精炼回答
知识图谱和大模型的结合主要有三种模式。第一种是把图谱作为外部知识库,在推理时通过实体链接和关系检索来增强模型输出,比如问"阿司匹林治什么病",先从问题中识别出"阿司匹林"实体,然后去医学知识图谱里查它的适应症关系,把这些结构化知识和原问题一起喂给大模型生成答案。第二种是用图谱来微调或预训练模型,把三元组转成文本或者直接用图神经网络编码图结构,让模型学习实体间的关系模式。第三种是让大模型生成或补全图谱,用模型的常识推理能力来做知识抽取和关系预测。
在RAG场景下用图谱会比单纯的向量检索更精准。传统RAG是把文档切片后做向量相似度匹配,容易召回不相关的内容。如果引入图谱,可以先做实体识别和图查询,沿着关系路径精确定位到相关知识子图,比如查"某药物的副作用和禁忌人群",能通过图谱的has_side_effect和contraindication关系直接找到答案节点,然后再结合这些节点关联的文档片段生成回答,这样既保证了知识的准确性,又能追溯来源。实际应用中像金融风控、医疗问诊这种需要严格逻辑推理的场景特别适合这么做。
扩展分析
从面试角度看这个问题
面试时可以这样开场:"知识图谱和大模型的结合,我理解主要是解决大模型的幻觉问题和知识时效性问题。结合方式大概分三个方向:一是把图谱当外部知识源在推理时动态查询,二是把图谱知识融入模型训练过程,三是反过来让大模型帮助构建和补全图谱。在RAG场景里,图谱的价值特别明显,因为它能提供结构化的关系查询能力,这比纯向量检索要精准得多。"
这么说的好处是,你先把问题拆成了"如何结合"和"RAG中怎么用"两个部分,面试官能立刻感受到你的思路是清晰的。同时你点出了"解决幻觉和时效性"这个核心痛点,说明你不是在背答案,而是理解了为什么要做这个结合。接下来不管面试官让你展开哪个点,你都有准备好的后续内容可以接住。记住给出这个框架后稍微停顿一下,观察面试官的反应,他可能会直接让你重点讲某一块,这样比你自己滔滔不绝讲完所有内容更高效。
深入分析:图谱增强推理的核心机制
当面试官让你展开"结合方式"时,你可以从最实用的图谱增强推理讲起。最常见的方式是把知识图谱作为外部记忆,大模型负责理解问题和生成答案,图谱负责提供精确的事实依据。说到这里别着急往下走,先解释清楚工作流程。用户提问进来后,系统会先做实体识别和链接,把问题中的关键实体映射到图谱节点上,然后通过关系查询找到相关的知识子图,最后把这些结构化信息和原问题一起送给大模型。
这里的关键点是"结构化信息"这四个字,面试官会很在意你有没有意识到图谱和文档的本质区别。图谱里存的不是一段段文字描述,而是"实体-关系-实体"这种三元组,比如"阿司匹林-治疗-心血管疾病"就是一条明确的知识链路,不存在理解歧义。
如果面试官追问"为什么不直接把这些知识写成文档让大模型学",你就要点出图谱的独特优势了。图谱的价值在于它把隐式的知识关系变成了可计算的结构。举个容易理解的例子,假设在金融风控场景里,需要判断某个企业的风险等级。如果只靠文档,可能需要从几十篇报道、财报、公告里提取信息,而且这些信息散落在不同句子里——"A公司持股B公司30%"在一篇文章,"B公司CEO是张三"在另一篇,"张三涉及某起诉讼"又在第三篇。传统RAG可能检索到这三段文本,但大模型得自己推理出"A公司间接关联了一个有法律风险的人"。而图谱直接存储了"A公司-持股-B公司"、"B公司-法人-张三"、"张三-涉诉-某案件"这些关系,查询时可以通过图遍历一次性拿到完整的关联路径,精度和效率都更高。

讲完推理增强后,如果时间允许,可以简单提一下另外两种范式。另一个方向是把图谱知识注入到模型训练阶段,比如把三元组转成自然语言"阿司匹林可以治疗心血管疾病"加入预训练语料,或者用图神经网络编码实体的邻居关系作为额外的embedding。这种方式的好处是推理时不需要额外的查询开销,但缺点是知识更新成本高,图谱一变就得重新训练。
RAG场景下的图谱应用
现在进入RAG这个重点战场。图谱不是在跟向量检索打擂台,而是在解决不同层面的问题。传统的向量RAG解决的是语义相似性匹配问题,而图谱RAG解决的是知识关联性推理问题。这句话说完立刻举个对比例子。假设用户问"iPhone 15和小米14哪个续航更好",向量检索可能召回两篇评测文章,里面分别提到"iPhone 15电池容量3877mAh"和"小米14续航测试8小时",但这两段信息没法直接对比。如果有商品知识图谱,存储了"iPhone 15-电池容量-3877mAh-续航时间-7.5小时"和"小米14-电池容量-4610mAh-续航时间-8小时"这样的结构化属性,查询时可以直接提取对应字段,让大模型基于可对比的数据生成答案,而不是让模型自己去理解"8小时"和"3877mAh"哪个更好。
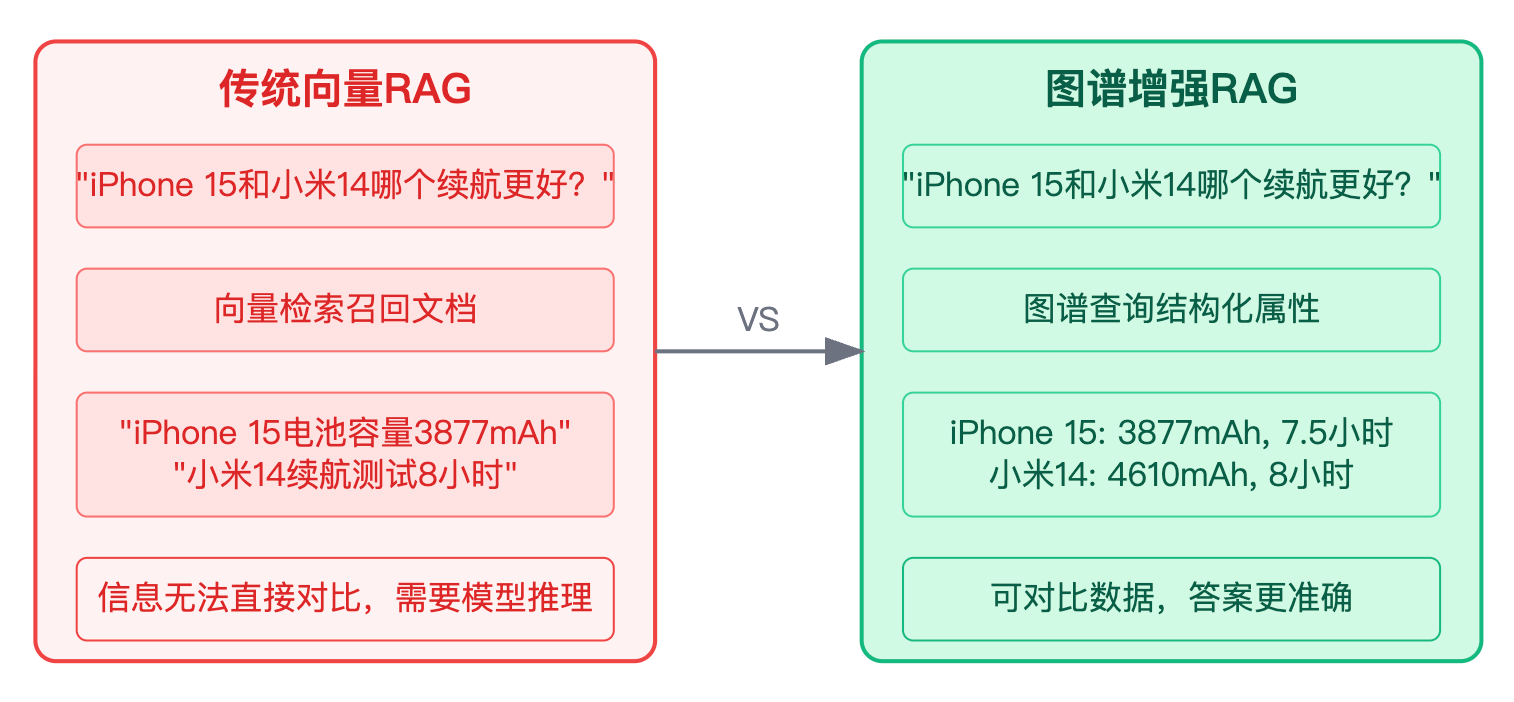
这时候如果面试官问"那是不是图谱就完全替代向量检索了",你得赶紧澄清误解。实际应用中两者更多是互补关系。图谱适合处理明确的事实查询和多跳推理,比如"某药物的禁忌症患者能吃什么替代药",需要先查药物的禁忌关系,再查替代品的适应症关系。但如果问题是"如何缓解焦虑情绪"这种开放性问题,图谱里可能没有直接的关系边,这时候向量检索反而能召回相关的经验类文档。现在比较成熟的做法是双路召回,对问题同时做实体识别触发图谱查询,也做向量检索召回文档片段,然后用rerank模型或者规则策略把两路结果融合后再给大模型。
引入图谱主要解决三个痛点:一是幻觉问题,因为图谱里的三元组是人工或者经过验证的知识,不像大模型可能瞎编;二是时效性问题,图谱可以实时更新,不需要重新训练模型;三是可解释性,通过图谱的关系路径能追溯答案来源,比如回答"为什么推荐这个药"时可以展示"症状-关联-疾病-治疗-药物"这条推理链。这三点说完面试官基本能判断你是真懂还是背题。
实践落地的工程经验
前面讲了这么多理论框架,现在得落到具体怎么做上。面试官如果对你的理解满意,很可能会追问"你觉得这套东西在实际项目里怎么用",这时候就是展现你工程思维的时候。记住别上来就甩架构图,先说清楚你怎么判断一个场景适不适合用图谱增强的RAG。
我会先看业务特征来判断是否引入图谱。如果业务问题涉及明确的实体关系,比如金融领域查"某家公司的实际控制人有哪些关联企业",或者医疗场景问"高血压患者不能吃哪些感冒药",这种需要沿着明确关系链路查询的场景特别适合。反之如果是开放式的内容生成,像写营销文案或者做情感分析,图谱就不一定能发挥太大作用。
拿智能客服举例会比较好讲。假设做电商售后客服系统,用户问"买的空调不制冷怎么办"。传统向量检索可能召回一堆维修文档,但里面混杂着不同型号、不同故障的处理方法,大模型得从一大堆文本里提取信息。如果构建了商品知识图谱,存储了"空调型号-常见故障-解决方案"这样的关系,还有"故障现象-可能原因-检查步骤"这种诊断链路,查询时就能先识别出用户购买的具体型号,然后通过"不制冷"这个症状节点,沿着诊断关系找到对应的排查流程。这样做的好处是能保证答案的准确性,因为每个型号的处理步骤是经过验证的结构化知识,不会出现大模型把A型号的方法用到B型号上的情况。
publicclassKnowledgeGraphRAG{
privateGraphDatabase graphDB;
privateVectorStore vectorStore;
privateLLMClient llmClient;
publicStringanswer(String query){
// 第一步:实体识别和链接
List<Entity> entities =extractEntities(query);
List<Entity> linkedEntities =linkToGraph(entities);
// 第二步:双路检索
CompletableFuture<GraphResult> graphFuture =
CompletableFuture.supplyAsync(()->queryGraph(linkedEntities, query));
CompletableFuture<List<Document>> vectorFuture =
CompletableFuture.supplyAsync(()-> vectorStore.search(query,5));
// 第三步:结果融合
GraphResult graphResult = graphFuture.join();
List<Document> docs = vectorFuture.join();
String context =mergeResults(graphResult, docs);
// 第四步:构建Prompt并生成答案
String prompt =buildPrompt(query, context, graphResult.getReasoningPath());
return llmClient.generate(prompt);
}
privateGraphResultqueryGraph(List<Entity> entities,String query){
if(entities.isEmpty()){
returnGraphResult.empty();
}
// 生成Cypher查询(以Neo4j为例)
String cypherQuery =generateCypherQuery(entities, query);
// 执行查询并裁剪子图
RawGraphData rawData = graphDB.execute(cypherQuery);
returnpruneSubgraph(rawData, maxNodes =20);
}
privateStringmergeResults(GraphResult graphResult,List<Document> docs){
StringBuilder context =newStringBuilder();
// 图谱结果优先,给予更高权重
if(graphResult.isNotEmpty()){
context.append("## 结构化知识:\n");
for(Triple triple : graphResult.getTriples()){
context.append(String.format("- %s %s %s\n",
triple.subject, triple.predicate, triple.object));
}
}
// 补充文档片段
context.append("\n## 相关文档:\n");
for(Document doc : docs){
context.append(doc.getContent()).append("\n");
}
return context.toString();
}
privateStringbuildPrompt(String query,String context,List<String> path){
returnString.format(
"基于以下知识回答问题。如果使用了图谱知识,请说明推理路径。\n\n"+
"问题:%s\n\n知识:\n%s\n\n推理路径:%s\n\n答案:",
query, context,String.join(" -> ", path)
);
}
}整个系统分三个阶段,查询改写、图谱检索和结果融合。
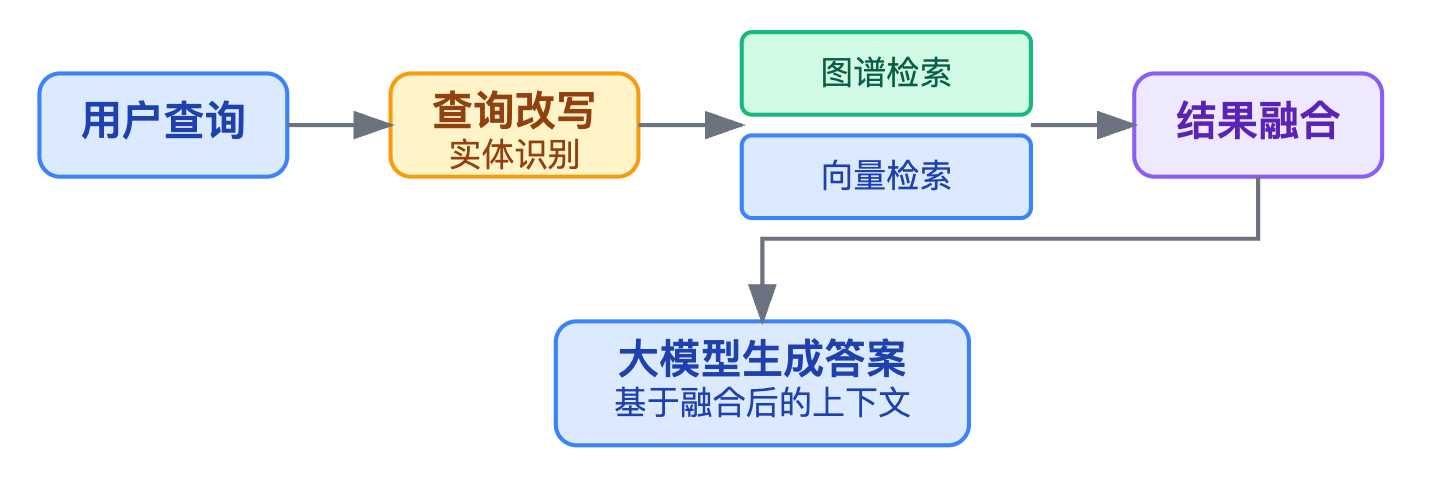
先说查询改写,用户的原始问题通常不是标准的图谱查询语句,需要先做实体识别和意图理解。我们会用命名实体识别模型提取出关键实体,比如从"这款手机拍照效果好不好"里提取出具体的商品名称,然后做实体链接,把口语化的"这款手机"映射到图谱里的商品节点ID。这里如果面试官问实体链接怎么做,你可以说基于编辑距离加上上下文embedding的相似度打分,选择置信度最高的候选实体。
图谱检索这块要说清楚怎么生成查询语句。拿到实体和意图后,需要把自然语言问题转成图查询语言,比如SPARQL或者Cypher。这个转换过程现在通常有两种做法,一种是基于规则模板,针对常见的问题模式预先定义好查询模板,比如"X的Y是什么"这种模式对应的查询就是从X实体出发沿着Y关系找目标节点。另一种是用大模型直接生成查询语句,给模型提供图谱的schema和几个示例,让它输出结构化的查询代码。生成查询后还不能直接执行,得做子图裁剪。因为一个实体可能连着几百条关系边,全返回的话context会爆炸,通常会根据关系类型的重要性打分,只保留topK的邻居节点。
讲到这里可以提一个关键的工程问题,就是混合检索怎么做融合。实际项目里我们会同时跑图谱查询和向量检索两路召回,然后用打分机制做融合。图谱召回的结果因为是结构化的,可以给个基础置信度比如0.8,向量检索的结果根据相似度得分动态调整权重。最后把两路结果按得分排序后截断,控制总token数在大模型的窗口范围内。说完这个可以提一下踩过的坑:有个常见问题是图谱查询可能返回空结果,比如用户问的实体图谱里压根没有,这时候得有降级策略,直接切到纯向量检索模式,不能让系统卡住。
最后面试官可能会问怎么评估效果。我们会拆分几个指标来看,不能只盯着一个准确率。具体指标包括实体识别的准确率和召回率,这个直接影响能不能触发图谱查询;图谱召回的命中率,就是有多少比例的问题能从图谱里找到答案;还有最终答案的质量,这个可以用人工标注一批case做对比,看引入图谱后事实性错误是不是减少了。上线时我们会做小流量灰度,比如10%的流量走图谱增强的RAG,90%走基线的纯向量方案,观察答案采纳率和用户满意度打分,如果图谱版本的满意度显著更高才会全量放开。