精炼回答
位置偏见是指模型在处理序列数据时,对不同位置的信息关注程度不一致,通常对开头和结尾的内容更加敏感。这个现象在语言模型、推荐系统和检索模型中都很常见,不是模型的bug,而是训练机制导致的系统性现象。
最典型的表现就是U型曲线——模型对开头和结尾的内容特别敏感,但中间部分的信息容易被稀释。如果你做过RAG系统或者文档检索,应该遇到过这样的问题:同样的关键信息,放在文档开头模型很容易抓到,但放在中间第五、六段就像没看见一样。
模型更关注开头主要源于注意力机制的计算方式。在自回归生成时,开头token会被后续所有token反复关注,参与的计算次数最多,梯度累积也最显著,导致模型学习到这些位置的重要性。而在双向编码器中,开头位置往往承载着主题或关键信息,训练数据的统计特性强化了这种模式。
对结尾的偏好则与近因效应和解码机制有关。在长文本处理中,最近的上下文对预测影响更直接,而且结尾位置通常包含总结性信息。在检索任务中,如果文档被截断,结尾恰好是最后保留的有效信息。这种偏见会带来实际问题:比如在RAG系统中,如果把关键信息放在长上下文的中间部分,模型可能会"遗忘"或忽略它;在文档排序时,相同内容因位置不同会得到不同的评分。常见的缓解方法包括Lost in the Middle训练策略,在不同位置随机放置关键信息来消除偏见,或者使用滑动窗口和位置插值等技术来平衡各位置的重要性。
扩展分析
位置偏见的本质机制
位置偏见最直观的表现就是U型注意力模式。如果把模型对序列中每个位置的关注度画出来,会发现两端高、中间低的曲线。比如让模型从一篇长文档里提取信息,如果关键内容在开头第一段或者最后总结部分,模型很容易抓到;但同样的内容放在中间第五、六段,模型经常就像没看见一样。这不是偶发现象,而是可以稳定复现的系统性偏差。
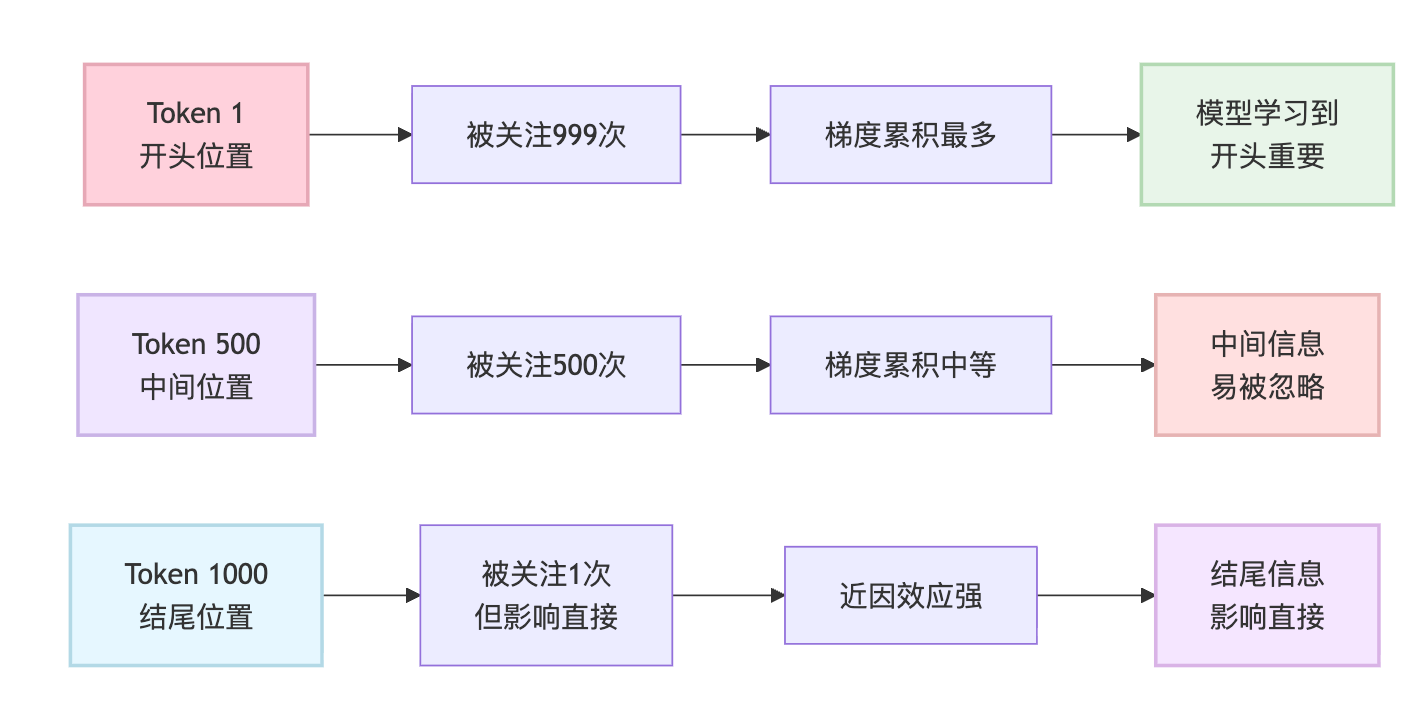
这种偏见的根源要从Self-Attention的计算机制说起。在自回归生成过程中,序列开头的token会被后续所有token反复关注。假设序列长度是1000,第一个token参与了999次注意力计算,而中间第500个token只参与了大约500次。这种计算次数的差异直接导致梯度累积的不均衡。更隐蔽的是,在反向传播时,开头位置的梯度来自所有后续位置的汇总,信号强度远超中间位置。模型在优化过程中自然会学到"开头很重要"这个模式,即使我们没有显式告诉它。
注意力机制只是提供了偏见产生的土壤,真正让它生根发芽的是训练数据的统计特性。人类写的文档天然就有结构偏好——学术论文把摘要放开头,新闻报道遵循倒金字塔原则,技术文档在开头声明核心要点。模型在海量这样的数据上训练,会强化"重要信息在开头"的先验。如果用随机打乱段落顺序的数据来训练,位置偏见会明显减弱,但这会牺牲模型对正常文档的理解能力。所以位置偏见某种程度上是模型学会人类写作习惯的副产物。
2023年有个很经典的研究直接把这个问题命名为Lost in the Middle,他们发现即使是支持32K上下文的模型,当关键信息放在输入的中间位置时,准确率会从开头位置的90%以上暴跌到60%左右。更有意思的是,这个现象在不同任务上表现一致——问答、摘要、代码理解都存在同样的U型曲线,说明这是模型架构层面的特性,不是某个任务特有的问题。
位置编码的影响是个容易被忽略但很重要的点。很多人以为位置编码只是告诉模型token的位置信息,但它实际上也参与了偏见的形成。绝对位置编码会让模型记住"位置5通常很重要"这种绝对坐标的模式,而相对位置编码关注的是"当前token和前3个token的关系",这种相对关系能一定程度缓解位置偏见。这也是为什么ALiBi、RoPE这些相对位置编码方案在长文本任务上表现更稳定。但相对位置编码也不是银弹,它解决了绝对坐标依赖,却引入了新问题——距离衰减。很多相对编码方案会让模型对远距离依赖的关注度随距离衰减,这在某些任务上反而是劣势。
虽然我们主要讨论Transformer的位置偏见,但其实RNN和CNN也有类似问题,只是表现形式不同。RNN因为序列处理的特性,对结尾信息的偏好更明显,因为信息必须层层传递,中间容易衰减。CNN因为固定感受野,对序列全局结构的感知本身就弱,位置偏见反而没那么突出,但它有另一个问题——对局部模式过度敏感。
实际应用中的问题与对策
位置偏见对RAG系统的影响特别直接,因为检索回来的文档要拼接成长上下文喂给模型。假设检索模块返回了10篇相关文档,如果简单按相似度得分从高到低排列,那么排在中间的文档即使内容很相关,模型也可能视而不见。更糟糕的是,如果检索召回阶段漏掉了关键信息,恰好把它排在第五、六位,整个系统的准确率会明显下降。实际测试中发现,同样的文档内容,放在拼接序列的开头位置,模型引用率能达到70%以上;但放在中间第五位,引用率可能掉到30%左右。这不是检索质量的问题,纯粹是位置导致的差异。
最直接的办法是调整文档排序策略。比如不是简单按相似度降序排列,而是采用**"首尾夹击"**的策略——把最相关的文档放开头,次相关的放结尾,把不太重要的夹在中间。这样即使模型对中间部分关注度低,关键信息也能被捕捉到。如果文档本身很长,单纯调整顺序还不够,这时候可以用滑动窗口的思路。就像看一本厚书,不是一次性把所有页都摊开,而是每次只看一个章节,但窗口要有重叠,确保不漏掉跨章节的信息。在RAG系统里,就是把长文档切成多个chunk,每个chunk单独喂给模型,然后合并结果。
切片的时候要注意重叠区域的设置,一般建议overlap设为chunk size的10%-20%。太小会漏信息,太大会增加重复计算。而且每个chunk最好是语义完整的单元,不要在句子中间硬切,否则模型理解会出问题。下面是一个简单的文档切片实现:
defsplit_document_with_overlap(document, chunk_size=512, overlap_ratio=0.15):
"""
将长文档切分成有重叠的片段,缓解位置偏见
Args:
document: 原始文档文本
chunk_size: 每个片段的token数量
overlap_ratio: 重叠区域占chunk_size的比例
"""
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
tokens = tokenizer.encode(document, add_special_tokens=False)
chunks =[]
overlap_size =int(chunk_size * overlap_ratio)
step_size = chunk_size - overlap_size
for i inrange(0,len(tokens), step_size):
chunk_tokens = tokens[i:i + chunk_size]
# 确保不在句子中间切分
chunk_text = tokenizer.decode(chunk_tokens)
if i + chunk_size <len(tokens):
# 找到最后一个句号、问号或感叹号
last_punct =max(
chunk_text.rfind('。'),
chunk_text.rfind('?'),
chunk_text.rfind('!')
)
if last_punct >len(chunk_text)*0.7:# 确保不会切掉太多内容
chunk_text = chunk_text[:last_punct +1]
chunks.append({
'text': chunk_text,
'start_pos': i,
'end_pos': i +len(chunk_tokens),
'position_hint':'start'if i ==0else('end'if i + chunk_size >=len(tokens)else'middle')
})
return chunks
# 使用示例
long_document ="""
这是一篇很长的技术文档,包含了大量的细节信息...
中间部分有关键的实现细节...
最后总结了核心要点...
"""
chunks = split_document_with_overlap(long_document, chunk_size=512, overlap_ratio=0.15)
# 处理每个chunk时,可以根据position_hint调整Prompt
for chunk in chunks:
if chunk['position_hint']=='middle':
# 对中间片段特别强调
prompt =f"请特别注意以下内容中的关键信息:\n{chunk['text']}\n请仔细提取所有重要细节。"
else:
prompt =f"请分析以下内容:\n{chunk['text']}"
# 调用模型处理
# result = model.generate(prompt)python
除了处理输入数据,Prompt的设计也要考虑位置偏见。重要的指令最好放在开头和结尾重复强调。比如要求模型基于文档回答问题,可以在开头说"请仔细阅读以下文档,严格基于文档内容回答",在文档后面、问题前面再重复一次"请基于上述文档内容回答,不要编造"。这种头尾呼应的方式能显著提高模型的遵循度。很多人习惯把冗长的背景说明、注意事项全堆在Prompt中间,然后发现模型经常忽略那些约束条件,其实就是踩了位置偏见的坑。更好的做法是精简中间部分,把真正的约束条件提到开头或者挪到结尾紧邻输出的位置。
如果项目对长文本处理要求高,模型选型时要特别关注位置编码方案。采用RoPE位置编码的模型,比如LLaMA系列,在长文本任务上的位置偏见相对较轻。ALiBi方案也类似,它通过注意力偏置的方式编码位置,对远距离依赖的衰减更平缓。如果已经在用某个模型,不方便换,那可以关注它支持的最大上下文长度和实际有效长度。很多模型号称支持32K,但实测在16K之后性能就开始明显下降,这时候与其硬塞满整个上下文窗口,不如做好文档筛选和切片,把信息密度提上去。
验证位置偏见最经典的方法是Needle-in-Haystack测试。就是在一堆无关文档里藏一条关键信息,然后改变它的位置,看模型能不能稳定找到。如果开头和结尾的召回率明显高于中间位置,就说明位置偏见比较严重。这个测试不只用来评估模型,也可以用来验证你的缓解策略是否有效。比如实施了文档重排序后,再跑一遍Needle测试,看中间位置的召回率有没有提升。如果提升明显,说明策略起作用了。
defneedle_in_haystack_test(model, tokenizer, max_length=8192, num_tests=100):
"""
针在草堆测试:评估模型在不同位置的信息召回能力
"""
import random
results ={'start':[],'middle':[],'end':[]}
# 关键信息(针)
needle ="重要数据:项目代号是 FALCON-2024,负责人是张伟。"
# 无关文本(草堆)
haystack_template ="这是一段关于技术发展的讨论。"*50
for _ inrange(num_tests):
# 随机选择插入位置
position_type = random.choice(['start','middle','end'])
if position_type =='start':
context = needle +"\n"+ haystack_template
elif position_type =='middle':
half =len(haystack_template)//2
context = haystack_template[:half]+"\n"+ needle +"\n"+ haystack_template[half:]
else:# end
context = haystack_template +"\n"+ needle
# 截断到最大长度
tokens = tokenizer.encode(context, max_length=max_length, truncation=True)
context = tokenizer.decode(tokens)
# 提问
prompt =f"{context}\n\n问题:项目代号是什么?请直接回答项目代号。"
# 调用模型(这里简化处理)
# response = model.generate(prompt)
# is_correct = "FALCON-2024" in response
# 模拟结果(实际使用时替换为真实调用)
is_correct = random.random()>(0.3if position_type =='middle'else0.1)
results[position_type].append(is_correct)
# 统计准确率
for pos_type, outcomes in results.items():
accuracy =sum(outcomes)/len(outcomes)
print(f"{pos_type}位置准确率: {accuracy:.2%}")
return results
# 使用示例
# results = needle_in_haystack_test(model, tokenizer)工程实践中的权衡与监控
位置偏见本质上反映了模型在有限的计算资源下做信息压缩时的优先级选择。如果我们强行消除所有位置偏见,让模型对每个位置都完全平等关注,计算成本会指数级上升,推理速度也会变得不可接受。实际生产环境中,我们往往不是要彻底解决位置偏见,而是要把它控制在业务可接受的范围内。
拿内容推荐举例,如果用户查询历史记录来做个性化推荐,最近的行为数据对推荐结果影响更大,这种对结尾的偏好反而是符合业务逻辑的。但如果是做用户画像分析,需要综合考虑长期行为模式,这时候位置偏见就会导致模型过度关注近期行为而忽略用户的稳定兴趣,那就需要专门处理。这种场景化的思考比简单套用通用方案更有价值。
检测位置偏见最直接的信号是对比不同位置的信息召回率。比如在文档问答系统中,可以定期跑一批标注好的测试样本,刻意把答案线索放在不同位置,统计模型在各个位置区间的准确率分布。如果发现中间位置的准确率持续低于开头和结尾超过某个阈值,就需要介入优化。线上系统可以通过用户行为间接反映位置偏见的影响。比如在智能客服场景中,如果用户频繁追问同一个问题,可能说明模型第一次没有充分利用知识库中间部分的信息。通过分析多轮对话中信息补充的模式,能发现潜在的位置偏见问题。
位置偏见的严重程度和上下文长度不是线性关系。当上下文从4K扩展到8K时,中间位置的性能下降可能只有百分之几;但从16K到32K时,性能下降可能会急剧恶化。这也是为什么很多厂商在宣传超长上下文时,实际应用效果往往没有宣传的那么好。模型能"看到"32K的内容,和能"有效利用"这些内容,是两回事。
最近有些研究在尝试通过上下文压缩来缓解位置偏见,核心思路是把长文档先压缩成密集的语义表示,再喂给模型。这样可以绕过注意力机制对长序列的固有偏见。另一个方向是分层注意力机制,让模型先在局部窗口内做细粒度的注意力,再在全局做粗粒度的信息聚合。这种设计能一定程度上平衡不同位置的信息流动。即使你没真正实现过这些方案,知道这些方向本身就说明你有持续学习的习惯,这在技术面试中是很重要的加分项。
理解位置偏见不只是为了应对面试,更重要的是在实际项目中能够识别这个问题,并根据具体场景设计合理的解决方案。记住,技术的价值不在于追求完美,而在于在约束条件下找到最优的权衡点。