精炼回答
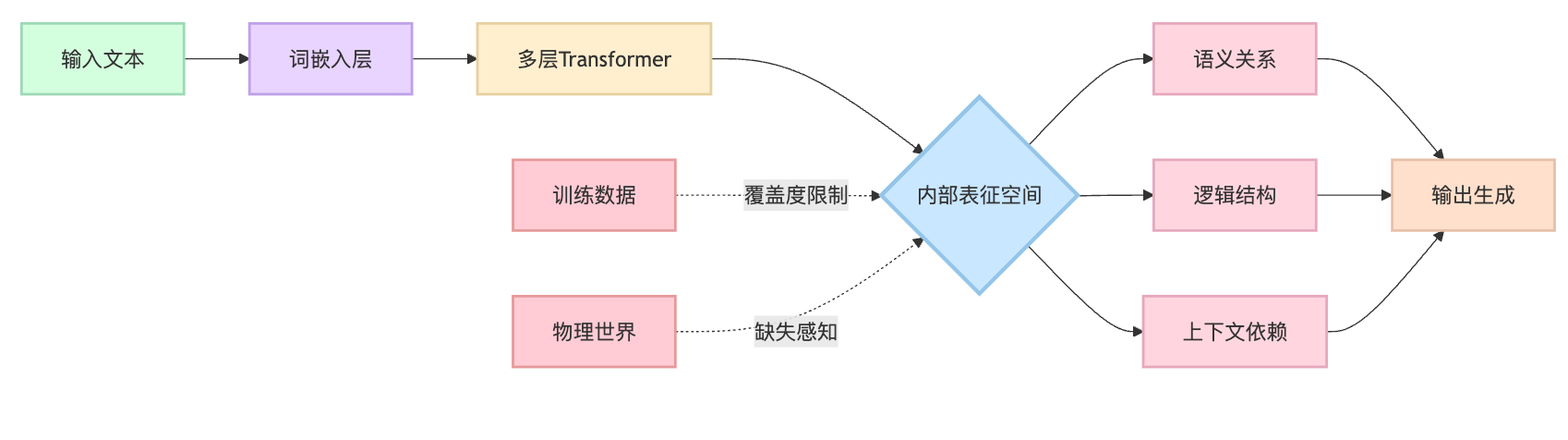
大模型的"理解"本质上是一种涌现的统计能力,介于简单模式匹配和人类理解之间。它通过数十亿参数在海量文本中学习到的不仅是表面的词汇共现模式,而是更深层的语义关系、逻辑结构和上下文依赖。
你可以这样观察它的能力边界:当我问"法国首都是哪里",回答"巴黎"可能只是模式匹配;但当我说"我在巴黎铁塔附近,需要找个地方吃法餐",模型能同时处理地理推理、文化常识和意图识别,这已经超越了简单的词语关联。它甚至能完成代码调试、多步推理这类需要维护中间状态的任务,这说明内部表征确实捕获了某种结构化的"知识"。
但说它完全"理解"又不准确。它没有真实世界的感知基础,碰到训练分布外的问题会出现一本正经的胡说。比如问"如果把埃菲尔铁塔倒过来插进地里会怎样",它可能给出看似合理但缺乏物理直觉的答案。更关键的是,它的"理解"是冻结在训练数据时刻的,缺少持续更新和自主验证机制。所以准确的说法是:大模型构建了功能性的语义表征,在特定任务上表现出类理解行为,但和人类基于体验的理解机制有本质差异。
扩展分析
面试时如何建立讨论框架
面试时听到这个问题先别急着下结论,因为面试官其实在考察你三个能力:能不能识别概念陷阱、思维是否足够辩证、以及能不能把复杂问题说清楚。开场30秒你要做的第一件事是重新定义战场。可以这样说:"这个问题的关键在于我们怎么定义'理解'。如果理解是指能根据上下文生成合理响应、完成复杂推理任务,那大模型确实展现出某种理解能力;但如果理解需要像人类那样有感知基础、能自主验证真伪,那它就还差得远。"这样一句话就把自己拉到了一个不偏不倚的专业位置,既没说它是智能黑盒,也没说它只是简单的字符串匹配。
接着给出你的分析框架:"我会从三个层面来看这个问题——首先是大模型内部到底学到了什么,它的表征能力在哪个层级;其次是它能做和不能做的事情边界在哪里,这能帮我们判断它的'理解'深度;最后是它和人类理解机制的本质差异,这决定了我们该怎么合理使用它。"这个框架传递出一个信号:你知道这不是非黑即白的问题,而且已经准备好用结构化的方式展开讨论了。面试官听到这里基本就放心了,知道你不会给出那种"大模型只是统计学parrot"或者"它已经有意识了"这种极端答案。
模式匹配的层次差异
面试中展开这个话题时,很多同学会犯一个错误:直接开始讲Transformer架构、注意力机制这些技术细节。但面试官真正想听的不是这些——他们想知道你有没有深度思考过这个本质问题。所以你的论述重点应该放在"理解"这个概念本身,而不是模型结构。
先从最容易被误解的地方说起。当我们说"模式匹配"的时候,很多人脑子里想的是简单的字符串查找,就像正则表达式那样。面试时你可以主动澄清这一点:"如果把模式匹配理解成简单的文本检索,那大模型显然做的远不止这些。但如果把模式匹配定义为从数据中提取统计规律并泛化应用,那它确实还是一种高级的模式匹配。"这种表述方式能让面试官感觉到你在认真思考概念边界,而不是急着站队。
接下来要解释清楚大模型到底在统计什么。这里有个很好用的类比:传统的N-gram模型预测下一个词只看前面几个词的共现频率,但Transformer通过自注意力机制能够"看到"整个上下文中任意两个词之间的关系强度。更关键的是,这种关系不是直接存储的,而是通过多层非线性变换编码在参数空间里的。面试时可以这样说:"你可以把它想象成一个压缩算法,但压缩的不是文件大小,而是把人类语言的使用规律压缩进千亿参数里。当它'解压'的时候,不是简单复现训练数据,而是根据学到的规律生成新的合理组合。"
人类理解与模型表征的本质差异
这时候面试官可能会追问:那这种统计能力和真正的理解有什么区别?这是个哲学味很重的问题,但你可以用认知科学的角度来回答。人类的理解建立在多模态感知基础上——我们说"杯子"这个词时,脑中会浮现视觉形象、触感、使用场景,甚至童年被烫到的记忆。这种具身认知让我们能判断"用纸杯装开水泡茶"这个场景的不合理性。但大模型只有文本,它见过无数次"杯子装水"的描述,却从未真正"见过"一个杯子。
这就引出一个关键观察点:大模型的"理解"严重依赖训练数据的覆盖度。面试时举个实际的例子效果会很好:"假设你问模型'如何快速给手机充电',它能给出各种合理建议,因为这是常见话题。但如果你问'用微波炉能给手机充电吗',虽然训练数据里肯定有人讨论过这个危险行为并明确说不行,模型也会给出正确答案。但问题在于,它不是基于对电磁感应原理和锂电池化学反应的理解得出的结论,而是因为这个否定答案在相关语料中反复出现。"这个例子能很好地说明模型依赖统计相关性而非因果理解。
但话说回来,你也要展现出对大模型能力的认可,否则会显得你的认知停留在几年前。现在有大量研究表明,大模型内部确实涌现出了一些结构化的表征。MIT的研究发现,GPT在处理地理问题时,中间层的激活模式能够映射出真实的地图坐标关系;Anthropic的机械可解释性研究也发现,模型内部有专门的神经元负责识别代码中的变量作用域。面试时可以说:"这些发现很有意思,说明模型不是简单地记忆表面模式,而是在隐层空间中构建了某种抽象的概念图谱。当它处理'巴黎到伦敦的距离比到东京近'这种陈述时,内部确实在操作一种类似空间推理的东西。"
涌现能力与失败案例
这时候自然过渡到涌现能力的话题。所谓涌现,就是当模型规模超过某个临界点后,突然获得了训练时没有明确优化的能力。比如few-shot学习——你给模型几个例子,它就能理解你想要什么样的输出格式,甚至能推广到没见过的情况。这很难用简单模式匹配解释,因为它需要模型"理解"示例背后的规则,而不是记住具体内容。面试时可以讲:"拿代码生成来说,如果只是模式匹配,模型应该只能生成训练集里见过的代码片段的变体。但实际上它能根据你的自然语言描述,组合多个从未一起出现过的API调用,还能保持变量命名的一致性和逻辑的连贯性。这说明它内部确实维护了某种动态的上下文状态。"
不过说到这里必须立刻补充模型的失败案例,否则会显得你只会唱赞歌。最经典的就是幻觉问题——模型会一本正经地编造根本不存在的论文引用、历史事件或者技术细节。面试官很可能在这里追问,你要准备好解释:"这恰恰暴露了它'理解'的局限性。人类如果不确定某个事实,会明确说'我不知道'或者去查证,因为我们有元认知能力,知道自己知识的边界。但大模型的生成过程本质上是个概率采样,它只能根据上下文预测最可能的下一个词,没有内在的真伪验证机制。当训练数据中某个虚假信息被多次重复,或者模型需要填补知识空白时,它就会生成流畅但错误的内容。"
另一个很说明问题的现象是提示词敏感性。同样的问题换个问法,模型的答案质量可能天差地别。你可以给面试官演示一个思想实验:"如果直接问模型'9.11和9.9哪个大',它可能答错,但如果加上'请仔细比较这两个小数的大小',准确率就会提高。这说明什么?说明它不是真正理解数字的大小关系,而是在匹配问题模式——后一种问法在训练数据中更常出现在需要精确比较的场景里,所以触发了更合适的推理路径。"这个例子特别能说明模型依赖表面线索而非深层理解。
学术争论与实践立场
谈到学术界的争论时,你要展现出对不同观点的了解。一派以Yann LeCun为代表,认为当前大模型根本谈不上理解,只是"高级自动补全",真正的智能需要像婴儿那样通过与世界交互来学习。另一派像Ilya Sutskever则认为,如果一个系统能够准确预测人类语言的下一个词,它必然已经内化了生成这些语言所需的世界模型。面试时可以说:"我倾向于中间立场。模型确实学到了远超表面统计的东西,但这种'理解'是功能性的、狭义的。它在特定任务上表现出智能行为,但缺少自主性、泛化性和可验证性这些人类理解的核心特征。"
最后落脚到实践意义上。面试官问这个问题不是让你做哲学辩论,而是想知道你能不能正确使用这项技术。你可以总结说:"理解这个问题对工程实践很重要。如果我们把大模型当成真正'理解'了领域知识的专家,就会过度信任它的输出,在医疗、金融这些场景里造成风险。但如果只把它当成简单的模式匹配工具,又会错失很多机会。正确的做法是:在它擅长的模式识别、文本生成、创意辅助领域大胆使用,但涉及事实性判断、因果推理、安全攸关的决策时,必须加上人工审核或外部知识库验证。"
实践应用
谈完理论分析,面试官基本会追一句:"那你在实际项目中会怎么用大模型?"这个问题特别关键,因为它考察的是你能不能把刚才那些思辨转化成实际的工程判断。很多同学会突然变得很虚,开始讲一些空泛的原则。但面试官想听的是具体策略,最好能展现出你真的思考过这些问题。
面试时可以先给出一个清晰的任务分类思路。你可以这样组织:"我会把大模型应用分成三类场景来看待,每类对'理解'的要求完全不同。"然后自然展开:第一类是内容生成类任务,比如写营销文案、生成商品描述、回复客户咨询这些,这种场景其实模式匹配就够用了。模型不需要真正理解产品的技术原理,只要能根据关键词、类似案例生成流畅自然的文本就行。面试时强调一点:"这类任务的特点是容错率高、人工审核成本低,哪怕偶尔生成的内容不够完美,改一改就能用。所以我会直接用,但会设计好输出格式约束,比如在提示词里明确说'只输出产品卖点,不要编造具体参数',这样能避免模型过度发挥。"
第二类是信息抽取和分类任务,这时候模式匹配的局限性就会显现。拿用户评论情感分析来说,如果评论是"这个手机拍照确实不错,就是续航有点拉胯",模型需要同时识别出正面和负面情感,还要对应到具体的产品属性。面试时可以讲:"这种任务我不会完全信任模型的输出,而是会做双重验证。一方面在提示词里要求模型输出结构化的JSON,包含情感标签和置信度;另一方面会准备一个测试集,覆盖各种边缘情况——比如反讽、双重否定、方言表达这些。如果模型在测试集上的表现不稳定,我会考虑加入规则兜底,比如用关键词词典辅助判断。"这个回答传递的信号是:你知道在哪些地方模型会翻车,而且有具体的应对方案。
publicclassSentimentAnalyzer{
privatefinalLLMClient llmClient;
privatefinalKeywordDictionary fallbackDict;
publicSentimentResultanalyze(String review){
// 先用大模型分析
String prompt =String.format(
"分析以下评论的情感倾向,输出JSON格式:{\"sentiment\": \"positive/negative/neutral\", \"confidence\": 0.0-1.0, \"aspects\": [{\"feature\": \"拍照\", \"sentiment\": \"positive\"}]}\n评论:%s",
review
);
SentimentResult llmResult = llmClient.analyze(prompt);
// 置信度低于阈值时启用规则兜底
if(llmResult.getConfidence()<0.7){
SentimentResult ruleResult = fallbackDict.analyze(review);
// 综合两种结果
returnmergeResults(llmResult, ruleResult);
}
return llmResult;
}
}第三类是高风险决策类任务,这时候必须假设模型是不理解的。面试时举个医疗或者金融的例子效果最好:"假设要做一个智能客服,用户问'我高血压能不能吃这个药',这种问题绝对不能让模型直接回答。因为模型可能见过类似的医学咨询对话,生成的答案看起来很专业,但它没有真正理解药物相互作用的机制。正确做法是设计一个意图识别层,把这类健康咨询识别出来,然后转接人工或者返回固定的免责声明。模型只负责理解用户在问什么,而不负责给出答案。"这个例子能很好地说明你知道技术边界在哪里,不会滥用大模型。
说到测试模型的理解能力,面试时可以分享一个实用技巧。很多人只用正常用例测试,但真正暴露问题的往往是对抗样本。你可以这样说:"我会专门设计一些'诱导性'测试用例。比如测试商品推荐功能时,故意在用户query里加入矛盾信息——'我想买一台轻薄的游戏本,预算2000块'。如果模型真的理解了这些约束条件,应该能识别出需求不合理;但如果只是做模式匹配,可能会机械地推荐一些不存在的产品。"然后补充:"这种测试不是为了证明模型有多蠢,而是帮我明确在哪些情况下需要加强约束。比如发现模型对价格不敏感,就在提示词里加上'严格按照预算范围筛选'这样的强调。"
提示词工程其实就是在利用模型的模式匹配特性。面试时可以分享一个渐进式设计策略:"我一般不会一开始就写很长的提示词,而是先用最简单的指令测试,看模型的基线能力在哪里。然后针对失败的case,逐步添加约束条件。"举个具体例子:"让模型生成代码注释时,一开始只说'给这段代码加注释',发现它经常写一些废话注释。于是改成'解释这段代码的业务逻辑,不要重复代码本身的语义',质量明显提升。最后再加上few-shot示例,给两三个好的注释样本,这时模型就能稳定输出符合预期的结果了。"这种循序渐进的方法论能体现你的工程经验。
关于风险控制,面试官可能会问得比较细。你要准备好几个具体的兜底机制。最基础的是输出格式校验:"如果要求模型返回JSON,我会在代码里先用schema验证,解析失败就重试或者降级到默认逻辑。"进阶一点的是语义一致性检查:"对于客服场景,我会让模型生成答案后,再用一次调用检查答案是否和问题相关,这样能过滤掉一部分幻觉内容。"最严格的是人工审核流程:"对于会发布到外部的内容,比如自动生成的新闻摘要,我会要求人工spot check,每天抽查10%的输出。如果发现错误率超过阈值,立刻切换到人工模式。"这些细节能让面试官看到你不是纸上谈兵,而是真的思考过生产环境的可靠性问题。
最后收尾时要点题。面试时可以总结说:"所以对于'大模型理解了吗'这个问题,我的工程答案是——不要纠结它到底理解没理解,而是根据任务风险等级和模型表现,动态调整信任度和验证强度。在低风险的创意任务上充分利用它的生成能力,在高风险的决策任务上只用它做辅助,关键判断还是要靠确定性的逻辑或者人工。这种务实的态度,比争论哲学问题更有意义。"这样回答既呼应了前面的理论分析,又展现出你作为工程师的成熟思维,面试官会觉得你是个靠谱的技术人选。
扩展思考
当面试官抛出这个问题时,其实他已经在心里画好了一张能力雷达图,等着看你能点亮哪几个维度。表面上是在讨论大模型是否理解,实际上在考察你的思维层次——能不能跳出纯技术视角看问题、有没有独立的判断力、以及思考问题时是否既有深度又能落地。很多同学以为这是道开放题没有标准答案,就放飞自我天马行空,结果要么掉进纯哲学讨论的陷阱,要么堆砌论文术语显得很虚。真正高明的回答应该是让面试官感觉到:这个人既想过深层问题,又没丢掉工程师的务实本色。
说完你的主要观点后,要做好被追问的准备。面试官很可能会抛出中文屋论证这个经典思想实验——一个完全不懂中文的人在房间里按照规则手册操作,接收中文问题并返回中文答案,从外部看起来他懂中文,但实际上他完全不理解。这时候千万别慌,这不是来砸场子的,而是给你机会展现思辨能力。面试时可以这样接:"我觉得中文屋论证特别有启发性,它揭示了形式操作和真正理解之间的鸿沟。但我也会反问——如果我们把那个房间换成人脑,把规则手册换成神经突触连接,似乎人类的理解过程也可以被描述成某种复杂的符号操作。关键可能不在于是否有个明确的规则手册,而在于这套系统能否自主演化、能否把符号接地到真实世界的感知经验上。"这样的回答既尊重了经典理论,又提出了自己的思考,不会显得只是背书。
如果面试官继续深挖,可能会问到AGI实现路径的问题。这时候要特别注意,别一股脑倒向某个技术阵营。可以坦诚地说:"当前大模型的进化路线让我看到了scaling law的惊人效果,但我也认同它可能只是通向AGI的一条路径而不是全部。像Yann LeCun提出的自监督学习、世界模型这些方向也很有道理。"面试时展现这种开放态度很重要,因为没人知道AGI的正确答案,面试官想看的是你有没有持续关注不同观点、能不能理性评估各种技术方案。顺便可以提一句你最近关注的研究进展,比如Chain of Thought怎么提升推理能力、Constitutional AI如何让模型更可控,这能证明你不是临时抱佛脚,而是真的在跟进这个领域。
把这个话题跟自己的项目经历结合时,别生硬地往上贴。如果你确实做过大模型相关的实践,可以自然地说:"我之前在项目里用大模型做过内容审核,刚开始觉得它挺智能的,能识别各种隐晦的违规表达。但后来发现只要换个说法它就不认识了,这让我意识到它学到的更多是训练数据里的模式,而不是真正理解了什么叫违规。这个经历让我在今天讨论这个问题时,会更偏向功能性理解而非意识层面的理解。"这样的表述既结合了实践,又回扣主题,不会让人觉得是在硬凑项目经验。如果你还没做过相关项目也没关系,就老实讲理论思考,别编故事,面试官看重的是思考质量而不是经历数量。
最后收尾时要展现出持续学习的态度,但别喊口号。可以说:"这个问题我最近一直在关注学术界的新进展,比如Anthropic发布的可解释性研究让我很兴奋,它们在尝试打开黑盒看看模型内部到底形成了什么样的表征结构。我觉得随着这类研究的深入,我们对'理解'这个概念本身也会有新的认识。"这种表述传递的信号是:你不是个观点固化的人,而是愿意随着技术发展更新自己的认知。这种成长型思维恰恰是面试官最看重的素质,因为AI领域变化太快,死守一套说辞的人很快就会被淘汰。