精炼回答
AI Agent在执行过程中常遇到的错误主要包括网络连接异常、API调用失败、输入数据格式错误和推理逻辑偏差等情况。
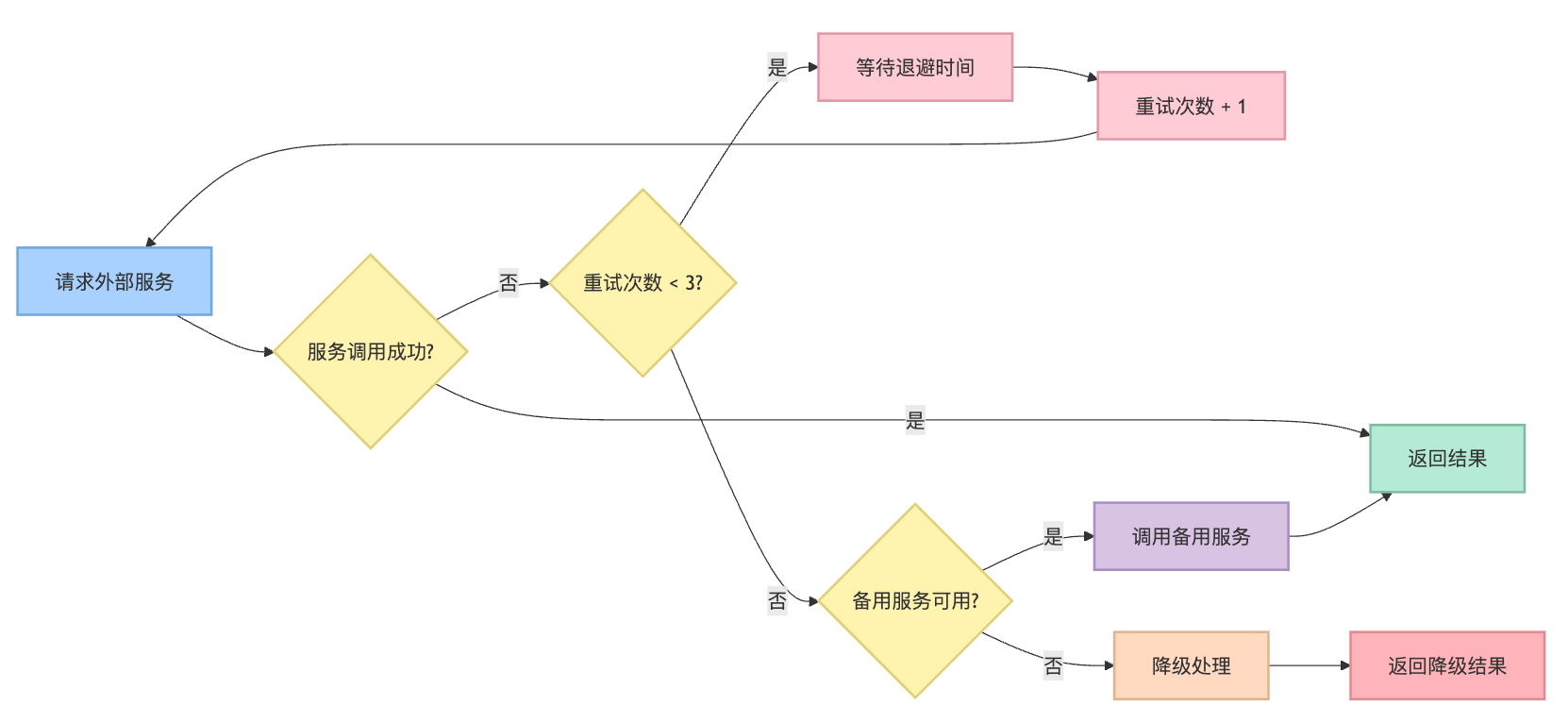
当网络连接中断或外部服务不可用时,Agent需要实现重试机制和降级策略,比如在调用第三方API失败时自动切换到备用服务或使用本地缓存数据。对于输入数据异常,应该在Agent接收输入时进行严格的数据验证和清洗,确保数据类型、格式和范围符合预期。
在推理过程中,Agent可能因为上下文理解偏差或知识库信息不准确导致错误决策。这需要通过多轮验证机制来处理,让Agent在执行关键操作前进行结果确认,并设置置信度阈值,当不确定性过高时主动寻求人工介入。
对于工具调用失败的情况,Agent应该具备异常捕获能力,记录错误详情并尝试替代方案。比如在文件操作失败时检查权限设置,在数据库查询异常时调整查询语句。
最重要的是建立完整的日志记录体系,记录Agent的每个决策节点和执行结果,便于问题追踪和模型优化。同时设计熔断机制,防止错误在多Agent系统中传播扩散。
扩展分析
详细解释
AI Agent的错误可以从三个维度来分析,分别是基础设施层、业务逻辑层和智能决策层的错误。基础设施层的错误主要是网络异常、服务调用失败这类传统分布式系统都会遇到的问题,对于这类错误,我们通常采用重试加降级的策略。业务逻辑层的错误包括数据格式异常、参数校验失败等,这需要在Agent的输入输出环节建立严格的校验机制。最有技术含量的是智能决策层的错误,也就是Agent理解偏差或推理错误,与传统系统不同,AI Agent的错误往往具有不确定性,需要通过置信度机制和人工介入来兜底。
当面试官问起输入数据异常的处理时,数据异常的识别需要在多个层次进行校验。最直观的是格式校验,比如用户输入的商品ID应该是数字,但收到的却是包含特殊字符的字符串。这种错误相对容易检测,但更复杂的是语义层面的异常。电商用户搜索"苹果",可能指水果也可能指手机,Agent需要通过上下文来判断意图。如果判断错误,需要有机制让用户进行澄清,而不是直接按照系统理解执行操作。
publicclassInputValidator{
publicValidationResultvalidateInput(String userInput,String context){
// 格式校验
if(!isValidFormat(userInput)){
returnValidationResult.formatError("输入格式不正确");
}
// 语义校验
double confidence = semanticAnalyzer.analyze(userInput, context);
if(confidence <0.7){
returnValidationResult.needClarification("需要进一步确认您的意图");
}
returnValidationResult.success();
}
}
模型推理错误的特殊性在于它往往不会直接抛出异常,而是产生看似合理但实际错误的结果。监测这类错误需要建立多重验证机制。比较有效的方法是设置检查点,在Agent做出关键决策时进行一致性检验。拿电商场景举例,当Agent推荐商品时,可以检查推荐结果是否与用户历史偏好矛盾,价格区间是否合理,库存状态是否正常。如果发现不一致,就需要降低置信度或触发人工审核。
publicclassAgentDecisionHandler{
privatestaticfinaldouble CONFIDENCE_THRESHOLD =0.8;
publicAgentResponseprocessDecision(AgentRequest request){
AgentResponse response = agent.process(request);
if(response.getConfidence()< CONFIDENCE_THRESHOLD){
// 置信度不足时的处理策略
returnescalateToHuman(request, response);
}
return response;
}
}
外部服务调用失败的处理策略需要重点强调渐进式降级的思路。我们不能简单地把外部服务失败当作系统错误,而是要设计优雅的降级方案。以支付服务为例,如果主要的支付渠道故障,Agent应该自动切换到备用支付方式,而不是直接向用户报错。更进一步,如果所有支付渠道都有问题,可以引导用户稍后重试,并提供其他购买方式的建议。
重试机制的设计也有讲究,指数退避这个概念在系统设计中非常重要。第一次重试间隔1秒,第二次2秒,第三次4秒,这样既避免了系统雪崩,又给外部服务恢复留出了时间。
资源不足和性能瓶颈的应对需要从预防和治理两个角度来考虑。预防方面,Agent需要具备自我感知能力,监控自身的CPU、内存使用情况。当发现资源紧张时,可以主动降低处理精度或延缓非关键任务的执行。治理方面,需要建立任务优先级队列,确保重要业务能够优先得到资源。电商场景中,支付相关的请求优先级应该高于商品浏览,这样即使系统压力大,也能保证核心业务的正常运行。
publicclassResourceMonitor{
privatestaticfinaldouble MEMORY_THRESHOLD =0.8;
publicProcessingModeadjustProcessingMode(){
double memoryUsage =getMemoryUsage();
if(memoryUsage > MEMORY_THRESHOLD){
returnProcessingMode.LIGHTWEIGHT;
}
returnProcessingMode.FULL_FEATURED;
}
}
实践应用
错误处理的代码实现最好体现分层设计的思想。我会把错误处理抽象成统一的异常处理器,这样既保证了处理逻辑的一致性,又便于后续的维护扩展。具体实现上,可以设计一个ErrorHandler接口,针对不同类型的错误实现不同的处理策略。
publicinterfaceErrorHandler{
booleancanHandle(Exception error);
AgentResponsehandle(Exception error,AgentContext context);
}
publicclassNetworkErrorHandlerimplementsErrorHandler{
@Override
publicbooleancanHandle(Exception error){
return error instanceofNetworkException;
}
@Override
publicAgentResponsehandle(Exception error,AgentContext context){
// 实现重试和降级逻辑
returnretryWithFallback(context);
}
}
监控指标的设计需要覆盖Agent运行的全生命周期,不能只盯着错误率这一个指标。重要的监控维度包括响应时间、置信度分布、重试次数、降级触发频率等。拿电商场景举例,如果Agent处理用户咨询的平均响应时间突然从2秒增加到10秒,即使没有直接报错,也说明系统可能出现了问题。
告警机制的设计要避免"狼来了"效应,告警的精准性比覆盖面更重要。可以设置多级告警阈值,比如错误率超过1%时发送警告邮件,超过5%时发送紧急短信,超过10%时自动触发熔断机制。这样既能及时发现问题,又不会让开发人员被无效告警淹没。
publicclassAgentMonitor{
privateMetricsCollector metricsCollector;
privateAlertManager alertManager;
publicvoidrecordError(String errorType,String agentId){
metricsCollector.increment("agent.error.count",
Tags.of("type", errorType,"agent", agentId));
double errorRate =calculateErrorRate(agentId);
if(errorRate >0.05){
alertManager.sendAlert(AlertLevel.CRITICAL,
"Agent "+ agentId +" error rate: "+ errorRate);
}
}
}
AI Agent的日志不能按照传统系统的思路来设计,需要记录Agent的思考过程,而不仅仅是执行结果。具体来说,需要记录Agent接收到的输入、中间的推理步骤、最终的决策依据、执行的操作序列等信息。这样当出现问题时,开发人员能够快速还原Agent的决策路径,定位问题根因。
日志的结构化设计也很关键,使用JSON格式记录结构化日志,便于后续的自动化分析。每条日志都应该包含请求ID、Agent实例ID、时间戳、操作类型、置信度等关键字段,这样可以通过日志聚合工具快速检索和分析。
AI Agent的测试不能只关注正常流程,异常场景的覆盖更加重要。可以设计专门的混沌测试,比如随机注入网络延迟、模拟外部服务间歇性故障、构造边界输入数据等。拿电商场景举例,可以测试在促销高峰期网络拥堵时Agent的表现,或者在商品库存数据不一致时Agent如何处理用户的购买请求。
@Test
publicvoidtestNetworkFailureRecovery(){
// 模拟网络故障
networkSimulator.injectLatency(5000);
AgentResponse response = agent.processRequest(testRequest);
// 验证Agent是否正确启用了降级策略
assertThat(response.getSource()).isEqualTo("FALLBACK_SERVICE");
assertThat(response.isPartialResult()).isTrue();
}
定期进行故障演练能够检验错误处理机制的有效性,也能提升团队的应急响应能力。可以模拟各种故障场景,比如数据库连接池耗尽、消息队列积压、AI模型服务不可用等,验证Agent是否能够按照预期进行降级和恢复。
扩展思考
容错架构的核心是隔离故障影响范围,确保局部错误不会导致全局崩溃。具体可以提到Agent服务的无状态设计、通过负载均衡实现故障转移、使用消息队列解耦Agent之间的依赖关系等。电商场景中,客服Agent的故障不应该影响推荐Agent的正常工作,这就需要在架构设计时充分考虑服务边界的划分。
publicclassAgentCircuitBreaker{
privatefinalAtomicInteger failureCount =newAtomicInteger(0);
privatevolatilelong lastFailureTime =0;
publicbooleanallowRequest(){
if(failureCount.get()< FAILURE_THRESHOLD){
returntrue;
}
returnSystem.currentTimeMillis()- lastFailureTime > RECOVERY_TIMEOUT;
}
}
不同AI应用场景的错误处理策略确实存在显著差异。对话型Agent更注重用户体验的连续性,即使出现理解错误也要保持对话流畅,通过澄清问题来修正错误。而决策型Agent在金融、医疗等关键领域需要更严格的验证机制,宁可拒绝处理也不能给出错误结果。
AI Agent的可靠性不仅要考虑系统层面的故障,还要关注模型本身的退化问题。随着时间推移和数据分布变化,AI模型的效果可能会逐渐下降,这需要建立持续的效果评估和模型更新机制。拿电商推荐场景举例,用户偏好的变化、商品类目的调整都可能影响推荐效果,需要通过在线学习或定期重训练来保持模型的准确性。

每次故障都是系统改进的机会,关键是要建立完善的事后分析机制。通过收集故障数据、分析根本原因、制定预防措施,逐步提升系统的整体可靠性。同时强调可观测性的重要性,我们不能等到用户投诉才发现问题,需要通过主动监测来预防故障。
需要根据业务增长预期和错误处理的资源消耗来设计系统容量。重试机制和降级策略虽然提高了系统的可靠性,但也会消耗额外的计算资源。在系统设计时需要预留足够的冗余,确保在异常情况下系统仍然有足够的资源来执行错误恢复流程。
AI Agent错误处理的核心是在保证系统稳定性的前提下,尽可能发挥AI的智能优势,关键是要设计好容错机制和人机协作的边界。