
角色设定特别适合那些需要特定专业视角的任务。比如代码生成场景,如果直接问"写个排序函数",模型可能给个最基础的冒泡排序;但如果设定"你是注重代码质量的高级工程师",它会倾向于给出更优的快排实现,还会附带时间复杂度说明和边界处理。再比如客服对话,设定"你是耐心的售后支持专员"后,模型的回复会自动带上道歉、确认理解、提供方案这些标准话术,而不是冷冰冰的直接回答。
编写角色设定的关键是要具体而不笼统。说"你是专家"几乎没用,但说"你是有5年Java后端经验、熟悉Spring生态和微服务架构的工程师"就完全不同。这种细化的描述能激活模型训练数据中更窄但更深的知识区域。还有个技巧是包含行为规范,比如"你在回答时会先确认需求、然后给出方案、最后说明潜在风险",这种流程化的指令能让输出更结构化。
实际调用API时,主流做法是通过system role设置角色。看个具体例子:
// 普通prompt,没有角色设定
String prompt ="解释下什么是线程安全";
ChatRequest request =ChatRequest.builder()
.messages(List.of(newMessage("user", prompt)))
.build();这是最基础的写法,输出通常比较教科书化。如果加上角色设定:
// 带角色设定的版本
ChatRequest request =ChatRequest.builder()
.messages(List.of(
newMessage("system",
"你是资深Java并发编程专家,擅长用实际案例解释复杂概念"),
newMessage("user","解释下什么是线程安全")
))
.build();这个改动看起来很小,但输出质量会有明显提升。第二个版本的回答通常会包含synchronized、volatile的具体用法,甚至给出错误示例和正确写法的对比,而不只是停留在定义层面。在实际项目中,我们通常会把常用的角色描述提取成配置,避免每次都写一遍。比如代码审查场景固定用"你是关注代码质量和安全性的资深工程师",文档生成场景用"你是技术写作专家,擅长将复杂概念用清晰结构呈现"。这种工程化思维能提升代码的可维护性。
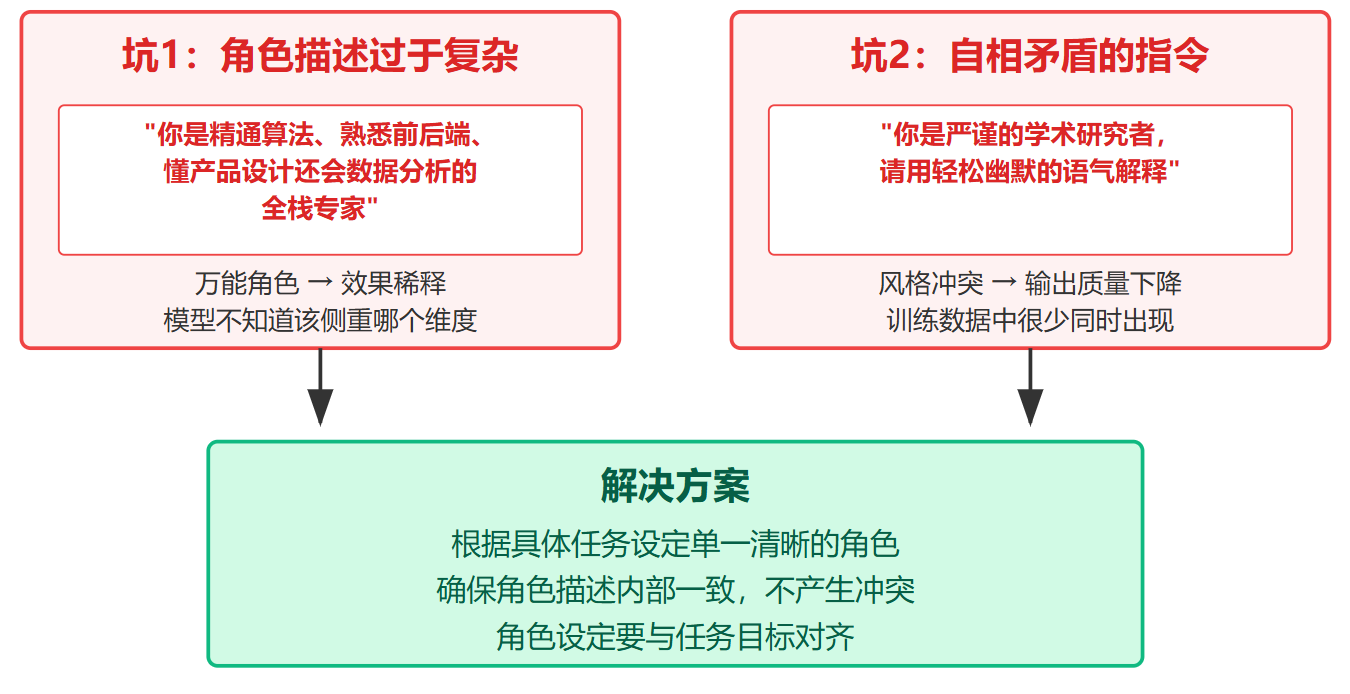
常见的第一个坑是角色描述过于复杂。见过有人写"你是精通算法、熟悉前后端、懂产品设计还会数据分析的全栈专家",这种万能角色反而会稀释效果,因为模型不知道该侧重哪个维度。更好的做法是根据具体任务设定单一清晰的角色。第二个坑是自相矛盾的指令,比如"你是严谨的学术研究者,请用轻松幽默的语气解释",这种冲突描述会让模型输出质量下降,因为两种风格在训练数据中很少同时出现。
拿技术文档生成来说,如果设定"你是追求创新的工程师",模型可能会给出一些实验性的非主流方案;但技术文档需要的是稳定可靠的最佳实践。这时候更合适的角色是"你是注重工程实践的技术作家,倾向于推荐经过验证的成熟方案"。角色设定要和任务目标对齐,而不是想当然地堆砌高大上的形容词。
验证角色设定有没有效果,最直接的办法是做A/B测试。准备一批相同的测试用例,分别用带角色设定和不带角色设定的prompt跑,然后对比输出质量。比如测试代码生成能力,可以准备20个不同难度的任务,记录输出的代码是否能通过单元测试、是否包含注释、是否处理了边界情况。通过这种量化指标来判断角色设定的收益。如果发现某个角色描述在80%的用例上都表现更好,那就值得固化到生产环境。
角色设定不是一次写好就完事的,需要根据badcase持续调整。假设发现模型生成的API文档经常缺少错误码说明,就可以在角色设定里加上"你在编写文档时会详细列出所有可能的错误码及处理建议"。这种基于反馈的优化循环,才是真正让Prompt质量提升的关键。

角色设定很少单独使用,通常是先设定角色,然后给Few-shot示例加强效果。看个简单的例子:
String systemRole ="你是专业的技术博客作者,擅长用代码示例解释概念";
String fewShotExample ="""
问:什么是装饰器模式?
答:装饰器模式允许向对象动态添加功能。举个例子:
public interface Component {
void operation();
}
public class ConcreteComponent implements Component {
public void operation() {
System.out.println("基础功能");
}
}
public class Decorator implements Component {
private Component component;
public Decorator(Component component) {
this.component = component;
}
public void operation() {
component.operation();
System.out.println("附加功能");
}
}
这种模式的优势在于可以灵活组合功能,避免创建大量子类。
""";
String userQuestion ="解释下策略模式";
ChatRequest request =ChatRequest.builder()
.messages(List.of(
newMessage("system", systemRole),
newMessage("user","什么是装饰器模式?"),
newMessage("assistant", fewShotExample),
newMessage("user", userQuestion)
))
.build();这种组合能让模型既保持角色设定的专业性,又遵循示例的格式风格。效果通常比单用其中任何一种技术都要好。所以不同技术要配合使用,关键是理解它们的适用边界,知道什么时候该用角色设定、什么时候需要配合其他手段。
进阶思考
生产环境不可能每次都手写角色设定,需要建立prompt模板库,按业务场景分类管理。比如代码生成、文档撰写、数据分析这些场景,每种都有对应的最佳实践模板。关键是要做版本控制,当发现某个角色设定效果变差时,能快速回滚到上一个稳定版本。甚至可以建立A/B测试框架,让新旧版本并行跑一段时间,通过数据对比决定是否全量切换。这种有迭代过程的优化,体现的是根据badcase调整策略的思维方式。
角色设定有个风险是可能加重幻觉。比如设定"你是数据库性能优化专家",模型为了符合这个角色人设,可能会编造一些听起来专业但实际不存在的优化参数。所以实际使用时会配合事实性约束,在prompt里加上"如果不确定请明确说明,不要猜测"这类指令。这种对技术风险的意识,比单纯说角色设定好用要成熟得多。
训练数据覆盖不足的时候,角色设定就是空谈。比如让模型扮演"熟悉Rust异步编程的系统工程师"去写tokio相关代码,如果模型预训练时Rust语料本来就少,再怎么设定角色也生成不出高质量代码。还有个常被忽略的点是角色冲突问题——"你是追求极致性能的工程师,请用最易读的方式写代码",这种互斥的要求会让模型输出变得拧巴。
如果被问到怎么量化评估效果,数据驱动的思路最实用。准备测试集,比如拿50个代码生成任务,分别用带角色设定和不带角色设定的prompt跑,然后从可编译率、单测通过率、代码复杂度这几个维度对比。甚至可以用GPT-4作为评判者,让它给两组输出打分,这种自动化评估的方法在实际项目中特别实用。当然这种评估也有局限性,比如主观性强的创作类任务就很难量化,这时候可能还是得靠人工抽样评估。
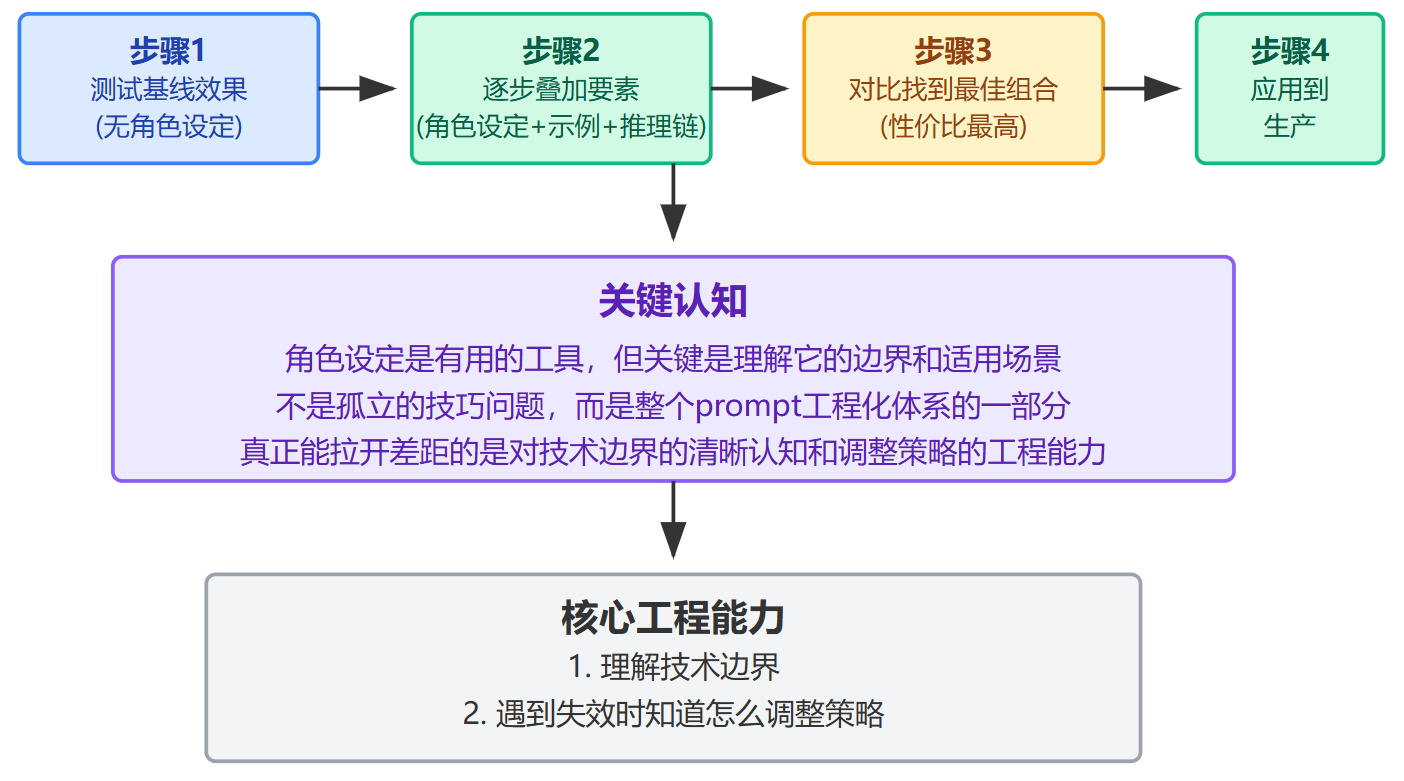
面对具体业务场景时,习惯是先测试基线效果,然后逐步叠加角色设定、示例、推理链等要素,通过对比找到性价比最高的组合。角色设定是个有用的工具,但关键是理解它的边界和适用场景,而不是盲目依赖。它不是孤立的技巧问题,而是整个prompt工程化体系的一部分。真正能拉开差距的,是对技术边界的清晰认知,以及遇到失效时知道怎么调整策略的工程能力。