精炼回答
幻觉是指大语言模型生成的内容看起来流畅自信,但实际上包含错误事实或完全虚构的信息。这个定义抓住了"形式正确、内容错误"的核心矛盾——模型本质上是基于概率的文本生成器,它通过预训练学习了海量文本中词语之间的统计关联,但并不真正"理解"事实。
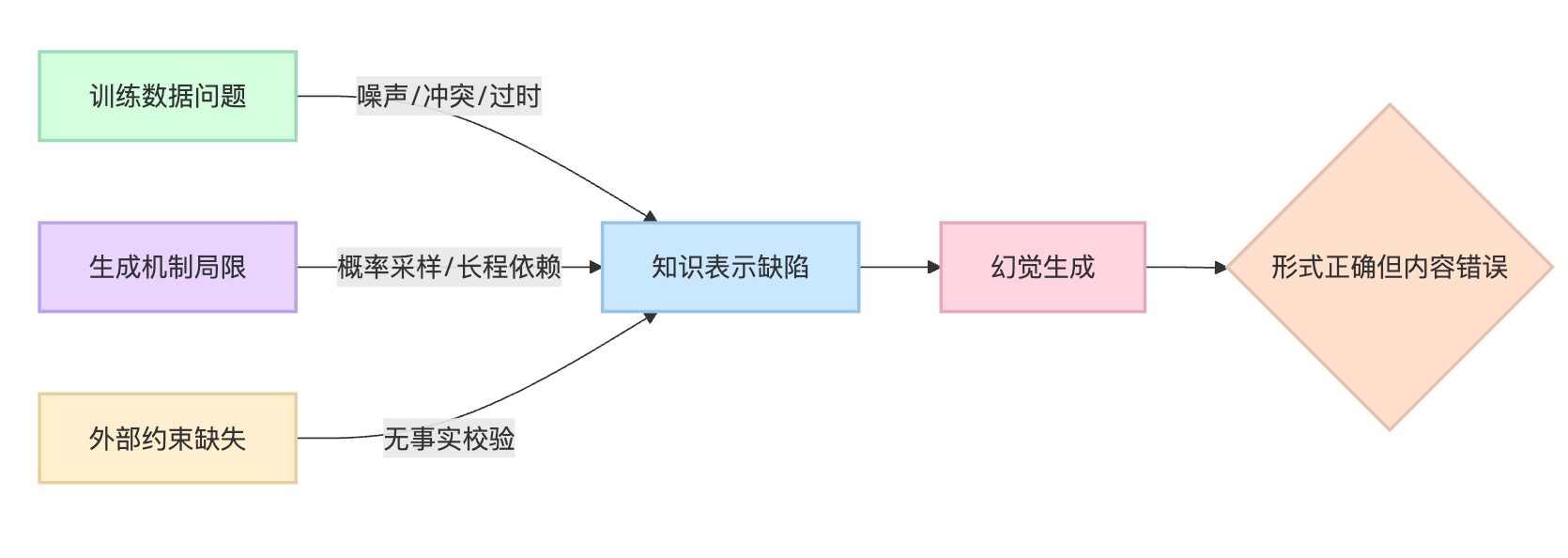
模型会"一本正经地胡说八道"主要有几个技术原因。首先,训练数据中存在错误信息或相互矛盾的内容,模型会学习到这些噪声。其次,模型的生成机制是基于概率采样,它只是在预测下一个最可能的token,而不是在检索真实知识。再者,模型会过度泛化训练模式,当遇到训练数据覆盖不足的问题时,会用学到的语言模式去"编造"一个听起来流畅的答案。
比如你问ChatGPT某个不存在的论文作者和出处,它可能会给你编造出完整的作者名、期刊名、发表年份,格式严谨得像真的一样。或者在电商场景中,你问模型某个冷门API的具体参数,它可能会按照常见API文档的写作风格,生成一套完整的参数说明,包括参数名、类型、描述,格式完美但内容全错。这是因为它学会了"API文档应该长什么样",却没有这个具体API的准确知识。
模型的目标函数是最小化预测误差而非保证事实准确性,加上Transformer架构的注意力机制在长文本中可能产生的上下文混淆,都会加剧幻觉现象。这也是目前AI落地的核心挑战之一,尤其在医疗、金融这类对准确性要求极高的领域,幻觉问题直接关系到AI能否被信任。
扩展分析
要真正理解幻觉问题,需要从现象本质、技术机制到实践应对做系统性的剖析。幻觉大概可以分为几种类型,最常见的是事实性幻觉,比如编造不存在的历史事件或技术参数;还有指令幻觉,模型没有按照你的要求做,反而自己发挥了;另外在多轮对话中还可能出现上下文冲突幻觉,前后说法矛盾。
举个电商场景的例子会让这个分类更具体:当你让模型生成商品描述时,它可能会编造这个商品获得了某个不存在的质量认证(事实性幻觉),或者你明确要求只输出标题但它还是加了一堆营销文案(指令幻觉),又或者在上一轮说这商品防水,下一轮又说需要避免潮湿环境(上下文冲突)。
大语言模型本质上是在做next token prediction,也就是根据前面的文本预测下一个词。它学到的是词与词之间的统计规律,而不是真实世界的知识。就像你让一个从来没去过北京的人,凭着看过的游记来描述北京某个小胡同,他可能说得头头是道,但细节全是编的。模型也一样,它见过无数描述商品的文本,所以知道商品描述应该"长什么样",但遇到没见过的具体商品时,就会按照学到的模式去拼凑一个听起来合理的答案。
训练数据本身就是幻觉的一个重要来源。互联网上的文本质量参差不齐,有错误信息、有过时内容、有相互矛盾的说法,模型在训练时会把这些都学进去。比如某个技术框架在2020年的用法和2023年完全不同,但模型的训练数据可能两种用法都见过,结果生成时就可能把旧版本的API和新版本的概念混在一起。还有就是知识截止日期的问题,模型对训练数据截止日期之后的事情一无所知,但它不会老实说"我不知道",而是会基于已有知识去推测,这种推测往往就成了幻觉。
从架构层面来看,Transformer的注意力机制虽然强大,但在处理长文本时会有记忆衰减的问题。当上下文很长时,模型可能逐渐"忘记"前面提到的关键信息,导致生成的内容与前文矛盾。打个比方,在一个长篇的商品咨询对话里,用户一开始说想要红色的,聊了很多轮之后,模型可能因为注意力权重的衰减,推荐了一个蓝色款,这就是架构局限性带来的幻觉。而且模型的自回归生成方式,每一步都依赖前一步的输出,一旦某一步出现偏差,后面很可能像滚雪球一样越偏越远。
解码策略会直接影响幻觉的发生概率。温度参数设得高,模型会更"大胆"地选择概率较低的词,这增加了创造性但也容易编造;温度设得低,输出更保守但也更容易重复训练数据中的模式。你会发现当温度调到0.8或1.0的时候,模型生成的营销文案很有创意,但也更容易出现夸张甚至虚假的宣传;而温度降到0.2时,文案虽然平淡但事实错误会少一些。这背后的权衡其实反映了创造性和准确性之间的矛盾。
归根结底,模型缺乏人类的真实世界理解和事实验证能力。人类在说一个陈述句之前,大脑里有个"这是真的吗"的验证机制,我们知道什么是亲身经历、什么是听说的、什么是推测的。但模型没有这个区分,它眼里所有训练数据都是平等的文本模式,不知道什么是ground truth。模型就像一个只会背诵答案的学生,它能把见过的知识点复述得很漂亮,但遇到需要真正理解才能回答的问题时,就只能凭着"感觉"去猜,而这个猜的过程,在我们看来就是一本正经地胡说八道。
实践中的应对策略
理解了幻觉产生的原因,实际工作中怎么处理这个问题就有了方向。RAG检索增强是目前最主流的方案,这个技术现在几乎成标配了。RAG的核心思路是给模型配一个"外挂知识库",模型生成答案之前先去检索相关的真实资料,然后基于检索到的内容来回答,而不是完全靠自己的参数记忆。比如客服机器人回答产品参数问题时,不是让模型凭印象说,而是先从商品数据库里查出准确信息,再让模型基于这些事实组织语言。这样即便模型想"胡说",也会被检索到的真实数据拉回来。RAG的关键在于检索质量,向量相似度检索配合重排序能显著提升召回的准确性。
但RAG不是万能的,它的前提是知识库本身得靠谱且覆盖够全,如果检索不到相关内容,模型还是会回退到自己的参数记忆里去猜。这就是为什么RAG需要配合召回质量监控,检索召回为空的query要特别标记,甚至直接告诉用户"没有找到相关信息"而不是让模型硬编。实践中还要注意数据新鲜度保障,我见过一个案例,智能客服经常给用户推荐已经下架的商品,后来排查发现是向量库更新不及时,模型检索到的是过期信息。建立一套数据同步机制,商品库一旦更新,几分钟内就能同步到向量库,这才真正把幻觉率降下来。
思维链推理是另一个很有效的技巧。思维链就是让模型把推理过程一步步写出来,而不是直接给答案。这种方法能降低幻觉是因为模型在逐步推理时,每一步都有上文作为约束,不太容易跑偏。直接问"这个故障是什么原因",模型可能随便猜一个;但要求它"先列出可能的原因,再逐一分析每个原因的可能性,最后给出结论",这种结构化的推理过程会让答案更靠谱。在prompt里加上"Let's think step by step"或者"请逐步分析",通常就能激活模型的这种能力。
对于特别关键的输出,多模型验证也是个值得考虑的方案。让多个模型分别生成答案,然后对比一致性。如果几个模型都给出相同答案,可信度就高;如果答案分歧很大,说明这个问题模型本身就不确定,需要人工介入。在风控系统生成贷款评估报告时,用两个不同架构的模型(比如GPT和Claude)各生成一份,如果关键结论不一致,就触发人工复核流程。
在医疗和金融这两个领域,幻觉可能直接影响诊疗决策或投资决策,所以一般会采取多重保障。比如AI辅助诊断系统,模型给出的建议必须附带文献引用或病例依据,而且最终决策权必须在医生手里,AI只能作为参考。银行的智能投顾在推荐理财产品时,不会让模型自由发挥,而是限定它只能从已审核的产品库里选,生成的话术也要经过合规审查。这是用系统性约束来防范幻觉风险。
提示工程的一些具体技巧也值得掌握。在prompt里明确告诉模型"如果不知道答案,请说不知道,不要猜测",这一句话能显著降低编造率。要求引用来源也有帮助,比如在知识问答场景,可以在prompt里加上"请在回答后注明信息来源",这会倒逼模型去检索依据而不是随便说。通过JSON Schema或者正则表达式限定输出格式,比如要求模型输出的价格必须是数字类型,这样能避免它编造"大约几百块"这种模糊表述。
评估幻觉也需要方法。业界常用的是事实一致性检测,就是把模型生成的陈述句和知识库里的事实做对比,看是否冲突。技术上可以用NLI自然语言推理模型来做这个判断。人工评估虽然成本高但目前还是金标准,关键业务会抽样做人工标注,建立幻觉样本库,然后用这个库来训练自动检测模型。自动化指标可以看困惑度和置信度,模型输出时的概率分布如果特别分散,困惑度很高,往往预示着它在"猜",这时候就需要特别警惕。
开发中的最佳实践是建立分层防护。第一层是在模型侧设置置信度阈值,低于阈值的输出自动标记为不确定;第二层是在业务侧做规则校验,比如生成的数值是否在合理范围内;第三层是人工抽检关键输出,尤其是对外发布的内容。客服机器人回答商品问题时,如果模型的置信度低于0.7,先从FAQ库匹配标准答案;匹配不到就转人工;即便自动回复了,也会对涉及价格、保修期这类关键信息的回复做后置审核。幻觉问题不可能完全消除,但通过这种系统性的防护机制,可以把风险控制在可接受范围内,这才是工程上务实的做法。
技术演进与前沿思考
幻觉问题本质上是AI从"能用"到"敢用"的最大障碍。技术demo可以容忍偶尔的错误,但一旦要对外提供服务,用户对准确性的预期是非常高的,哪怕九十九次都对,一次离谱的错误就会摧毁信任。这也是为什么很多AI产品还在做小范围灰度,不敢全量上线,因为容错空间太小了。
不同规模模型的幻觉表现存在差异。一般来说,参数量更大、训练数据更多的模型,幻觉率会相对低一些,因为它见过的知识更广,遇到盲区的概率小。但这不是绝对的,小模型如果在特定领域做过精细的微调和数据清洗,在垂直场景可能反而比大模型更可靠。开源模型和闭源模型也有差别,闭源模型比如GPT-4往往经过了大量的RLHF和安全对齐,在回答敏感问题或者不确定问题时会更谨慎,而有些开源模型可能缺少这层保障,更容易"信口开河"。不过开源的好处是你能看到训练数据和流程,知道它的知识边界在哪,用起来反而心里有数。
从前沿技术来看,Constitutional AI和RLHF是当前缓解幻觉的重要方向。Constitutional AI的思路是给模型定一套"宪法原则",训练时不仅让它学会生成流畅的文本,还要学会自我批判,问自己"这个回答是不是违反了某条原则",比如"是否编造了不存在的事实"。RLHF则是通过人类反馈来调整模型的生成倾向,让它知道什么样的回答会被人类打高分。这些技术本质上是在训练阶段就植入对准确性的追求,而不是仅仅依赖生成阶段的工程手段来补救。
这个方向的挑战在于怎么大规模获取高质量的人类反馈,因为标注成本很高,而且不同标注员的标准可能不一致,这也是为什么各家大厂都在探索用AI辅助标注或者主动学习的方法来降低成本。往前看,未来的方向可能是让模型明确表达不确定性,就像人说话一样,确定的事情说得斩钉截铁,不确定的事情会说"我不太确定但可能是",这种诚实比假装什么都知道更有价值。
理解幻觉问题不仅是掌握一个技术概念,更重要的是建立对AI局限性的清醒认知。技术方案只是一方面,数据新鲜度保障、人工复核机制、系统性约束这些工程实践同样关键。正是因为理解了幻觉产生的根本原因,我们才能设计出针对性的解决方案,让AI系统在保持创造力的同时,也能守住准确性的底线。