精炼回答
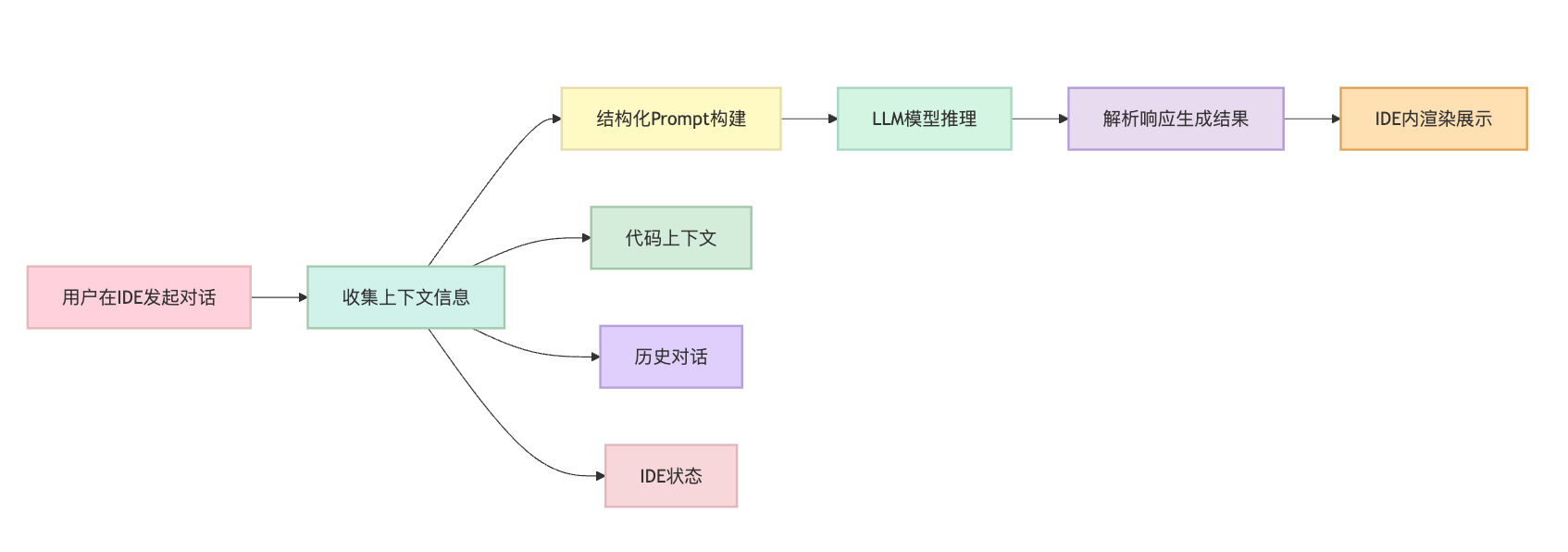
Copilot Chat 的实现核心是将 IDE 上下文信息与大语言模型结合。当你在 IDE 里发起对话时,它会收集当前的代码上下文,包括光标所在文件、选中代码片段、打开的文件列表、项目结构等信息,把这些作为 prompt 的一部分发送给后端的 LLM(如 GPT-4)。
具体来说,IDE 插件会通过 Language Server Protocol 获取代码的语法树、符号信息、类型定义等结构化数据,再结合你的自然语言问题构建完整的请求。比如你选中一段函数问"这段代码有什么问题",它会把函数代码、所在类的定义、相关依赖一起打包发送,让模型理解完整语境后给出针对性回答。
对话式编程的关键是维持上下文连贯性。每轮对话都会记录历史消息,形成对话链,这样你可以追问"帮我优化一下"而不需要重复说明是哪段代码。同时插件会监听 IDE 事件,当你切换文件或移动光标时,自动更新上下文引用。返回结果时,Copilot Chat 会解析模型输出中的代码块,提供直接插入、应用到文件的快捷操作,还能生成 diff 预览。这种从代码理解到代码生成的闭环,让你可以用自然语言驱动整个编码流程,而不只是简单的问答。
扩展分析
从用户操作到模型响应的完整链路
理解 Copilot Chat 的架构,最好的方式是沿着一个真实的用户操作路径来看整个数据流。假设你在 VSCode 里选中一段支付接口的代码,问 Copilot Chat "这段代码有线程安全问题吗",整个请求链路可以分成三层来理解:最前端是 IDE 插件层,负责捕获开发者的编辑行为和代码上下文;中间是上下文编排层,要把分散的代码信息结构化成 LLM 能理解的 prompt;最后是模型推理层,调用 GPT-4 这类大模型生成回复,再通过插件反向渲染到 IDE 界面。
当你选中代码那一刻,插件会注册的 onDidChangeTextEditorSelection 钩子立刻触发,同步拿到选区的起止位置和完整文本。但光有文本还不够,模型需要知道这个函数调用了哪些依赖、返回值类型是什么,这些语义信息得通过语言服务器获取。插件会发送 textDocument/documentSymbol 请求,拿回当前文件的符号表,包括类定义、方法签名、变量作用域等结构化数据。如果代码里调用了其他模块的类,还会通过 textDocument/definition 找到定义位置,把相关文件的片段也拉进来。这就是 Language Server Protocol 的价值所在,它让插件能够跨语言地获取代码的语义信息,而不只是把代码当成纯文本处理。
上下文采集这一步有个关键的权衡问题。上下文越多模型理解越准确,但 token 成本和响应延迟会线性增长。实际实现会做上下文剪枝,比如只取当前文件的全量代码、光标所在函数的调用链上游 3 层、最近编辑过的 5 个文件的摘要信息。如果你打开了 20 个标签页,不会全部塞进去,而是根据编辑时间和文件类型排序,优先保留相关性高的。在电商系统里,比如你正在改订单服务的代码,那库存服务的接口定义可能就比前端页面代码更相关,这种优先级判断其实可以通过文件依赖图来做。
收集到的上下文不能直接扔给模型,需要按模板组装。系统提示词会先声明角色,比如 "You are an expert code reviewer",然后注入代码上下文的时候要加标记,像用 <current_file> 标签包裹当前文件、<selection> 标注选中的代码块。用户的问题会放在最后,前面还要插入历史对话记录,但不能无限堆积,一般保留最近 3 轮的 Q&A 对,超过的话会做摘要压缩。这就是 Prompt 工程的艺术,很多候选人会忽略这个环节,但这恰恰是系统智能的核心。
现在更先进的做法是在 Prompt 里加入意图识别层,先让一个小模型判断用户是在问 bug、要重构、还是写测试,然后动态调整系统提示词。比如识别到是性能优化意图,就会额外注入当前函数的调用频率、运行时 profile 数据这些 IDE 插件能拿到的遥测信息。这种分层 Prompt 策略,比把所有信息平铺给模型效果好很多。
后端服务的架构设计也很讲究。Gateway 层主要做鉴权和限流,真正的业务逻辑在上下文处理器里。这个模块会把插件发来的 JSON 结构展开,代码片段需要做语法检查,避免发给模型的是半截代码导致理解偏差。然后是 Prompt 构建,这里会查询一个模板库,根据用户的意图类型选择不同的提示词模版。比如你问的是"写单测",就会加载包含测试框架最佳实践的系统提示。
关于对话状态管理,这涉及到分布式系统的经典问题。每个用户会话会生成一个 session_id,后端用 Redis 存储这个 session 的上下文栈。栈里不仅有历史消息,还会记录上下文锚点,就是每轮对话关联的代码位置。比如第一轮你问了 A 函数的问题,第二轮追问"那依赖的 B 方法呢",这时候需要知道 B 是第一轮上下文里提到的。这个关联关系会存成图结构,节点是代码符号,边是对话中的引用关系。会话隔离也很重要,如果你同时打开两个 Chat 窗口问不同模块的问题,它们的上下文不能混,所以 session 要跟 IDE 的窗口实例绑定,而不是用户账号级别的全局状态。
调用大模型 API 时会开启 stream 模式,每生成几个 token 就通过 Server-Sent Events 推给前端,这样用户能看到逐字输出的效果。但流式响应有个技术细节要处理,就是代码块可能被分割传输,前端收到 ````java` 的时候后面的代码还没到,需要有个流式解析器缓存不完整的代码块,等闭合标签到了再渲染成可交互组件。
最后说说代码理解能力,这是 Copilot Chat 比普通聊天机器人强的地方。插件层拿到的 AST 是语法树,能知道这是个函数调用,但不知道这个函数是干嘛的。真正的代码理解发生在模型侧,比如你的支付代码里有个 lockInventory() 调用,模型结合上下文能推断出这是分布式锁操作,然后在回答线程安全问题时会重点分析锁的持有时长。这种能力来自模型的预训练语料库,它见过海量的开源代码和文档。2025 年有些团队开始尝试私有代码库的向量检索增强,把公司内部的代码规范、历史 bug 修复案例都入库,查询时先向量检索出最相关的案例再给模型,这样回答更贴合团队实际情况。这其实就是 RAG 模式在代码域的应用。
值得一提的是,Copilot Chat 和自动补全是两个完全不同的东西。自动补全是预测式的,在你打字的时候根据前文预测下一行代码,上下文范围通常是当前函数加最近几行。响应要在 300 毫秒内返回,所以用的是蒸馏后的小模型,只生成单行或代码片段。而 Copilot Chat 是交互式的,你明确提出需求,它可以生成整个类的实现、重构多个文件、甚至解释复杂的调用链。上下文可以跨文件、跨模块,响应时间允许到几秒,因为用的是 GPT-4 这种大模型。本质上,一个是代码编辑器的智能提示增强,一个是对话式的开发助手。
从使用到自建的工程实践
理解了原理,再看怎么用好这个工具就清晰多了。Copilot Chat 本质上是把那些原本需要跳出 IDE 去做的事情内化到编辑器里。比如你在读一段复杂的递归算法,以前可能要打开浏览器搜索相关概念、去文档站查 API 用法,现在直接选中代码问它"这个算法的时间复杂度是多少"就能拿到针对当前实现的分析。更实用的场景是代码审查,当你看到同事提交的代码不太理解时,选中那段代码问"这里为什么要这样处理",它会结合上下文给出解释,这比盲目猜测或者等对方回复要高效得多。
但很多人把 Chat 当搜索引擎用,直接问"怎么写单例模式",这样其实浪费了它理解上下文的能力。更好的做法是先选中你已经写了一半的代码,然后问"帮我把这个类改成线程安全的单例",这时候它能看到你的类结构、依赖注入方式、甚至项目用的并发框架,生成的代码就能直接用,而不是给你个教科书式的抽象例子。
上下文采集还有个窍门,如果你的问题涉及多个文件的交互,比如想问"为什么这个接口调用失败了",最好先把接口的定义文件和调用方代码都打开放在编辑器标签页里,然后在调用的地方选中那行代码发起提问。插件会自动把打开的相关文件也纳入上下文,这样模型能看到完整的调用链路。如果只打开调用方的文件,它可能只能基于方法签名做推测,准确性就差一些。
如果要在公司内部实现一个类似的工具,首先要明确是做成 IDE 插件还是 Web 版的代码助手,这决定了架构差异。如果是插件形式,VSCode 的 Extension API 比较成熟,可以直接基于 LSP 协议拿代码结构数据,但要处理好插件和主进程的通信性能问题。如果是 Web 版,需要自己实现代码编辑器,Monaco Editor 是个选择,但很多 LSP 的能力要自己补。
模型选择是 2025 年的重点方向。如果预算足够可以直接接 GPT-4 或者 Claude 3.5 的 API,但要注意做好速率限制和成本控制,一个活跃用户一天可能产生几百次请求。如果要控制成本,可以考虑混合策略:简单的代码解释用开源的 CodeLlama 或者 DeepSeek Coder 这种垂直模型,复杂的架构分析和重构建议再调用大模型。还有个思路是本地部署量化后的模型,比如把 Qwen-Coder 量化到 4bit 跑在开发机上,响应快而且数据不出本地,这对安全要求高的团队很重要。
实际运行时最大的瓶颈是模型推理延迟,几秒的等待会打断开发思路。几个优化方向可以同步推进:做好缓存,相同的代码片段加相同的问题可以直接返回缓存结果,用代码的哈希值加问题文本做 key;上下文的增量更新,如果用户在同一个文件里连续提问,不用每次都重新解析整个文件的 AST,只需要 diff 变更部分;流式响应一定要做,哪怕后端模型还在推理,前端也能先把已生成的内容渲染出来,这个体验提升很明显。
企业部署最担心的就是把内部代码发给第三方 API。有几个方案可以组合:一是在发送前做代码脱敏,把变量名、函数名替换成占位符,只保留代码结构发给模型,拿到回答后再反向替换回来。但这会损失一些语义信息,效果会打折扣。更彻底的方案是私有化部署,在公司内网搭建模型推理服务,数据不出内网。现在开源模型的能力已经能覆盖大部分场景,DeepSeek V3 这种千亿参数的模型做量化后,几张 A100 就能跑起来,对大公司来说这个成本是可以接受的。
现在有些团队开始尝试把 Copilot Chat 和 RAG 结合,构建基于企业知识库的代码助手。具体做法是把公司的代码规范文档、历史 bug 修复记录、内部技术分享都向量化存到检索库里,当开发者提问时先做向量检索,把最相关的内部案例和规范作为上下文注入给模型。比如问"怎么处理分布式事务",它不会给你教科书式的答案,而是返回你们公司订单系统里已经验证过的方案,甚至能告诉你哪些坑之前踩过。这种私域知识增强的方式,能让通用模型快速适配特定团队的开发习惯。
对开发范式的深层影响
Copilot Chat 本质上是在推动编程从指令式转向声明式,开发者越来越像是在表达意图而不是编写指令。这个趋势延伸下去,IDE 会演化成 Agent 化的工作台,你说"帮我优化这个查询的性能",它不只是给建议,而是直接运行压测、分析慢查询日志、生成索引优化方案,甚至提交 Pull Request 让你 review。这不是科幻,2025 年已经有团队在做这样的尝试。
如果在团队推广这类工具,会遇到三个层面的挑战。首先是心理层面的接受度问题,很多资深开发者会担心 AI 生成的代码质量不可控,这时候需要用数据说话,比如先在测试用例生成这种风险可控的场景试点,统计覆盖率提升了多少、bug 修复效率提高了几成,用量化指标打消疑虑。然后是技术层面,代码隐私是企业最关心的点,可以先部署一个基于开源模型的内网版本,把敏感代码的审计日志都留在本地,等团队习惯了工作流程再考虑接入更强的商业模型。最后是流程层面,需要制定代码 review 的新规范,AI 生成的代码必须标注来源、人工审核通过才能合并,这样能保证质量的同时让团队逐步建立信任。
往更远的方向看,多模态输入会是下一个爆发点。现在输入只能是文本和代码,但已经有团队在尝试让开发者直接画架构图、框出 UI 原型,IDE 通过视觉理解生成对应的代码骨架。这种多模态交互会让需求到实现的链路更短。还有 Agent 协作的方向,单个 Chat 窗口的能力是有限的,未来可能是多个专业 Agent 的编排,一个负责理解业务逻辑、一个做代码生成、一个跑测试验证,它们之间通过结构化的消息协议交互,开发者只需要把控整体方向。
不过这些前沿探索现在还在实验阶段,工程化落地的关键还是要解决好响应速度、成本控制、可解释性这些基础问题。技术趋势可以畅想,但脚踏实地的工程能力才是把想法变成现实的基础。这也是为什么理解 Copilot Chat 的实现原理如此重要,因为只有真正懂了底层逻辑,你才知道该在哪些点上发力,才能在下一波 AI 辅助开发的浪潮里站稳脚跟。