精炼回答
性能测试自动化的核心是将测试集成到 CI/CD 流水线中,让它成为开发流程的自然组成部分。你需要先编写性能测试脚本,使用 JMeter、Gatling、K6 或者 Locust 这类工具来定义负载场景,比如模拟 1000 个并发用户持续访问 API 5 分钟。然后把这些脚本放到 CI 流水线里,每次代码提交或发版前自动触发执行。但关键不在于工具本身,而是要设定性能基线和阈值,比如 P95 响应时间不超过 200ms、吞吐量不低于 5000 TPS、错误率低于 0.1%。
识别性能回归主要靠历史数据对比和趋势分析。你需要把每次测试结果存储到时序数据库(InfluxDB、Prometheus),然后通过可视化工具(Grafana)观察指标变化趋势。当本次测试的响应时间比前 N 次平均值高出 10% 或者吞吐量下降 15% 时,就触发告警并标记为性能回归。更精细的做法是使用统计学方法,比如计算标准差,超过 2 个标准差就认为是异常波动。实际应用中,还要注意测试环境的一致性,资源配置、数据量、网络条件都要保持稳定,否则对比就失去意义。有些团队会使用 PerfCI、Lighthouse CI 这类专门的性能回归检测工具,它们会自动对比历史数据并给出回归报告,帮你快速定位是哪次提交引入的性能问题。
扩展分析
从测试流程到基线建立的完整体系
性能测试自动化不是简单写个脚本跑一跑,而是要建立一个完整的闭环系统。这套体系需要覆盖从测试脚本编写、执行触发、数据采集到结果分析的全过程。我会把性能测试脚本和业务代码放在同一个代码仓库里,用相同的版本管理机制,这样能体现测试左移的理念。执行环节的触发时机选择很关键,不是所有提交都要跑全量性能测试,太耗资源也没必要。更合理的设计是每次 PR 合并到主干时跑轻量级冒烟测试,每日构建跑完整的基准测试,发版前跑压力测试。这种分层设计既保证了质量防护,又不会拖慢迭代速度。
测试环境的标准化是个容易被忽视但很关键的点。性能测试最怕环境不稳定,今天测出来响应时间 100ms,明天变成 150ms,结果发现是因为测试机上跑了别的任务。解决方案是用容器化技术隔离测试环境,每次测试前拉起一套专用的环境,用完就销毁。同时固定资源配额,比如限定 4 核 8G 内存,这样每次测试的硬件条件都一致。数据也要标准化,测试数据集保持相同的规模和分布,避免因为数据差异导致的性能波动。
性能指标的选择要看测试目标。如果是接口类服务,我会重点关注延迟指标,不只是平均响应时间,更重要的是 P95、P99 这种长尾延迟,因为最慢的那部分请求往往决定了用户体验。比如搜索接口,平均响应时间可能是 50ms,但如果 P99 到了 500ms,就意味着 100 个请求里有 1 个会让用户明显感觉到卡顿。对于高并发场景,吞吐量比延迟更关键。比如秒杀系统,核心指标是每秒能处理多少下单请求,只要不超时,慢个几十毫秒用户能接受,但如果系统承载不住流量直接挂了,那就是灾难性的。资源占用指标也不能忽略,CPU、内存、网络 I/O 这些要一起采集,有时候性能下降不是代码问题,而是资源打满了,或者出现了内存泄漏。
基线建立是回归检测的基础。性能回归检测的前提是知道"正常"应该是什么样,这就是基线的作用。最简单的方式是取历史 N 次测试的平均值作为基线,比如最近 10 次测试的 P95 响应时间平均值是 180ms,那这个就是基线值。但简单平均有个问题,如果历史数据本身就有异常值,基线就会偏移。更稳健的做法是用中位数或者去掉最高最低值后再算平均。我还会计算标准差来衡量数据的波动范围。如果某个指标的标准差很小,说明系统表现稳定,那回归检测的阈值就可以设严格一点。反之如果标准差大,说明本身就容易波动,阈值就要放宽一些,避免误报。
除了静态基线,趋势分析也很重要。用 Grafana 画一条曲线,横轴是构建版本号,纵轴是响应时间。如果曲线突然拐了一个弯往上走,即使单次测试没超阈值,也可能是性能在逐渐劣化,需要引起注意。这种可视化的趋势观察能帮你在性能彻底崩掉之前就发现端倪。

回归判定需要量化的算法思路。最直接的是阈值法,设定一个百分比或者绝对值的偏差范围。比如规定 P95 响应时间不能比基线高 15%,或者说不能超过 200ms 这个硬性指标。但纯阈值法的问题是容易误判,网络抖动或者偶然的 GC 停顿都可能触发告警。进阶方案是结合连续性判断,不是一次超标就报警,而是连续 3 次测试都超过阈值才认定为回归。更严谨的方式是用 T 检验来比较本次测试和历史数据集是否有显著差异。简单说就是计算本次结果偏离基线几个标准差,超过 2 倍标准差的概率很小,可以认为是真的发生了性能劣化。
下面是一个典型的回归检测实现逻辑:
publicclassPerformanceRegressionDetector{
privatestaticfinalint HISTORICAL_WINDOW =10;
privatestaticfinaldouble STDDEV_THRESHOLD =2.0;
privatestaticfinalint CONSECUTIVE_THRESHOLD =3;
publicRegressionResultdetectRegression(String metricName,double currentValue){
// 获取历史数据
List<Double> historicalValues =fetchHistoricalData(metricName, HISTORICAL_WINDOW);
// 计算基线和标准差
double baseline =calculateBaseline(historicalValues);
double stdDev =calculateStdDev(historicalValues, baseline);
// 判断是否超过阈值
double threshold = baseline + STDDEV_THRESHOLD * stdDev;
boolean exceedsThreshold = currentValue > threshold;
if(exceedsThreshold){
// 检查连续回归次数
int consecutiveCount =checkConsecutiveRegression(metricName);
if(consecutiveCount >= CONSECUTIVE_THRESHOLD){
double degradation =((currentValue - baseline)/ baseline)*100;
returnRegressionResult.builder()
.isRegression(true)
.metricName(metricName)
.currentValue(currentValue)
.baseline(baseline)
.degradationPercent(degradation)
.consecutiveCount(consecutiveCount)
.build();
}
}
returnRegressionResult.noRegression();
}
privatedoublecalculateBaseline(List<Double> values){
// 使用中位数而非平均值,更抗异常值干扰
List<Double> sorted = values.stream()
.sorted()
.collect(Collectors.toList());
int size = sorted.size();
return size %2==0
?(sorted.get(size/2-1)+ sorted.get(size/2))/2.0
: sorted.get(size/2);
}
privatedoublecalculateStdDev(List<Double> values,double mean){
double variance = values.stream()
.mapToDouble(v ->Math.pow(v - mean,2))
.average()
.orElse(0.0);
returnMath.sqrt(variance);
}
}
数据采集、告警机制与问题定位
测试执行后会产生大量指标数据,需要合理的存储和展示方案。我的方案是测试脚本把结果推送到 InfluxDB,它是专门为时序数据设计的,写入性能好而且自带数据过期策略,不用担心存储爆炸。数据结构设计上要用 tag 来标记可过滤的维度,比如接口路径、版本号、环境,这样后续可以很方便地按版本对比性能。用 field 存具体的指标数值,这样在 Grafana 里能直接做聚合计算。
publicclassPerformanceMetricsPublisher{
privateInfluxDB influxDB;
publicvoidpublishMetrics(TestResult testResult){
Point point =Point.measurement("api_performance")
.tag("endpoint", testResult.getEndpoint())
.tag("version", testResult.getBuildVersion())
.tag("environment", testResult.getEnvironment())
.addField("response_time_avg", testResult.getAvgResponseTime())
.addField("response_time_p95", testResult.getP95ResponseTime())
.addField("response_time_p99", testResult.getP99ResponseTime())
.addField("throughput", testResult.getThroughput())
.addField("error_rate", testResult.getErrorRate())
.addField("cpu_usage", testResult.getCpuUsage())
.addField("memory_usage", testResult.getMemoryUsage())
.time(System.currentTimeMillis(),TimeUnit.MILLISECONDS)
.build();
influxDB.write(point);
}
}
有了这些数据,在 Grafana 里配置一个 dashboard,横轴是时间或者构建版本号,纵轴是响应时间,就能看到性能的变化趋势。再加一条基线的水平线,一旦曲线突破基线就能立刻察觉。
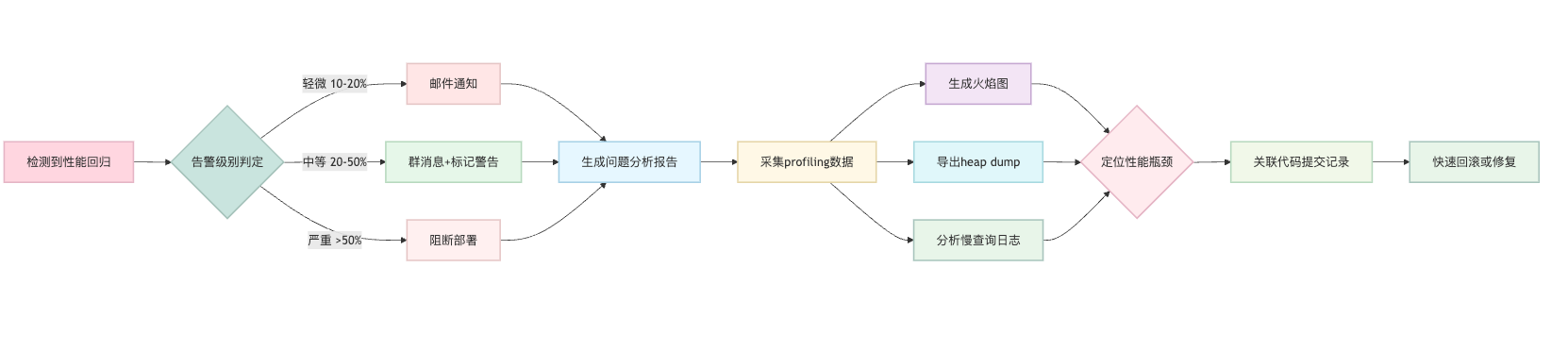
告警机制要分级处理,不同严重程度用不同的通知方式。如果 P95 响应时间超基线 10% 到 20%,发送邮件通知相关负责人,这个级别不需要立即响应,但要记录下来。如果超过 20% 或者连续 3 个版本都在劣化,就升级为钉钉或者企业微信的群消息,同时在 CI 流水线里把状态标记为警告,让大家引起重视。如果超过 50% 或者错误率突然飙升,那就要阻断部署流程,直接让 CI 任务失败,不允许上线。这种分层策略既保证了重要问题不会被遗漏,又避免了过度告警让人疲劳。
发现性能回归后怎么快速找到原因是个实战难题。第一步是看监控图表确认问题确实存在,然后用 profiling 工具抓取详细的调用栈信息。对于 Java 应用,我会用 async-profiler 在测试环境重现问题时采样,生成火焰图。火焰图的横轴是调用占比,纵轴是调用栈深度,哪个方法耗时多一眼就能看出来。有次发现一个接口的 P95 响应时间从 100ms 涨到 300ms,通过火焰图发现是某次代码重构把 N+1 查询引入了,原本批量查询改成了循环单条查询,定位到后马上就改回去了。如果是 Python 服务,可以用 py-spy 来做在线 profiling,它可以附加到运行中的进程而不需要修改代码,对性能影响也很小。
除了火焰图,还要结合资源监控一起看。如果 CPU 使用率正常但响应时间变长,可能是 I/O 瓶颈,这时候要看数据库慢查询日志或者网络延迟。如果内存占用持续增长,可能是内存泄漏,就要用 heap dump 分析对象分配情况。把这些手段组合起来,基本上能覆盖大部分性能问题的定位场景。
AI 场景下的特殊考量与工程化实践
2025 年性能测试不可避免要面对 AI 系统的特殊性。AI 模型的性能测试和传统服务有些不一样,因为它的性能特征更复杂。对于模型推理服务,最关心的是单次推理耗时,这直接影响用户体验。但推理时间受 batch size 影响很大,batch 越大,单条数据的平均时间越低,但端到端延迟会变长。所以测试时要覆盖不同的 batch 配置,找到延迟和吞吐的平衡点。
模型推理通常在 GPU 上跑,所以 GPU 利用率是核心指标。如果 GPU 利用率只有 30%,说明可能存在 CPU 和 GPU 之间的数据传输瓶颈,或者推理框架没优化好。理想情况下,GPU 利用率应该在 80% 以上。我会同时监控显存占用,有些模型加载后显存就占了大半,导致 batch size 开不大,这时候就需要考虑模型量化或者换更大显存的卡。
对于 LLM 推理服务,还要关注首 token 时间和生成速度。用户发送请求后,多久能看到第一个字的输出,以及后续每秒能生成多少个 token,这些都是体验的关键。如果是多模态模型,比如图文理解,性能测试要覆盖不同输入组合。纯文本、小图片、大图片、长文本配图片,这些场景的性能表现可能差异很大,都要测到。AI 场景的性能测试,除了传统的响应时间、吞吐量,还要关注资源利用效率和成本。因为 GPU 资源很贵,同样的性能表现,用更少的显存、更低的利用率跑出来,成本优势就很明显。
实际工程中,误报处理是个常见难题。如果回归检测系统经常误报,团队慢慢就不信任它了。解决方案是建立分层策略,不是所有波动都要立刻告警,而是要区分噪音和信号。引入置信度的概念,轻微波动先观察几次,只有趋势性劣化才升级告警。更重要的是要建立反馈机制,每次误报后记录原因是环境抖动、测试数据问题还是基线设置不合理,然后不断调整检测参数。单一指标出现波动时不急着下结论,而是看资源指标有没有异常、其他相关接口有没有同步劣化、是不是特定时间段的问题。保留测试现场,把那次测试的详细日志、监控数据都存下来,方便后续回溯分析。
当系统有几百个服务、上千个接口时,不可能每个都手工配置性能测试。这时候需要体系化建设的思路。核心链路的服务做全面的性能测试,边缘服务做抽样测试。建立测试模板库,相似的服务共用一套测试脚本和基线配置,通过参数化来适配不同场景。基线的维护也要自动化,不能每次都人工去调,可以设计成基线自适应机制,当系统经过性能优化后性能整体提升时,基线会自动向好的方向调整。
性能测试自动化不是孤立的,它应该和代码审查、单元测试、集成测试形成完整的质量防护网。当检测到性能劣化但不是严重到要阻塞发布时,记录成技术债务,排期专门去优化。把战术问题上升到战略层面,这是高级工程师和普通开发的重要区别。整套体系建立起来后,要整理成文档和模板,让团队其他成员也能快速上手,这样才能让性能测试真正融入到日常开发流程中,持续发挥价值。