精炼回答
FIM(Fill-in-the-Middle)是一种让模型具备中间填充能力的训练和推理技术。传统语言模型只能从左到右生成文本,但代码补全场景中,你的光标往往在代码中间位置,此时需要模型理解光标前后的上下文来生成中间部分。
具体来说,FIM通过重新组织训练数据实现这个能力。训练时会把一段完整代码拆分成前缀(prefix)、中间(middle)、后缀(suffix)三部分,然后用特殊token重新排列,比如变成 <FIM_PREFIX>前缀内容<FIM_SUFFIX>后缀内容<FIM_MIDDLE>中间内容 这样的格式。模型学会了这种模式后,推理时就能根据光标前后的代码来预测中间应该填什么。
代码补全为什么必须有这个能力?因为实际编码时你经常在已有代码中插入新逻辑。比如你写了一个函数声明和返回语句,现在要在中间补充函数体;或者已经写好了类的开头和结尾,需要在中间添加新方法。这时候后缀代码提供的类型信息、变量使用、返回值约束等上下文对生成准确代码至关重要。如果模型只能看到前文,就会产生与后续代码不一致的补全结果。FIM让模型能同时利用双向上下文,大幅提升补全的准确性和实用性。
扩展分析
核心原理与技术实现
面试时被问到FIM,千万别急着背定义,先用一句话让面试官知道你理解核心问题:"FIM解决的是代码补全中光标在中间位置时,模型怎么同时利用前后代码上下文的问题"。这样开头能快速建立对话基础。
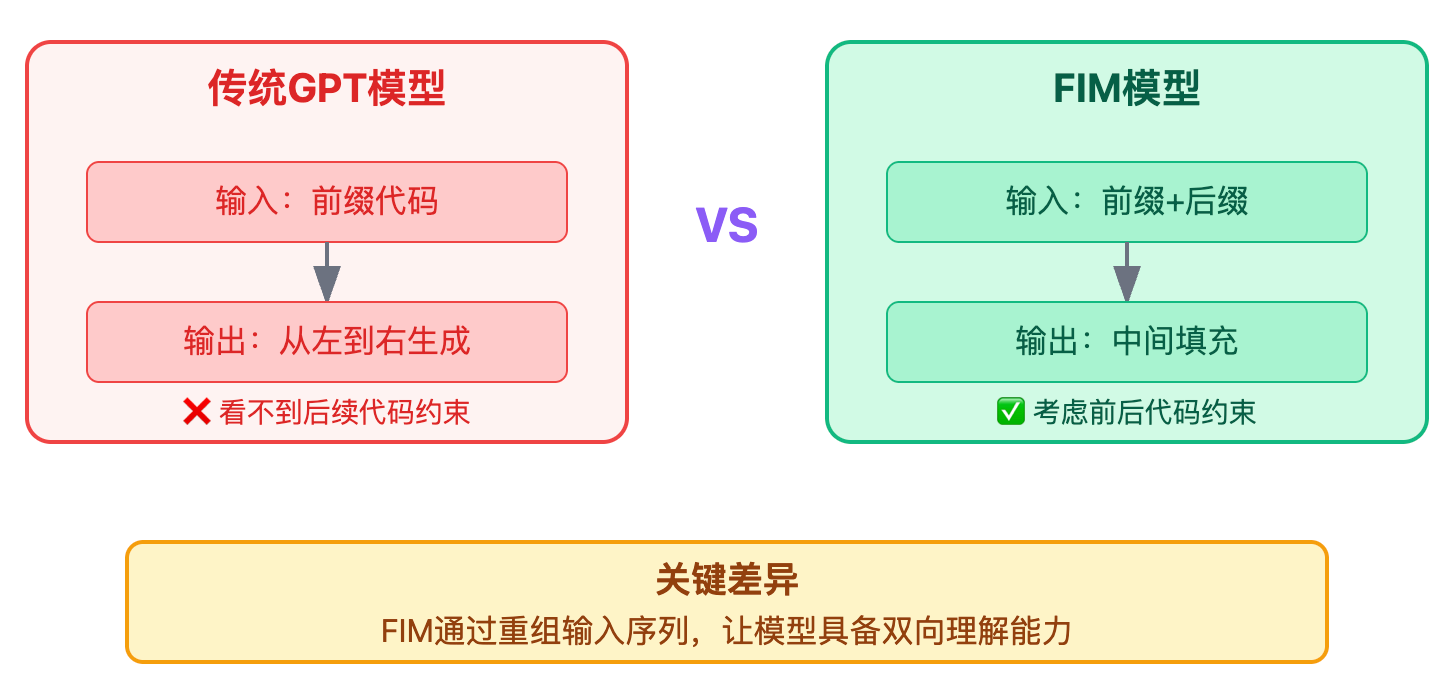
传统的GPT类模型本质上是个条件概率链,每个token的生成都只依赖前面已经生成的内容,这在文本生成场景没问题,因为我们写文章确实是从前往后写的。但代码编写的工作模式完全不同,开发者大量的时间都在修改已有代码,而不是从空白文件开始一路写到底。这样铺垫能让面试官意识到问题的根源不是技术实现,而是场景需求的错配。
FIM最精妙的地方在于它没有改变模型的生成方式,自回归还是从左到右生成,但通过重新组织输入序列的顺序,让模型看起来具备了双向理解能力。来看一个直观的例子:
// 原始代码场景:你在这个位置补全 publicOrderResultprocessOrder(String orderId){ // [光标在这里] returnnewOrderResult(order.getId(), order.getStatus()); }
java
如果用传统模型,它只能看到函数签名,不知道你要返回什么,可能会生成各种逻辑。但FIM训练时会把这段代码重组,变成类似这样的序列:
<FIM_PREFIX>public OrderResult processOrder(String orderId) { <FIM_SUFFIX>return new OrderResult(order.getId(), order.getStatus()); } <FIM_MIDDLE>
模型在训练时学会了这种模式后,推理时就知道要根据prefix和suffix来生成middle部分。注意这里模型仍然是从左往右生成token,但因为suffix已经在输入里了,生成的内容自然会考虑后面的约束。

训练时有两种主要策略来组织这些片段。PSM(Prefix-Suffix-Middle) 就是刚才说的顺序,先给前缀,再给后缀,最后让模型生成中间。SPM(Suffix-Prefix-Middle) 是把后缀放在最前面。
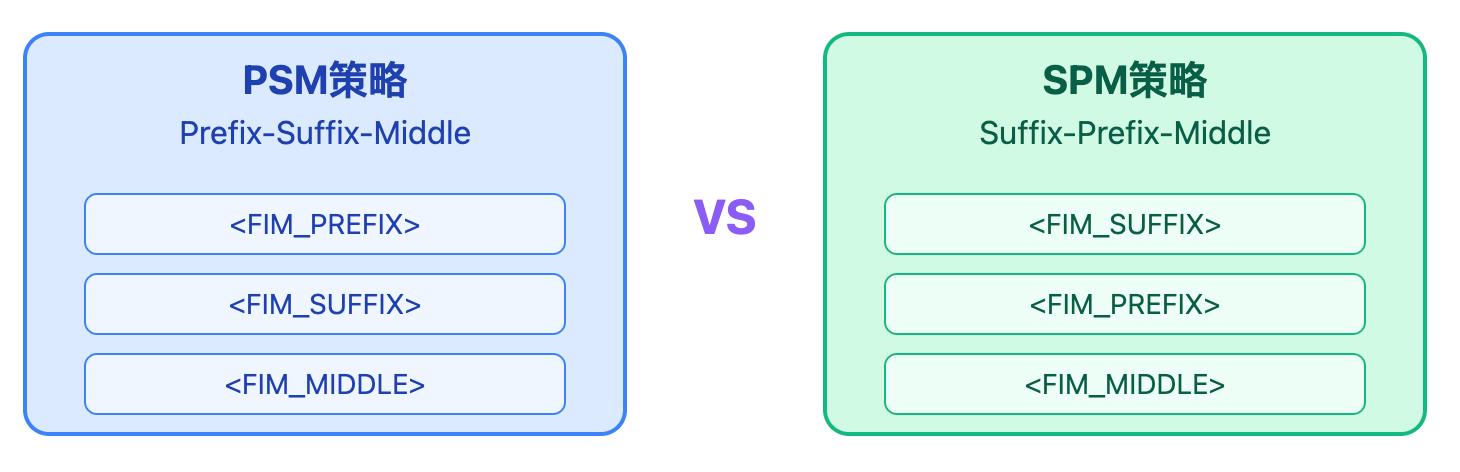
这两种策略各有考量,PSM更符合人类的阅读习惯,但SPM在某些场景下能让模型更早看到约束信息。实际应用中,很多模型会混合使用这两种策略来训练,让模型对不同的输入顺序都能适应。
代码补全和文本补全本质区别在于代码有极强的结构性和约束性。当你在一个类里添加新方法时,方法签名、返回类型、异常处理方式都可能在后续代码里有明确的使用痕迹。比如在电商系统里,你要补全一个计算优惠的方法:
`publicDiscountInfocalculateDiscount(Order order){ // [需要补全的部分]
// 后面的代码已经写好 logger.info("Applied discount: {}", discountInfo.getAmount()); return discountInfo; }`
java
这里后续代码已经在用discountInfo这个变量了,那你生成的逻辑就必须创建这个对象并赋值。传统模型看不到后面,很可能生成一个直接return的语句,导致后面的代码变成死代码。FIM能避免这类问题,因为它在生成时已经知道后面需要什么。
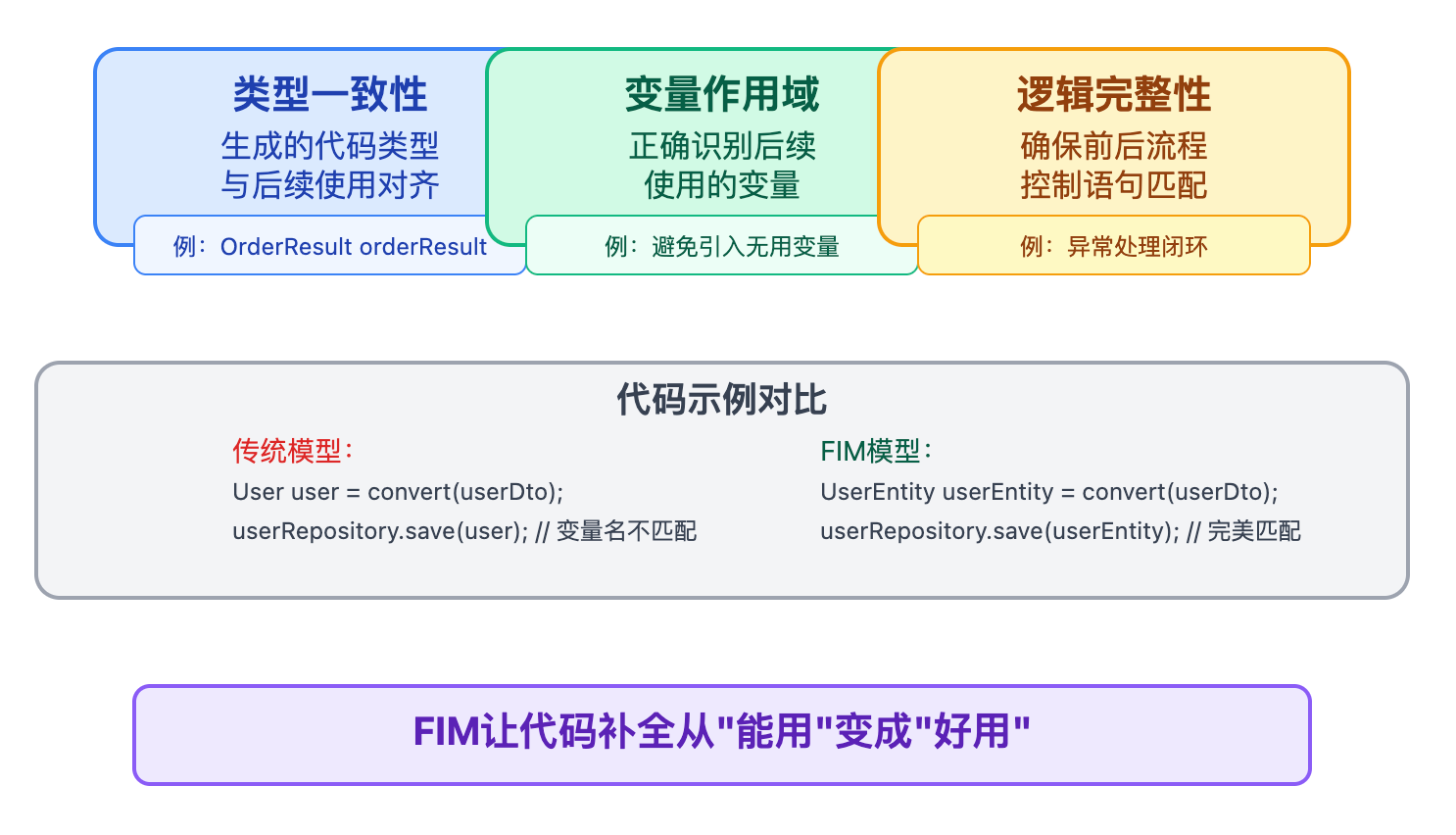
FIM带来的提升主要体现在三个方面。第一是类型一致性,生成的代码类型能和后续使用对齐。第二是变量作用域的正确性,模型知道哪些变量在后面会被用到,不会随意引入新变量。第三是逻辑完整性,在补全条件分支或异常处理时,能确保和后续的流程控制语句匹配。这些能力让AI代码补全从"能用"变成"好用",开发者的接受度会高很多。
实际应用场景
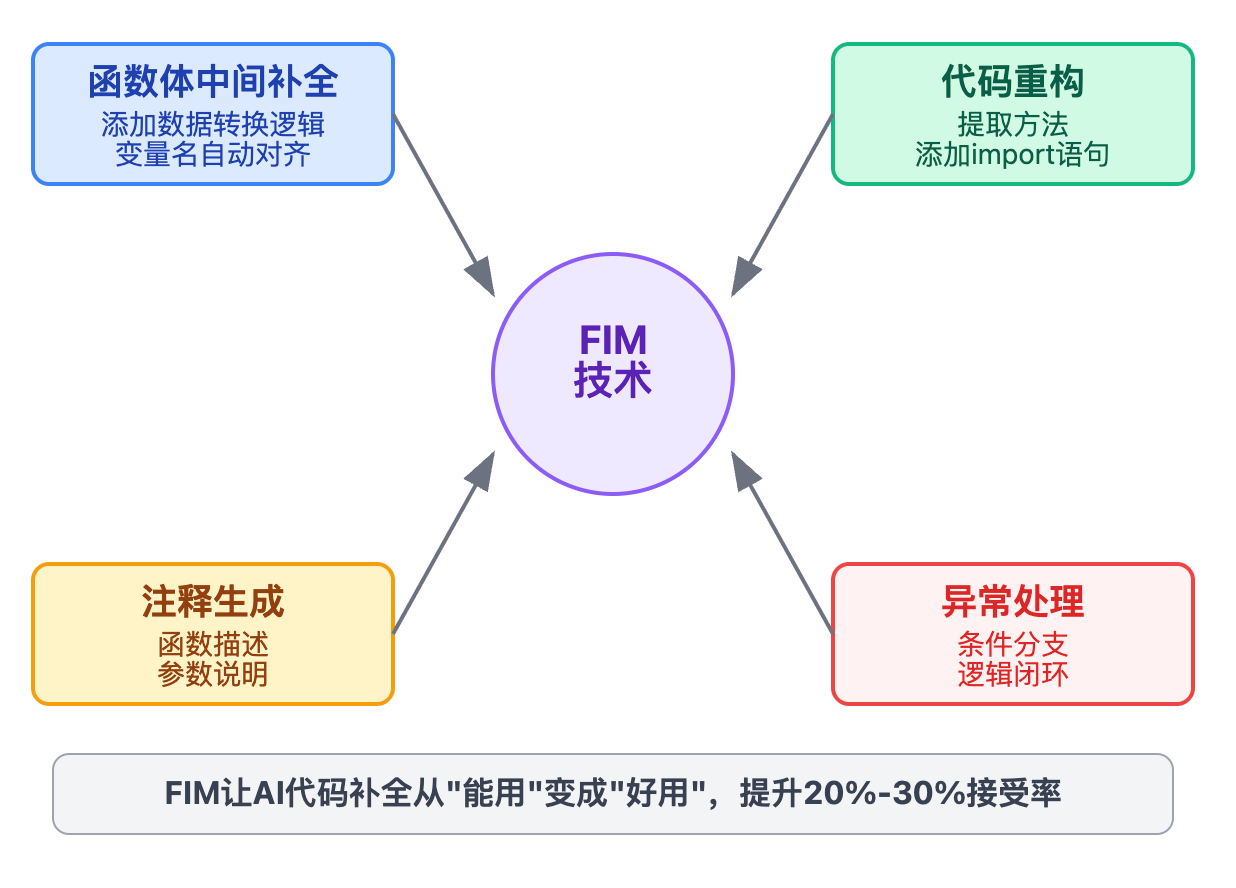
现在主流的代码补全工具基本都用上了FIM能力,GitHub Copilot、AWS CodeWhisperer、Cursor这些产品背后的模型都支持中间填充。在IDE里最常见的使用场景其实是在已有函数中间添加新逻辑。当你写完一个函数的框架,包括参数校验、返回语句这些外围代码后,突然想在中间加个数据转换的逻辑,这时候光标停在函数体中间。如果没有FIM,模型只能看到前面的参数定义,很可能生成一个完全独立的逻辑块,但实际上后面的代码已经在使用某些特定的变量名或者调用了特定方法。
举个典型的对比场景能让这个差异更直观。假设你在写一个数据处理的方法,已经定义好了方法签名,后面也写好了把结果存入数据库的代码:
`publicvoidprocessUserData(UserDTO userDto){ // [光标在这里,需要补全数据转换逻辑]
userRepository.save(userEntity); }`
java
传统的从左到右生成模型看不到后面的save(userEntity),可能会生成各种临时变量名,比如user、processedUser、result之类的。但支持FIM的工具能看到后面需要的是userEntity这个变量,生成的代码就会直接创建并命名为userEntity,和后续代码完美衔接。这种差异在实际使用中体验非常明显,开发者不需要再手动改变量名或者调整代码顺序。
根据一些公开的技术报告,支持FIM的模型在代码补全的接受率上能提升20%-30%,特别是在函数体中间补全这种场景。这个提升主要来自两方面,一是生成的代码变量名、类型能和后续代码对齐,减少了需要手动修改的情况;二是逻辑完整性更好,特别是在处理异常、循环这些结构化代码时,模型能确保前后逻辑闭环。
谈到不同编程语言的表现时,FIM在静态类型语言里的表现通常比动态类型语言更稳定。这背后的原因值得说一说:Java、TypeScript这类语言因为有明确的类型声明,后缀代码中的类型信息对前面的生成约束更强,模型能更准确地推断出应该生成什么。而Python、JavaScript这些语言,变量类型在代码里不显式标注,FIM虽然也能工作,但准确度会受影响。不过最近的一些新模型通过在训练数据中加入更多的项目级别上下文,在动态语言上的表现也在快速提升。
FIM的价值不只是在补全代码逻辑,在代码重构场景下也很有用。比如你在重构一个类的时候,把某个方法从中间提取出去改成独立的工具类,这时候需要在调用处插入新的import语句和方法调用代码。FIM能看到前面的上下文知道这是什么类型的操作,也能看到后面原有的代码逻辑,生成的重构代码就会更符合项目的编码风格和命名规范。
还有个容易被忽视的场景是注释生成。当你写完一个函数后回到开头准备加注释,光标在函数声明上面,如果模型支持FIM,它能看到下面完整的函数实现,生成的注释就能准确描述函数的实际行为、参数用途、返回值含义,而不是只根据函数名瞎猜。这种体验对提升代码文档质量有实实在在的帮助。
工程实践与权衡
面试官问FIM这个问题,真正想考察的其实是你对AI编程助手这个领域的理解深度。如果你只停留在"模型能双向理解代码"这个层面,很难让面试官觉得你有深入思考。最常见的追问会落在性能开销上,面试官可能会问:"FIM需要把suffix也送进模型,上下文长度变长了,推理速度会不会受影响?"
这个问题不能简单回答会或不会,要展现你理解这背后的权衡逻辑。FIM确实会增加输入长度,但这个开销在实际产品中是可控的。IDE场景下的补全通常只需要关注光标周围几百行代码,不需要把整个文件都塞进去。主流产品会做智能截断,根据光标位置和代码结构动态选择最相关的前缀和后缀片段。这个策略既保证了上下文的有效性,又把推理延迟控制在用户可接受的范围内,一般在100-300毫秒之间。
另一个追问方向是模型复杂度的平衡。有些候选人可能觉得FIM是个额外的能力,需要增加模型参数。其实FIM本质上不是在模型架构上加新东西,而是训练策略的调整。同样的Transformer架构,通过在训练数据中混入不同比例的FIM格式样本,模型就能学会这个能力。关键是要找到合适的混合比例,既不能让FIM数据占比太高影响模型的正常生成能力,也不能太低导致中间填充效果不好。一般会在训练数据中保持10%-30%的FIM样本,这个配比在多个开源模型的技术报告里都能看到验证。
从架构视角看,FIM在整个AI编程助手中的定位其实是基础能力层。如果把代码助手看成一个系统,FIM解决的是"在哪里生成"的问题,而代码理解、项目上下文检索、意图识别这些能力解决的是"生成什么"的问题。这两层能力要配合好才能做出真正好用的产品。在实际使用Cursor这类工具时能明显感受到,当它既能准确理解你的意图,又能把生成的代码无缝插入到正确位置时,整个开发体验会提升一个量级。
这样一套理解下来,你就不会把FIM看成一个孤立的技术点,而是理解它在整个代码补全链路中扮演的角色。面试时能这样讲出来,面试官会感受到你不是临时抱佛脚背的答案,而是真正在实践中用过或思考过这些技术。