现在谈到AI,恐怕第一个想到的话题就是Agent,无论是最近爆火的龙虾(OpenClaw),还是之前的Manus,本质都是Agent的一种形态。
而在现在的就业市场中,不管是AI相关的面试还是传统的软件开发面试,Agent都已经是一个不得不聊的话题了。
下面让我们一起从考察点解析、标准答案、扩展追问、详细解析和一个Agent的伪代码来回答这道题目。
一、考察点解析
- 理解LLM和Agent区别、边界;
- 熟悉Agent的定义和核心组件;
- 了解Agent落地中的真实挑战;
二、标准答案参考
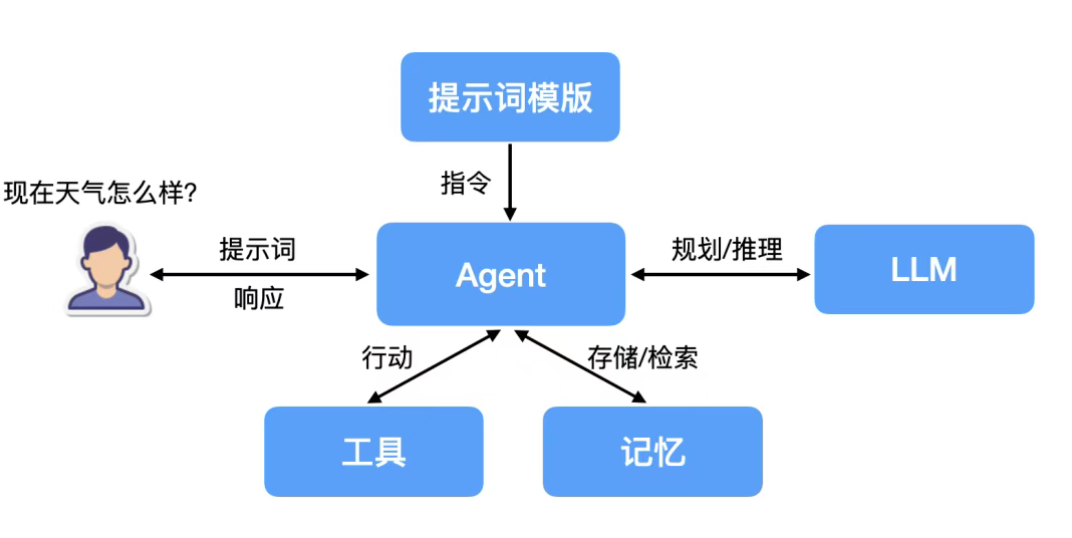
Agent是以 LLM 为核心,具备规划(Planning)、记忆(Memory)和工具调用(Tool Use)能力,能够自主拆解复杂任务、循环执行、感知反馈并持续推进任务直到完成的计算实体,实现从“文本生成”到“任务自主执行”,不再只是被动响应指令,而是能像人类员工一样,自主实现任务闭环。
三、扩展追问
1、Agent和单纯的LLM接口调用(chat)区别是什么?
答:核心在于是否具备实际执行任务的能力,LLM主要是被动接受用户的输入来生成文本回答,主要为一问一答。Agent是设定任务目标、拆解复杂任务、主动调用工具、获取反馈直到完成任务的循环逻辑,LLM只是Agent的大脑,Agent还有手脚(插件/工具/API)和记忆。
补充:现在的Chatgpt、Gemini、豆包等应用本质来说也是Agent,其应用内部封装了一些工具来回答用户的提问。
2、如果Agent在执行中陷入死循环怎么办?
答:这其实是在落地Agent中必须考虑的问题,可以通过设置最大迭代次数、引入反思机制Reflection、人工介入等方式来解决。
3、哪些业务场景适合Agent?
答:本题是开放性题目,回答言之有理即可,参考如下:
- 流程不固定的任务,没有办法通过硬编码来固化工作流,需要 Agent动态决策;
- 多步骤跨工具的任务,一次LLM调用无法完成、需要跨系统、多轮次调用才能完成;
- 需要持续优化的任务,任务结果能被验证,Agent可以通过反馈来调整行动,完成最终的任务目标。
典型场景举例:
- 代码生成、执行、调试(如 Cursor与Claude Code);
- 自动化数据分析报告生成,例如现在非常多的数据平台都在做数据Agent;
- 客服Agent:查订单→判断问题→触发退款→发邮件确认,很多电商相关的业务都在建设这个能力;
四、详细解析
下面来详细解读Agent各个组件的作用:
1. LLM(类似电脑的CPU):决策中心
在大模型出现之前,传统软件靠 if-else 硬编码执行逻辑,在Agent中,LLM 替代了这些规则,负责如下功能:
- 意图理解:读取用户的任务目标
- 任务规划:将复杂任务拆解为多个子任务
- 工具选择:判断当前步骤需要调用哪个工具、传什么参数
- 结果评估:判断当前的输出是否满足目标,决定是否继续
补充:提示词工程(Prompt Engineering)对 Agent 的执行任务结果影响非常大,例如生产环境中Agent 的系统提示词(System Prompt)往往有几百行,包含角色定义、能力边界、输出格式约束、异常处理指引等,后续我也会专门分享提示词工程相关的文章。
2. 规划(Planning):ReAct范式
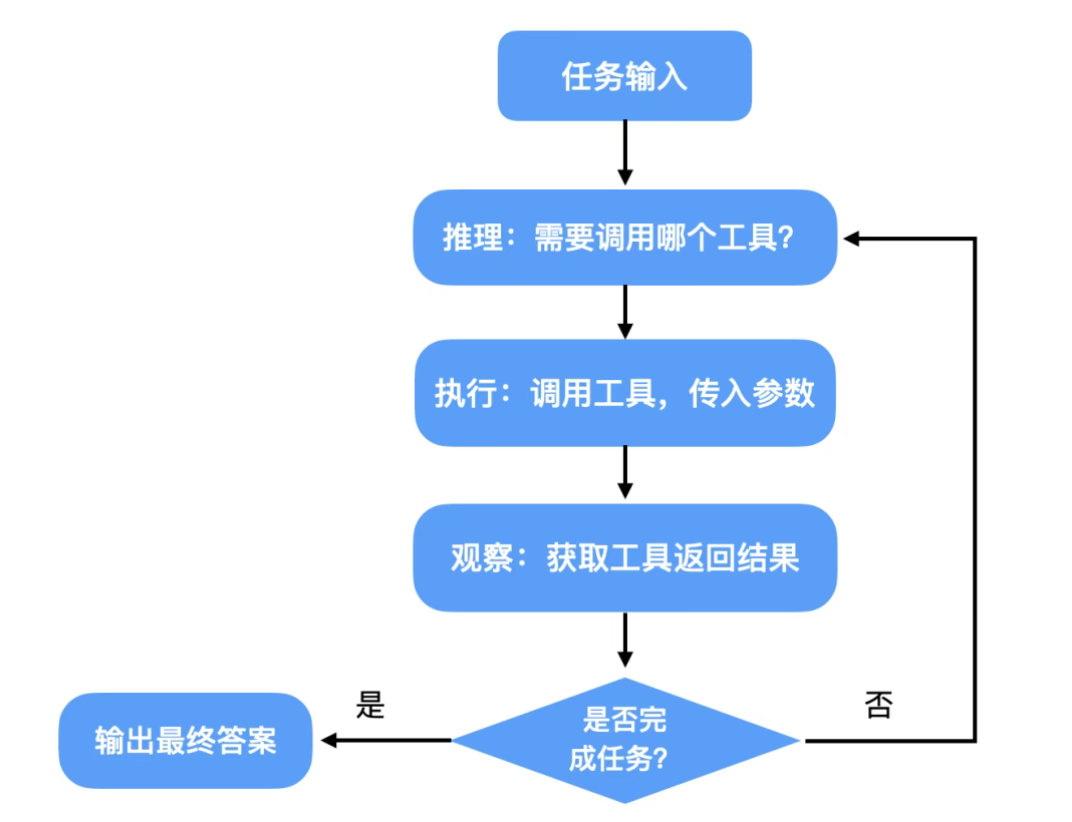
ReAct是Reason(推理)和Act(行动)的缩写,是当前Agent的主流范式,核心流程如上图所示。
当然,ReAct也不是银弹,存在如下局限:
- 依赖LLM的推理能力,如果模型能力弱则效果不好;
- 在长任务中,上下文会快速膨胀(大模型上下文窗口有限),需要在工程上做压缩优化;
- 可能陷入死循环;
后续我也会分享一些其他常见的Agent设计范式(Plan-and-Execute、自我反思Reflextion、Multi-Agent系统)的最佳实践,总的来说,没有万能的Agent设计范式,主要还是需要结合业务场景来选择最合适的Agent设计范式。
3. 记忆(Memory)
Agent的记忆可以简单区分为两种。
短期记忆(Short-term): 利用大模型的 Context Window(上下文窗口)来存储信息,但是上下文都会存在上限(如128K、256K、1M大小),对话多了会丢失最开始的信息。
长期记忆(Long-term): 通过RAG(检索增强生成) 结合向量数据库,Agent把重要的信息“向量化”后再存进数据库,等需要的时候再检索回来放进大模型的上下文窗口中。
实践建议:在实际业务中,对于需要跨会话记忆用户偏好的 Agent,建议将重要结论在每轮结束时主动"总结"后写入长期存储,不要依赖原始对话记录检索。
4. 工具调用(Action):Agent的手和脚
大模型本身只能输出文本,无法联网搜索信息、读写文件、调用外部的API,但是大模型的Function Calling(函数调用) 机制能够以结构化 JSON 的方式"声明想要做的事",然后由外部代码(属于Agent的一部分)真正执行,流程如下:
工具调用在实践中存在以下注意点:
- 最小化权限:工具只开放必要权限,高危操作需要用户二次确认
- 沙箱隔离:代码执行类的工具需要在隔离环境运行,防止宿主机被破坏
- 超时与降级:工具调用设置超时时间,对于工具报错需要做降级处理
- 输出校验:对工具的返回值做格式校验,避免错误数据影响 LLM 的后续推理
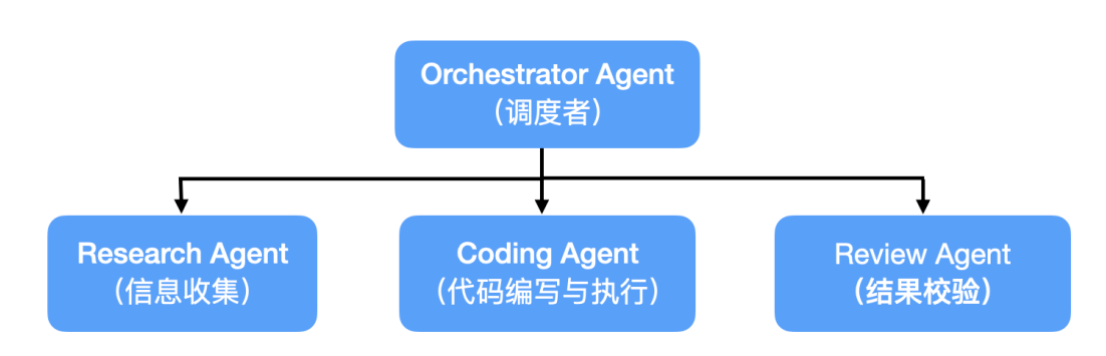
5、Multi-Agent
单个Agent通常能力有限,对于复杂业务可以根据职责的不同设计多个Agent共同写作完成任务, 一个多Agent系统的简单例子如下:
五、Agent伪代码案例
任务场景是用户上传一份CSV销售数据,要求 Agent 自动生成分析报告,核心伪代码非常简单,在真实的企业应用中也主要是在做可靠性和效果优化的工作,示例如下:
// 模拟外部依赖(实际开发中可能是调用 OpenAI 或 LangChain 等 SDK)
// const llm = ...
// const available_tools = [...]
// const execute_tool = async (name, args) => ...
/**
* Agent 执行循环主函数
* @param {string} userGoal - 用户提出的目标
* @returns {Promise<string>} 最终答案
*/
async function agentExecutor(userGoal) {
// 1. 初始化记忆和系统提示词
const memory = [];
const systemPrompt = "你是一个数据分析专家,可以使用文件读取、图表绘制等工具...";
while (true) {
// 2. 将目标、记忆、工具描述发送给 LLM(大模型调用是异步的,使用 await)
const response = await llm.predict({
prompt: `${systemPrompt}\n用户目标: ${userGoal}\n历史记忆: ${JSON.stringify(memory)}`,
tools: available_tools
});
// 3. 解析 LLM 的输出
// 情况 A: LLM 给出了最终答案
if (response.type === "final_answer") {
return response.content;
}
// 情况 B: LLM 决定调用工具 (Action)
if (response.type === "tool_call") {
const toolName = response.tool_name;
const args = response.args;
// 4. 执行工具并获取结果 (Observation)
const observation = await execute_tool(toolName, args);
// 5. 将“思考-行动-观察”全过程存入短期记忆,进入下一轮循环
if (response.thought) {
memory.push(`Thought: ${response.thought}`);
}
memory.push(`Action: ${toolName}(${JSON.stringify(args)})`);
memory.push(`Observation: ${JSON.stringify(observation)}`);
}
}
}