精炼回答
实现文件处理AI Agent需要从多个维度进行技术架构设计。文件解析层面,你需要集成多格式解析器,包括PDF、Word、Excel、图片OCR等,确保能准确提取文本、表格、图像等结构化内容。智能理解模块要基于大语言模型构建,具备文档内容理解、意图识别和上下文推理能力,比如能理解"帮我整理这份财务报表中的异常数据"这类复杂指令。
任务执行引擎是核心组件,需要支持文件格式转换、内容摘要、数据提取、批量处理等操作,同时要有workflow编排能力处理复杂的多步骤任务。存储和检索系统要考虑向量数据库集成,支持语义搜索和文档索引,让Agent能快速定位相关文件内容。
安全机制不可忽视,包括文件访问权限控制、敏感信息脱敏、操作审计日志等。API接口设计要支持流式处理和进度反馈,特别是处理大文件时的用户体验。最后,错误处理和容错机制要完善,比如文件损坏时的降级处理策略,以及性能优化考虑,包括并发处理、缓存机制和资源管理,确保在高并发场景下稳定运行。整个系统还需要具备良好的扩展性,支持新文件格式和处理能力的动态接入。
扩展分析
详细解释
文件处理AI Agent本质上是一个多层协作的智能系统,从架构设计、核心模块到技术挑战,每个层面都需要深入思考。整个系统可以分为感知层、理解层、决策层和执行层四个核心层次。感知层负责文件格式识别和内容提取,理解层基于大模型进行语义理解,决策层制定处理策略,执行层完成具体的文件操作。每个模块都不是孤立的,而是通过统一的编排引擎协调工作,这样才能处理复杂的业务场景。
文件解析层的技术深度是整个系统的技术基石。文件解析层看似简单,实际上涉及多种复杂的技术挑战。PDF文档结构复杂,既有文本流又有图像对象,我们需要考虑文本提取的准确性和格式保持。对于扫描版PDF,还需要集成OCR引擎,这时候就涉及图像预处理、文字识别精度优化等问题。不同版本的Office文档、各种PDF生成工具产出的文件,在内部结构上有很大差异,我们需要建立格式适配层,针对每种格式的特点做专门优化。
publicclassFileParserFactory{
privateMap<String,FileParser> parsers =newHashMap<>();
publicFileParserFactory(){
parsers.put("pdf",newPDFParser());
parsers.put("docx",newWordParser());
parsers.put("xlsx",newExcelParser());
}
publicParseResultparseFile(String filePath){
String extension =getFileExtension(filePath);
FileParser parser = parsers.get(extension);
if(parser ==null){
thrownewUnsupportedFormatException("Unsupported file format: "+ extension);
}
return parser.parse(filePath);
}
}
publicclassCompatibilityHandler{
publicParseResulthandleUnsupportedFormat(String filePath){
try{
return primaryParser.parse(filePath);
}catch(UnsupportedFormatException e){
logger.warn("Primary parser failed, trying fallback");
return fallbackParser.parseAsText(filePath);
}
}
}
AI模型选型和多模态处理是系统智能化的关键。对于文档理解,我们需要考虑文本理解模型和视觉理解模型的协同。纯文本内容可以用专门的文档理解模型,比如LayoutLM系列,它能理解文档的布局结构。对于包含图表、表格的复杂文档,需要视觉-语言多模态模型来理解空间关系。拿电商场景举例,当用户上传一个包含商品图片和价格表格的PDF时,系统需要同时理解图片中的商品特征和表格中的价格结构,这就需要多模态融合技术。模型选型的关键不是选最先进的,而是选最适合业务场景的。
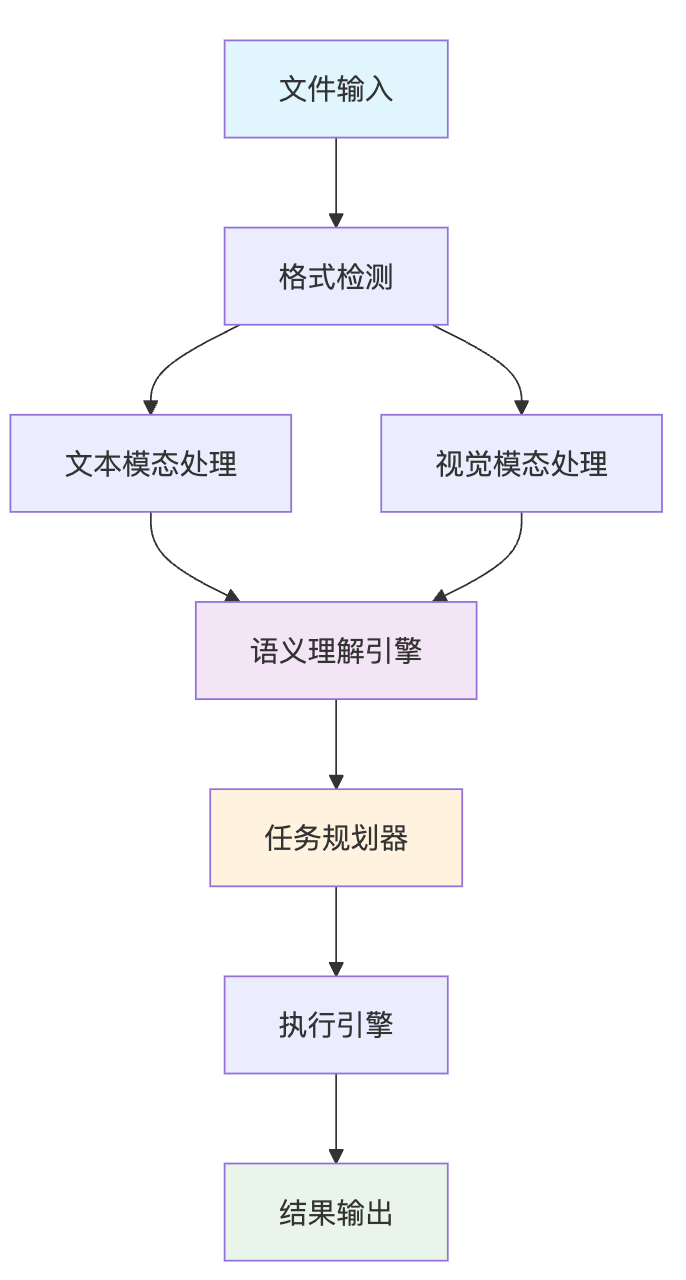
任务调度和流程编排体现了系统的工程复杂度。文件处理往往不是单一操作,而是一个包含多个步骤的工作流。比如用户要求"分析这份财务报表并生成总结报告",实际上包含了文件解析、数据提取、异常检测、报表生成等多个步骤。我们需要使用有向无环图(DAG)来管理步骤间的依赖关系,确保任务能够按正确的顺序执行。
publicclassWorkflowEngine{
publicvoidexecuteWorkflow(WorkflowDefinition workflow,FileContext context){
Queue<TaskNode> readyTasks =newLinkedList<>();
// 找到所有入度为0的任务
workflow.getTasks().stream()
.filter(task -> task.getDependencies().isEmpty())
.forEach(readyTasks::offer);
while(!readyTasks.isEmpty()){
TaskNode currentTask = readyTasks.poll();
TaskResult result =executeTask(currentTask, context);
// 更新依赖此任务的其他任务状态
updateDependentTasks(currentTask, result, readyTasks);
}
}
privatevoidupdateDependentTasks(TaskNode completedTask,TaskResult result,Queue<TaskNode> readyTasks){
completedTask.getDependentTasks().forEach(dependentTask ->{
dependentTask.markDependencyCompleted(completedTask.getId());
if(dependentTask.allDependenciesCompleted()){
readyTasks.offer(dependentTask);
}
});
}
}
数据存储和缓存策略需要体现分层存储的设计思路。原始文件存储在对象存储中,解析后的结构化数据存储在关系型数据库中,向量化后的语义信息存储在向量数据库中,热点数据通过多级缓存加速访问。文件内容变化频率低但访问频繁,适合缓存;而解析结果需要支持复杂查询,适合关系型存储。向量数据库的引入让系统具备了语义搜索能力,用户可以通过自然语言描述来查找相关文档。
实践应用
性能瓶颈和资源管理是系统上线后最常遇到的挑战。大文件处理的性能挑战主要体现在内存管理和并发控制上。处理几百MB的PDF文件时,不能直接全量加载到内存中,而要采用流式处理方式。更关键的是要有背压控制机制,当上游文件上传速度超过下游处理能力时,系统需要有限流机制防止雪崩。
publicclassStreamingFileProcessor{
privatefinalSemaphore processingSemaphore;
privatefinalint maxConcurrentTasks =10;
publicStreamingFileProcessor(){
this.processingSemaphore =newSemaphore(maxConcurrentTasks);
}
publicCompletableFuture<ProcessResult>processLargeFile(InputStream fileStream){
returnCompletableFuture.supplyAsync(()->{
try{
processingSemaphore.acquire();
returnprocessInChunks(fileStream);
}catch(InterruptedException e){
Thread.currentThread().interrupt();
thrownewProcessingException("Task interrupted", e);
}finally{
processingSemaphore.release();
}
});
}
privateProcessResultprocessInChunks(InputStream stream){
byte[] buffer =newbyte[8192];
ProcessResult result =newProcessResult();
try{
int bytesRead;
while((bytesRead = stream.read(buffer))!=-1){
processChunk(buffer, bytesRead, result);
}
}catch(IOException e){
thrownewProcessingException("Failed to process file stream", e);
}
return result;
}
}
我们要关注几个核心指标:单个文件的处理时延、系统并发处理能力、内存使用峰值等。拿电商场景举例,商家批量上传商品图片时,系统需要在30秒内完成100张图片的OCR识别和信息提取,这就要求我们做好任务调度和资源分配。
容错机制和降级策略是保证系统稳定性的关键。文件处理是一个多步骤的流程,任何一个环节出错都可能导致整个任务失败。当遇到加密的PDF或者损坏的文件时,我们需要建立多层降级机制,首先尝试标准解析,失败后启用备用解析器,最后还可以通过OCR方式处理,确保用户至少能得到基础的文本内容。
publicclassResilientProcessor{
privatefinalCheckpointManager checkpointManager;
privatefinalNotificationService notificationService;
@Retryable(value ={ProcessingException.class}, maxAttempts =3, backoff =@Backoff(delay =1000))
publicProcessResultprocessWithRetry(FileTask task){
checkpointManager.saveCheckpoint(task.getId(), task.getCurrentStage());
returndoProcess(task);
}
@Recover
publicProcessResultrecover(ProcessingException ex,FileTask task){
logger.error("Task {} failed after all retries", task.getId(), ex);
notificationService.alertOperators(task, ex);
returnProcessResult.failure(ex.getMessage());
}
publicProcessResultprocessWithFallback(FileTask task){
try{
return primaryProcessor.process(task);
}catch(ProcessingException e){
logger.warn("Primary processing failed, trying fallback for task {}", task.getId());
return fallbackProcessor.processAsPlainText(task);
}
}
}
安全性和隐私保护在企业级应用中至关重要。安全保护要从多个层面考虑,包括传输加密、存储加密、访问控制、操作审计等。系统要能自动识别身份证号、银行卡号等敏感信息,在处理过程中进行脱敏或加密处理。拿电商场景举例,用户上传的合同文件可能包含个人信息,系统需要在提取关键信息的同时保护隐私数据。每个关键节点都要有监控埋点,一旦发现异常要能快速定位问题根因。
AI模型的成本控制是系统商业化的重要考量。AI推理是系统最大的成本开销,我们需要在精度和成本之间找平衡。模型量化可以减少GPU内存使用,批处理可以提高吞吐量,智能缓存可以避免重复计算。对于简单的文档提取任务,可以用轻量级模型;只有复杂的理解任务才调用大模型。这种分层的处理策略可以显著降低整体成本。
扩展思考
架构演进和技术前瞻是系统长期发展的关键考虑。从单一功能向多模态协同发展是必然趋势,未来的文件处理Agent不再是孤立的工具,而是能够理解用户意图、自主规划任务、与其他Agent协作的智能体。系统架构会向更加模块化和可插拔的方向发展,支持能力的动态组合和升级。我们要设计出能够拥抱变化的系统结构,而不是预测所有可能的变化。
publicinterfaceAgentCapability{
StringgetCapabilityName();
ProcessResultexecute(TaskContext context);
booleancanHandle(TaskType taskType);
CapabilityMetadatagetMetadata();
}
publicclassCapabilityRegistry{
privateMap<String,AgentCapability> capabilities =newConcurrentHashMap<>();
privateLoadBalancer loadBalancer =newRoundRobinLoadBalancer();
publicvoidregisterCapability(AgentCapability capability){
capabilities.put(capability.getCapabilityName(), capability);
logger.info("Registered new capability: {}", capability.getCapabilityName());
}
publicAgentCapabilityfindBestCapability(TaskType taskType){
List<AgentCapability> candidateCapabilities = capabilities.values().stream()
.filter(cap -> cap.canHandle(taskType))
.collect(Collectors.toList());
if(candidateCapabilities.isEmpty()){
return defaultCapability;
}
return loadBalancer.select(candidateCapabilities);
}
publicvoidunregisterCapability(String capabilityName){
capabilities.remove(capabilityName);
logger.info("Unregistered capability: {}", capabilityName);
}
}
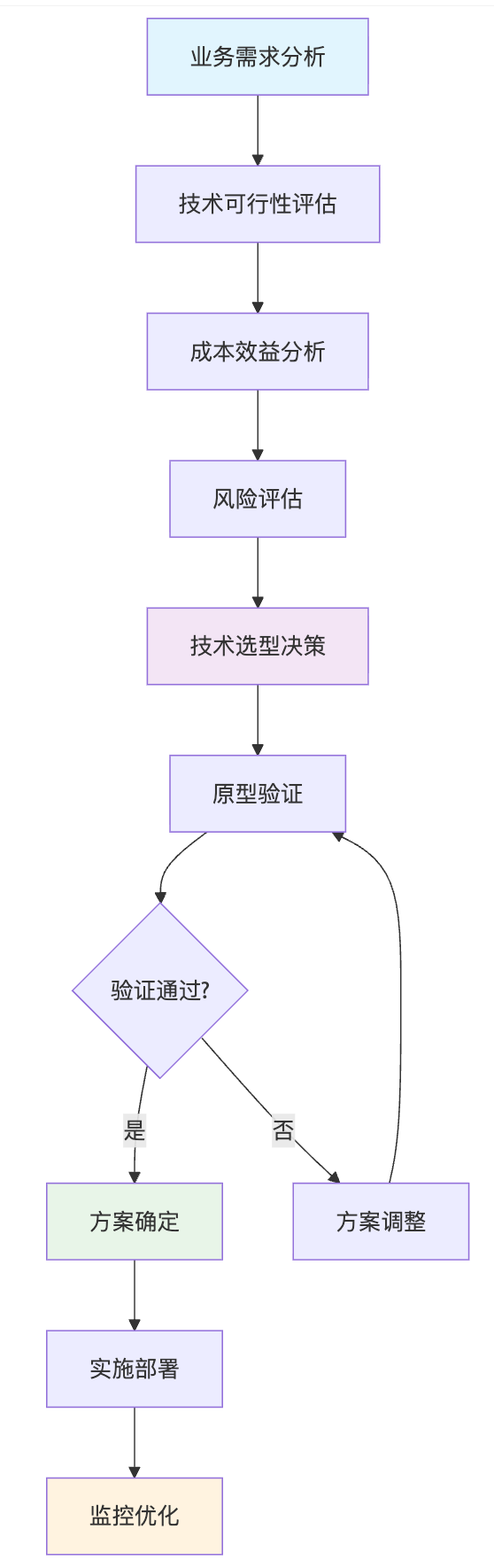
技术选型的战略思维需要平衡当前需求和未来发展。技术选型不是技术问题,而是商业问题。架构师的价值不在于知道所有技术,而在于能为具体问题选择最合适的技术组合。商品图片处理对实时性要求高,而财务报表分析对准确性要求更高,这就决定了不同场景下的技术选择策略。好的技术决策要基于数据和指标,比如性能基准测试、成本效益分析、团队学习成本评估等。每个技术选择都要考虑最坏情况下的应对策略,比如依赖的第三方服务不可用时的降级方案。
系统演进的长远规划要在当前可用性和未来扩展性之间找平衡,既不能过度设计增加当前复杂度,也不能短视导致后续重构成本过高。插件化架构支持新文件格式的快速接入,微服务架构支持独立的能力升级,事件驱动架构支持新业务流程的灵活组合。系统演进要基于实际业务需求,避免过度工程化。关键是要有数据架构的前瞻性设计、API的版本化管理、核心组件的抽象化等具体的演进策略。
最终,一个优秀的文件处理AI Agent不仅要解决当前的技术问题,更要为未来的业务发展奠定坚实的技术基础。这要求我们在系统设计时就要考虑扩展性、可维护性和演进能力,让技术真正成为业务发展的助推器。