精炼回答
大模型的长文本能力在参数上很吸引人,动辄支持128K甚至200K的上下文窗口,但实际表现和理想状态差距不小。核心问题在于虽然模型能"装得下"这么长的文本,但真正理解和利用的能力会随着长度增加而明显衰减,特别是对文本中间部分的信息捕捉很不稳定。
"大海捞针"测试就是专门用来评估这个能力的标准方法,设计思路很直观:在一段长文本的不同位置插入一句特定的关键信息(就像在大海里藏一根针),然后让模型去找这句话。通过改变插入位置的深度和文本的总长度,就能画出一张性能热力图。测试结果往往显示出明显的U型曲线,模型对开头和结尾部分的信息关注度高,而对中间部分的召回率会明显下降,有时候甚至降到60%以下。
实际工程中这意味着什么?举个接地气的例子,电商场景下用户咨询时可能上传长篇商品对比文档,如果直接喂给大模型,中间部分的关键诉求很可能被忽略,导致客服回复答非所问。或者代码审查时让模型分析一个5000行的PR,它可能只关注开头的接口定义和结尾的测试用例,中间的核心逻辑变更反而看漏了。所以实际项目中我们会用分块策略、滑动窗口或者RAG检索增强来规避这个短板,而不是盲目依赖模型的长上下文能力。
扩展分析
从注意力机制理解长文本难题
要真正理解大模型为什么会在长文本上表现不佳,得从Transformer的注意力机制说起。这个机制的核心是计算每个token和其他所有token之间的关系,也就是说当上下文长度翻倍时,计算量会是原来的四倍。但更关键的问题不在计算量,而在信息密度。想象一下,当我们把上下文从4K扩展到100K甚至更长时,模型需要在海量token中分配注意力权重,就像一个人同时关注一百件事,结果往往是每件事都关注得不够深入。
这不是简单的技术参数问题,而是架构本身带来的取舍。注意力机制的计算复杂度是O(n²),当序列长度增加时,梯度传播的路径会指数级增长,模型很难真正学会在超长序列中保持稳定的信息提取能力。这就是为什么业界后来出现了Sparse Attention、Sliding Window这些变体架构,都是在试图缓解这个根本性矛盾。
"大海捞针"测试的设计者很清楚这一点。如果模型连找一句明确的事实信息都做不好,那它处理真正的长文档推理任务就更不可能靠谱。测试中会在不同位置插入一句特定格式的话,比如"魔法城市的秘密数字是42",然后让模型回答这个数字是什么。这个任务看起来简单,实际上精准地暴露了模型的薄弱环节。
位置维度特别关键,因为大量实验发现模型对文本开头和结尾的注意力天然更高,这可能和训练语料的特点有关,重要信息往往在文章首尾。所以测试会把目标信息分别放在文本的前10%、25%、50%、75%、90%这些位置,看看模型在哪个区间表现最差。通常你会看到一个明显的凹陷区域,中间部分的召回率显著下降。
长度维度同样值得关注。测试会从几千tokens逐步增加到模型声称支持的上限,比如32K、64K、128K。有意思的是,很多模型在前一半长度范围内表现还可以,但超过某个临界点后性能会断崖式下跌。这说明厂商宣传的最大上下文长度和实际可用长度是两回事,就像手机电池标称5000mAh,实际可用容量可能只有4000mAh。
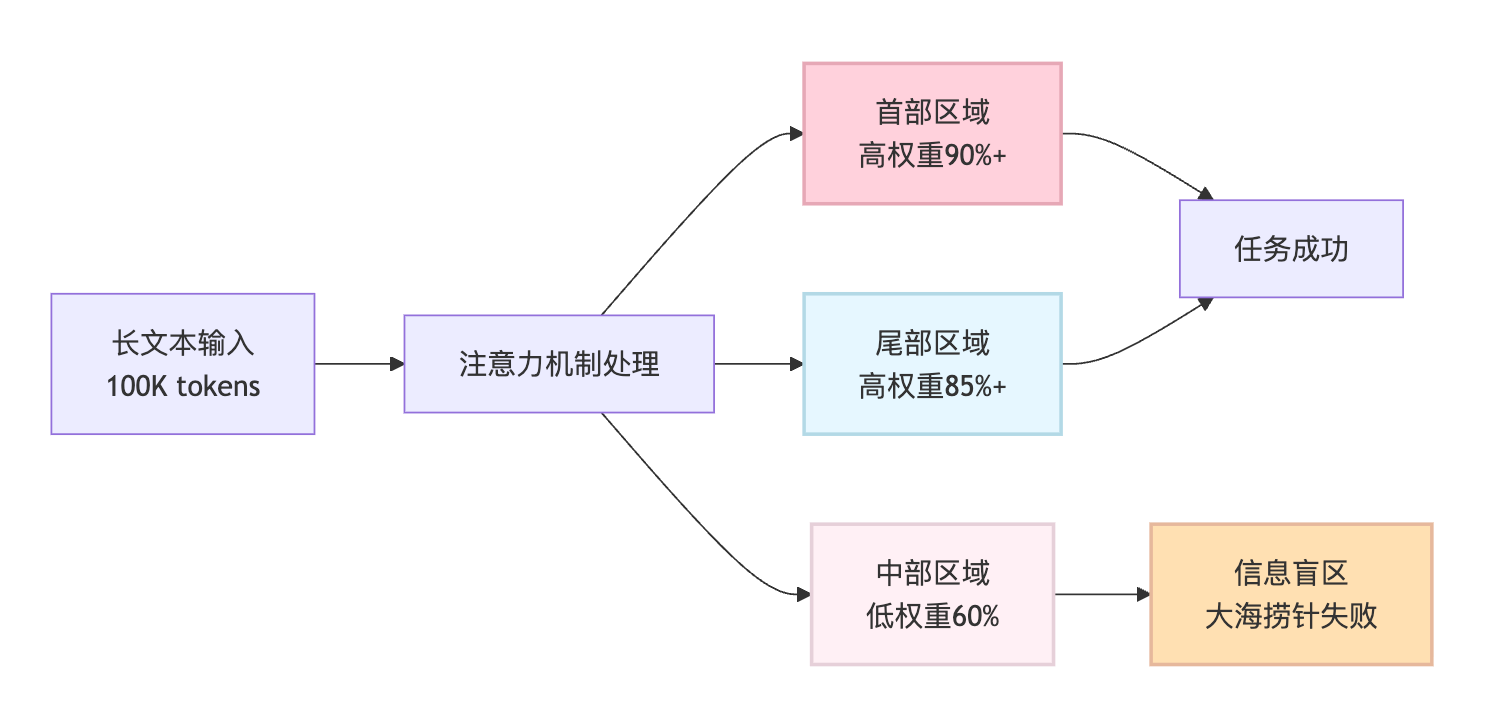
测试结果通常会画成热力图,横轴是文本长度,纵轴是插入位置,颜色深浅代表准确率。一个理想的模型应该整张图都是深色(高准确率),但实际上你会看到中间区域有明显的浅色带,那就是模型的"盲区"。早期的GPT-3即便扩展到32K上下文,大海捞针测试的中部召回率也只有60%左右。后来Claude 2通过改进位置编码方式,在100K上下文下中部区域能维持在85%以上。GPT-4 Turbo宣称支持128K,但实测发现超过64K后性能衰减还是比较明显。这些差异背后是位置编码策略、注意力窗口设计、训练目标函数的不同选择。
拿法律合同分析来说,假设一份50页的合同,关键的免责条款藏在第30页中间,用户问"这个合同里我有哪些免责情况",如果直接把整份合同扔给模型,它很可能抓取开头的总则和结尾的签字页,把中间那条关键信息漏掉,给出的答案就是不完整的。或者技术文档总结场景,当你让模型总结一份200页的系统设计文档,它可能会很好地概括第一章的背景介绍和最后一章的部署方案,但第五章到第八章的核心架构设计反而被忽略。这就是为什么很多团队发现直接用长上下文模型处理大文档,效果还不如先做好内容拆分。
有个常见误区需要澄清:单纯增加训练数据中的长文本比例并不能根本解决问题。注意力机制的计算复杂度摆在那里,梯度传播的路径会指数级增长,模型很难真正学会在超长序列中保持稳定的信息提取能力。这是个架构层面的根本性约束,需要新的技术范式来突破,就像当年从RNN到Transformer的跨越一样。
工程实践中的应对策略
理论讲了这么多,实际项目中该怎么办?最容易踩的坑就是看到某个模型支持100K上下文,就想着直接把长文档全部塞进去。实际测试下来会发现,即使长度没超限制,模型对中间部分的信息捕捉还是不够稳定。所以工程上更靠谱的做法是主动做文档切分,而不是依赖模型自己去处理超长序列。
处理长文档时,最朴素的做法是按固定长度切块,比如每2000个token一段。但这样经常会把语义完整的段落切断,导致上下文丢失。更好的办法是结合文档结构来切分:技术文档按章节标题切,客服对话记录按会话轮次切,法律合同按条款编号切。这种基于语义边界的切分能保证每个块内的信息相对完整。
拿产品说明书问答来说,用户可能会问"这款手机的电池容量是多少"。如果说明书有50页,直接全文输入模型,它未必能准确定位到规格参数那一章。实际项目中会先对文档做预处理,提取章节结构,给每个段落打上标签。当用户提问时,先通过关键词匹配或者语义检索找到最相关的几个段落,然后只把这些段落送给模型去生成答案。
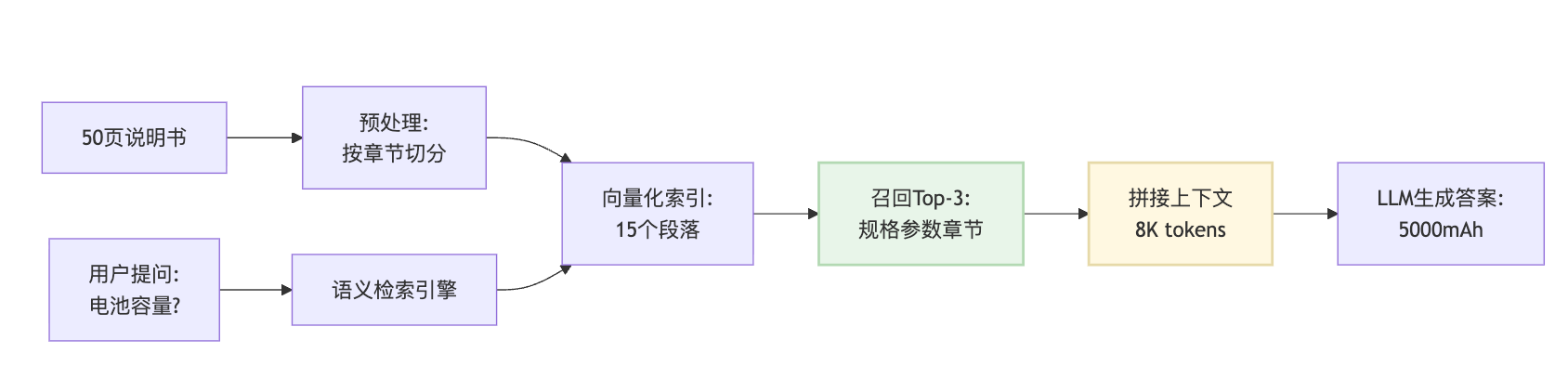
这种设计其实是在规避大海捞针测试暴露出来的问题。与其让模型在50页文档里大海捞针,不如先用检索系统把相关的三五段内容筛出来,然后让模型在这个小范围内精准作答。召回的段落总长度控制在8K到16K之间,正好落在模型表现最稳定的区间。
这里有个实践细节很重要:检索回来的段落可能来自文档的不同位置,直接拼起来送给模型时要注意顺序。因为大海捞针测试告诉我们,模型对开头和结尾的关注度更高,所以相关性最强的段落最好放在开头,次相关的放中间。如果把最关键的信息埋在拼接文本的中部,模型还是可能漏掉。
publicclassDocumentQAService{
publicStringanswerQuestion(String question,Document longDoc){
// 先对长文档做语义分块,按章节边界切分
List<Chunk> chunks =splitBySemanticBoundary(longDoc);
// 召回最相关的Top-3段落,用向量相似度排序
List<Chunk> relevantChunks =semanticSearch(question, chunks,3);
// 按相关性降序排列,最相关的放开头(利用模型对首部的高注意力)
relevantChunks.sort((a, b)->
Double.compare(b.getRelevanceScore(), a.getRelevanceScore())
);
// 拼接上下文,控制总长度在8K以内(模型稳定区间)
String context =buildContext(relevantChunks,8000);
// 构造prompt,明确告知信息来源
String prompt =String.format(
"根据以下产品说明书片段回答问题。\n\n上下文:\n%s\n\n问题:%s",
context, question
);
returncallLLM(prompt);
}
privateList<Chunk>splitBySemanticBoundary(Document doc){
List<Chunk> chunks =newArrayList<>();
// 按章节标题、段落结束等语义边界切分
for(Section section : doc.getSections()){
chunks.add(newChunk(section.getText(), section.getTitle()));
}
return chunks;
}
privateStringbuildContext(List<Chunk> chunks,int maxTokens){
StringBuilder context =newStringBuilder();
int tokenCount =0;
for(Chunk chunk : chunks){
int chunkTokens =estimateTokens(chunk.getText());
if(tokenCount + chunkTokens > maxTokens)break;
// 添加段落标识,帮助模型理解结构
context.append(String.format("[%s]\n%s\n\n",
chunk.getTitle(), chunk.getText()));
tokenCount += chunkTokens;
}
return context.toString();
}
}这段代码体现了几个关键思路:语义切分保证块内完整性,相关性排序利用模型对首部的高注意力,长度控制避开性能衰减区。实际项目中还会遇到跨段落的问题,比如用户问"这两个产品功能有什么区别",相关信息可能分别在两个章节。这时候单靠召回Top-K段落不够,需要在召回阶段做多跳检索,或者在prompt里显式告诉模型"以下是来自不同章节的信息,请综合分析"。
还有个容易被忽略的监控点。上线后要持续监控模型对不同位置信息的召回准确率,可以在测试集里埋一些"针",定期跑一遍类似大海捞针的测试,看看最近一周模型是不是在某个位置区间表现变差了。如果发现中部区域准确率下降,可能是最近上传的文档格式有变化,或者切分策略需要调整。这种主动监控比等用户投诉要靠谱得多。
最后说个成本维度的考量。这种方案的另一个好处是显著降低了推理成本,同样的任务直接用128K上下文可能需要几块钱,而检索后只用8K上下文可能只要几毛钱。对于需要规模化落地的业务场景,这个成本差异是不能忽视的。技术方案不只要能实现,还要算得过来账。
更深层的思考维度
这个问题背后其实隐藏着更深的技术哲学。完全解决长文本理解问题可能需要架构范式的突破,注意力机制本身就是在序列长度和计算效率之间做权衡。就像当年从RNN到Transformer的跨越,那次变革解决了长程依赖问题但引入了二次复杂度的计算负担。下一次范式转换可能会是什么?也许是记忆增强架构,也许是分层处理机制,但肯定不是简单地堆更大的上下文窗口。
这种现象其实在其他技术领域也有相似之处。推荐系统分析用户行为序列时会遇到类似困境,用户最近一周浏览了500个商品,如果直接用Transformer处理这个序列,模型对中间时段的行为关注度同样会下降。所以实际工程中会用滑动窗口或者分层注意力,和处理长文本的思路是相通的。技术本质上是在解决信息处理的效率和精度问题,不同领域的解决方案往往有异曲同工之妙。
还有个值得玩味的商业视角。既然模型处理长文本效果打折扣,为什么厂商还要拼命宣传支持128K、200K上下文?这其实是在用边界能力吸引眼球,虽然实际效果有衰减,但长上下文窗口在某些场景下确实有价值,比如代码补全需要看到整个文件上下文,或者法律文档分析需要完整合同。厂商的宣传策略是在展示技术上限,但工程落地还是要根据具体任务权衡。理解这种技术参数和实际效果之间的gap,是成熟工程师的必备素养。
Claude和GPT在大海捞针测试上的表现曲线不太一样,这背后反映了它们在位置编码和注意力窗口设计上的不同选择。Claude采用的是改进版的相对位置编码,对长距离依赖的处理更稳定;GPT-4则在训练目标中增加了长文本理解的监督信号。这些技术路线的差异导致了最终性能的分化,也说明这个问题还有很大的优化空间,业界仍在持续探索更好的解决方案。技术演进永远在路上,今天的局限可能就是明天的突破口。