精炼回答
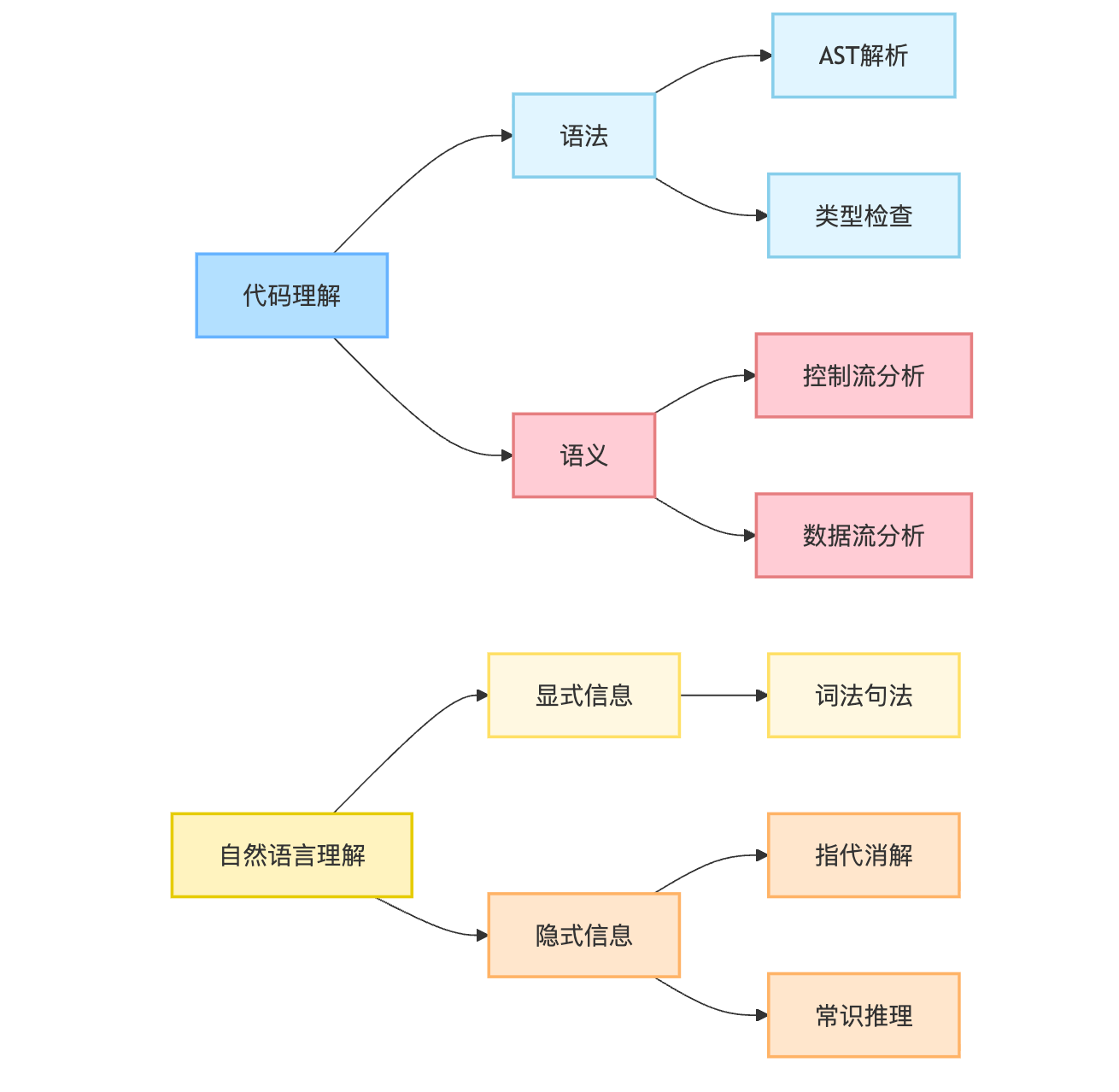
代码理解和自然语言理解的本质区别在于语义的确定性。代码具有严格的语法约束和执行语义,每个token的含义由语言规范明确定义,不存在歧义。当你写下int total = price * quantity这行代码时,编译器明确知道这是一个变量声明加赋值操作,*就是乘法运算符,不可能理解成其他意思。而自然语言充满模糊性、隐喻和上下文依赖,"我没说她偷了我的钱包"这句话,重音放在不同位置就能产生七八种不同的理解。
代码的结构化特性可以被充分利用。通过AST(抽象语法树)可以精确解析代码的语法结构,这比纯文本分析准确得多。在做代码补全时,模型能根据AST判断当前位置应该填函数名、变量名还是关键字。数据流和控制流分析能揭示代码的执行逻辑,比如在bug定位场景中,模型可以追踪变量的赋值和使用路径,而不是简单地看文本相似度。类型系统提供了强约束信息,在静态类型语言中,模型可以利用类型推导来理解代码意图,比如看到list.map()就知道返回的是新数组。像GitHub Copilot这样的工具会同时利用代码的语法树结构和周围代码的类型信息来生成补全建议,代码搜索引擎也会建立符号索引,通过函数调用图和继承关系图来理解代码间的依赖,这些都是利用结构化特性的典型场景。
扩展分析
语义确定性与结构化程度的本质差异
面试时回答这类对比问题,最忌讳的就是像背书一样罗列特点。这两种理解任务在本质上的不同,核心在于形式化程度的天壤之别。代码天生具有形式化的特征,每一行代码最终都要编译或解释成机器指令去执行,这意味着它不能有歧义——同一段代码在同样的输入下必须产生确定的输出。这种无歧义性是代码区别于自然语言的最根本特征。与之相对,自然语言里"这个方案还行"在不同语气下可能是认可也可能是讽刺,这种模糊性是人类语言灵活性的来源,但也是AI理解的最大障碍。
代码的结构不是隐藏的,而是显式存在的。当你用IDE打开一个Java文件,解析器立刻就能生成完整的语法树,告诉你哪些是类声明、哪些是方法体、哪些是循环结构。这种结构不是靠猜的,是严格按照BNF范式定义的语法规则解析出来的。更关键的是,代码还有执行语义层面的结构——控制流图告诉你程序执行的可能路径,数据流分析揭示变量在不同位置的状态变化。
// 这段代码的控制流是完全确定的
if(user.isVip()){
discount =0.8;
}else{
discount =1.0;
}
finalPrice = originalPrice * discount;
在代码补全场景中,模型解析到当前光标在if语句的条件表达式位置,就知道这里需要的是一个返回布尔值的表达式,而不是随便什么代码片段。通过数据流分析,模型还能知道discount这个变量在这两个分支里被赋予了不同的值,这对后续的代码生成有直接指导作用。反观自然语言,它的结构是隐式且柔性的。"他告诉李明说张伟明天不来了"这句话里,"他"指代谁需要依赖更大的上下文,"明天"是相对时间需要结合对话发生的时刻来确定,"不来了"的原因和后续影响完全没有明说。自然语言理解需要大量的指代消解、省略还原、常识推理,这些都没有形式化规则可循。
谈到AI建模的技术路径,这里面的差异就更明显了。代码理解模型往往会采用混合架构——既用Transformer处理代码的序列特征,又通过Graph Neural Network来编码AST或调用图这种显式的结构信息。像CodeBERT、GraphCodeBERT这类模型,就是在预训练时同时让模型学习代码的序列表示和结构表示。如果只把代码当成普通文本用纯Transformer处理,会丢失很多关键的结构信息——比如变量的作用域、函数的调用关系这些,而这些恰恰是理解代码逻辑的核心。
自然语言模型的演进路径则主要是在扩大规模和增强上下文理解能力上做文章。从BERT的双向编码到GPT的自回归生成,再到2025年像Claude这样的长上下文模型能处理百万token级别的输入,核心都是为了更好地捕捉隐式的语义依赖。为什么代码模型不能直接套用自然语言模型?因为代码有太多可以利用的先验知识——语法规则、类型系统、程序分析技术,如果不利用这些就去硬学,相当于放弃了最有价值的信号源。
这里要澄清一个常见误区:不要觉得代码容易理解、自然语言难理解。代码的复杂性来源不同——它的语法是确定的,但执行语义可能极其复杂。看一段涉及多线程、异步回调、复杂状态机的代码,哪怕每一行的语法都能解析,但要理解整体的执行逻辑和可能的bug,难度一点不比理解自然语言低。代码理解的挑战在于需要同时处理语法正确性和执行正确性两个层面——前者可以靠编译器保证,但后者需要深入理解业务逻辑、并发控制、边界条件处理这些复杂问题。
结构化信息的工程化利用
谈到代码结构化的利用,最怕的就是只停留在"AST很重要"这种空洞表述上。真正想听的是这些结构怎么变成模型能处理的输入,遇到具体问题时选择什么技术路径。最直接的思路是序列化成特殊token序列。就像把if (x > 0) { return x; }这段代码,不仅保留表面的代码文本,还会插入语法节点的标记,变成类似[IF_STMT] [CONDITION] x > 0 [THEN] [RETURN] x这样的序列。CodeBERT采用的就是这种方式,它在预训练时会同时学习代码序列和注释的对应关系,但结构信息是通过序列化嵌入到输入里的。这种方法的好处是实现简单,能直接复用现有的Transformer架构,但缺点是结构信息被压平了,模型需要自己去学习哪些token之间有语法依赖关系。
更进一步的做法是用图神经网络直接编码结构。这时候AST不再被打平成序列,而是保持树形或图形结构,每个节点对应一个向量表示,通过GNN的消息传递机制让父节点和子节点之间交换信息。GraphCodeBERT就是这个思路,它不仅有Transformer编码器处理代码序列,还有专门的图注意力层处理数据流图。比如在分析一个变量被赋值后如何流动到不同的使用位置时,图结构能让模型直接沿着数据流边传播信息,而不是让Transformer在整个序列上去猜测。
// 对于这段代码,数据流图会建立从赋值到使用的边
int discount =calculateDiscount(user);// 定义点
double finalPrice = price * discount;// 使用点1
logTransaction(finalPrice);// 使用点2控制流图的构建相对直接,每个基本块是一个节点,分支、循环、跳转语句形成有向边。数据流图更复杂一些,需要做到达定义分析——对每个变量的使用点,找到所有可能给它赋值的定义点,然后在定义点和使用点之间建边。这个过程可以用编译原理的经典算法,比如reaching definition analysis或者SSA(静态单赋值)形式来实现。提到SSA会让人觉得你对程序分析技术有实际了解,而不是只知道深度学习。
把结构信息和Transformer结合时,位置编码的设计也有讲究。标准的Transformer用的是绝对位置编码或者相对位置编码,但代码里token之间的关系不只是序列距离,还有语法树上的距离。有些工作会设计双重位置编码,一个编码token在代码序列中的位置,另一个编码它在AST中的深度或者到根节点的路径。这样模型既能捕捉代码的书写顺序,又能感知到语法层级关系。
注意力机制的mask设计也是个关键点。在代码补全场景中,模型不应该看到光标后面的代码,这需要causal mask。但如果做代码理解任务比如漏洞检测,双向注意力会更合适。实际应用中要根据任务特点灵活调整,比如做代码搜索时用双向编码器把代码和查询都编码成向量再算相似度,但做代码生成时必须用单向解码器保证自回归生成。
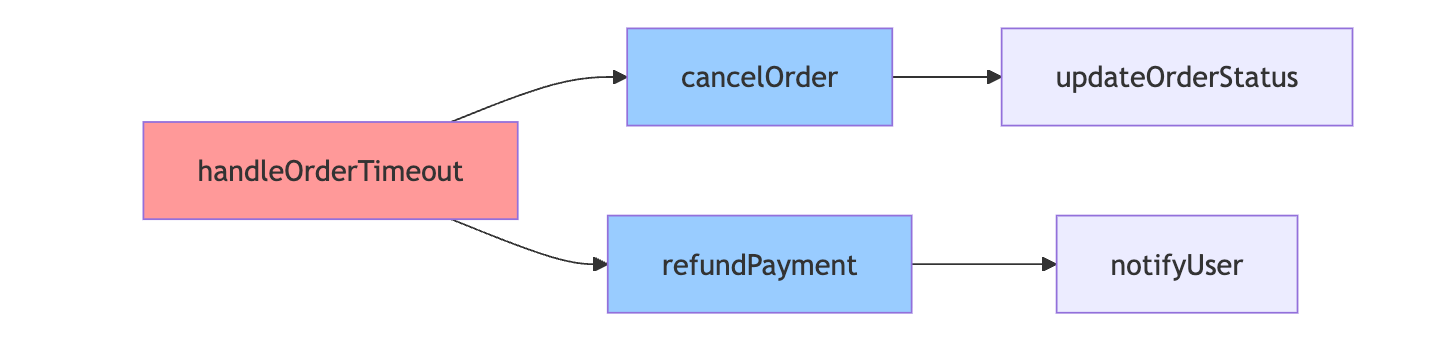
代码搜索是个特别能体现结构价值的例子。纯文本的代码搜索会遇到词汇鸿沟问题——开发者搜"计算折扣"但代码里写的是calculateDiscount。利用结构化信息后,模型可以建立函数调用图,知道哪些函数在业务逻辑上相关,即使名字不匹配也能通过调用关系推断相关性。假设搜索"处理订单超时",传统文本匹配可能找不到一个叫handleOrderTimeout的函数,但如果这个函数调用了cancelOrder和refundPayment,通过调用图分析就能推断出它确实在处理超时逻辑。
代码补全场景更直观一些。当开发者输入user.然后按下代码补全快捷键时,模型需要知道user对象的类型才能给出准确的方法建议。这就需要类型推导——往回追溯user是在哪里定义的,它的类型声明是什么,有哪些可访问的成员。这种分析需要结合AST和符号表,纯序列模型很难做到。实际工程中很多代码补全工具都依赖LSP(Language Server Protocol)提供的语义信息,AI模型在此基础上再做智能排序和生成。
漏洞检测是个更能体现技术深度的场景。检测SQL注入漏洞时,模型需要追踪用户输入从HTTP请求参数流动到SQL查询语句的完整路径,判断中间有没有经过转义或参数化处理。这种分析叫污点分析,需要在数据流图上做路径搜索——把用户输入标记为source,把SQL执行标记为sink,然后看有没有一条不经过sanitizer的路径连接它们。
// 污点分析需要追踪userId从请求到查询的流动路径
String userId = request.getParameter("id");// source标记
String sql ="SELECT * FROM users WHERE id="+ userId;// 未经过转义
statement.execute(sql);// sink标记,检测到风险路径
代码克隆检测是另一个典型应用。判断两段代码是否实现了相同逻辑,不能只看文本相似度——变量名改了、代码顺序调整了,但核心逻辑没变,这种克隆关系纯文本匹配会漏掉。利用AST可以做结构相似度计算,把两棵语法树对齐比较,甚至可以泛化到更高层次的程序依赖图比较。在代码审查时识别重复逻辑、在开源许可证检查时发现未声明的代码复用,都需要这种技术。
工程实践中还有些关键的细节值得注意。解析AST和构建数据流图是有性能开销的,实际部署时需要做缓存——把常用的库函数、框架代码的结构信息预先解析好存起来,避免每次都重新分析。代码补全场景对延迟要求很高,用户不可能等几秒钟才看到建议,这时候会采用两阶段策略——先用轻量级的基于规则的方法快速给出候选,再用深度模型做reranking。tree-sitter是个很流行的增量解析器,支持几十种编程语言,很多编辑器的语法高亮和代码折叠都用它。如果要做数据流分析,可以用Soot这个Java字节码分析框架,或者对Python代码用ast模块加上自己实现的数据流算法。
跨语言理解与技术演进方向
跨语言代码理解的难点不在于语法差异,而在于不同语言的生态差异——Java的Spring框架、Python的装饰器、Rust的所有权系统,这些特性背后都隐含着不同的编程范式和最佳实践。纯粹靠多语言联合训练能学到表层的语法映射,但很难理解这些深层的语义约定。实际开发中,代码永远不是孤立存在的,它和文档、issue讨论、commit message形成了完整的知识图谱。像GPT-4的Code Interpreter能理解用户用自然语言描述的数据分析需求,然后生成Python代码执行,这种跨模态能力才是真正提升开发效率的关键。
代码生成质量评估是另一个容易被追问的点。生成的代码可能语法正确、测试通过,但存在性能问题或安全隐患。比如生成的SQL拼接逻辑没有防注入,或者排序算法在边界情况下复杂度退化。真正的评估需要结合静态分析工具做代码质量检查,甚至引入人类专家做分层采样评估——常见场景可以自动化测试,复杂场景必须人工介入。这种回答方式展现的是对工程质量的严谨态度。
结构化先验知识和端到端学习之间的权衡,是个特别能体现架构思维的话题。早期的代码理解工具严重依赖手工设计的规则和程序分析,准确但脆弱,换个场景就不适用。纯端到端的深度学习模型泛化性好,但需要海量数据,而且很难解释为什么给出某个建议。实际系统设计中应该采用混合架构——用结构化分析保证底线的准确性,比如类型检查、作用域分析这些不能出错;用深度模型提升用户体验,比如根据上下文推荐更符合编码习惯的变量名。这样既有可控性又有灵活性。
从早期的CodeX到现在Claude这样的长上下文模型,代码生成能力在快速进步,但关键瓶颈不在模型本身,而在两个方向。第一个是如何把企业内部的代码库、架构文档、历史bug记录这些私有知识有效地注入到模型中,这涉及到知识库构建和检索增强。第二个是怎么让AI真正理解业务意图而不只是模仿代码模式,这可能需要结合需求文档、用户反馈这些更上层的信息。代码智能的效果演示很炫,但真正部署到生产环境会遇到很多现实问题——推理延迟能不能控制在百毫秒级别让开发者不打断思路、生成的代码怎么和现有的CI/CD流程集成做质量把关、多租户环境下如何保证代码隐私不泄露。这些工程问题往往决定了技术能不能真正产生价值,而不是停留在demo阶段。