精炼回答
Temperature参数控制大模型输出的随机性程度,它影响softmax函数对token概率分布的平滑度。具体来说,Temperature作为分母调整logits:较低的Temperature(如0.1-0.5)会让高概率token更加突出,模型倾向于选择最可能的词,输出更确定、保守、一致;较高的Temperature(如0.8-1.5)会拉平概率分布,让低概率token也有更多机会被选中,输出更多样化、创新,但也可能不太连贯。
什么时候调低?需要准确性和一致性的场景,比如代码生成、数学计算、信息抽取、客服问答、翻译等,这些任务需要标准答案或确定性输出,一般设置0.1-0.3。什么时候调高?需要创造性和多样性的场景,比如创意写作、头脑风暴、生成营销文案、角色扮演对话等,你希望得到不同的想法和表达方式,可以设置0.7-1.0甚至更高。
有个实际体感:当你发现模型总是给出相同答案时调高Temperature,当输出开始胡言乱语或偏离主题时调低。很多应用会根据任务类型预设不同值,比如GitHub Copilot用较低值保证代码质量,而ChatGPT的创作模式会用相对高一些的值。
扩展分析
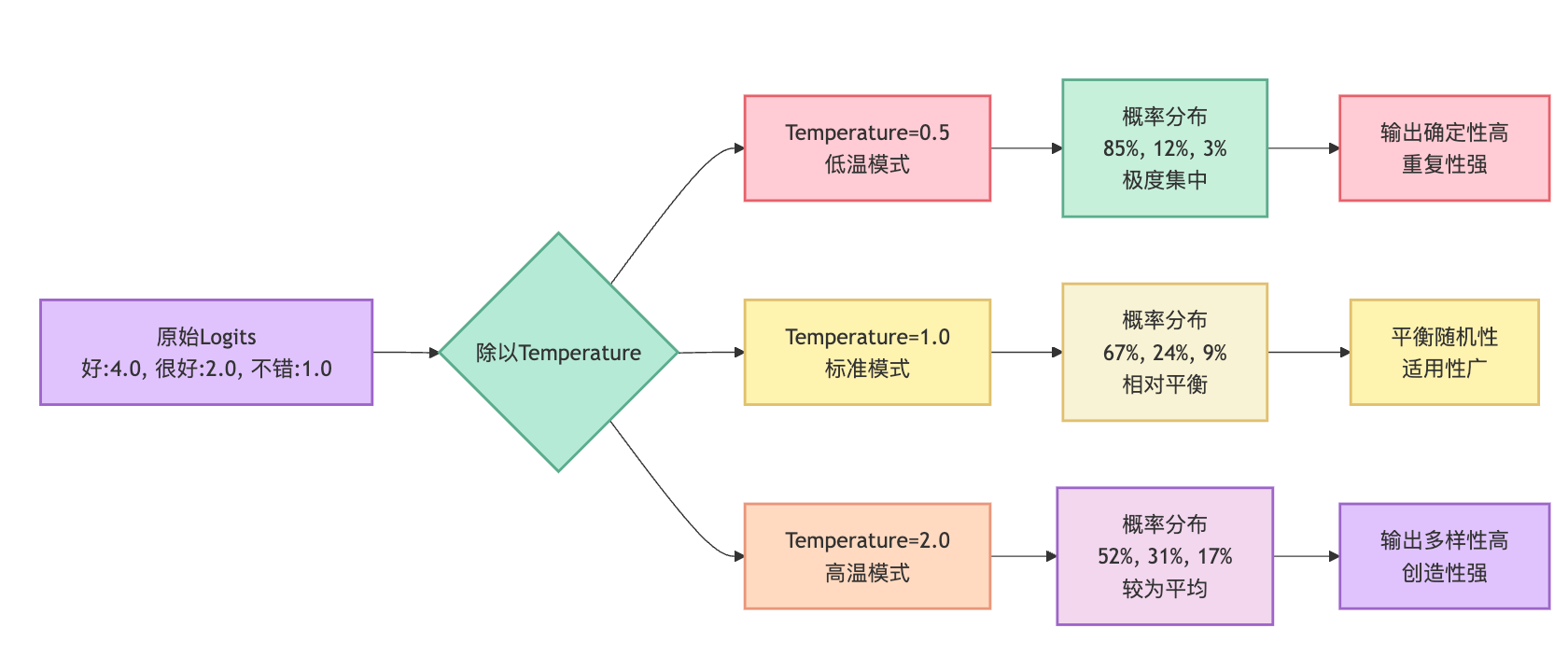
Temperature的本质是作用在Softmax函数上的一个缩放因子。假设模型预测下一个词时,算出来"好"的得分是4.0,"很好"的得分是2.0,"不错"的得分是1.0,这些原始得分叫logits,还不是概率。把它们转成概率的时候,我们用的就是Softmax函数,而Temperature就插在这个环节。公式上体现为把每个logit都除以Temperature值,然后再做指数和归一化。
用具体数字来看分布变化会更清楚。还是刚才那三个词的例子,不同Temperature下概率会这样变化:当Temperature=1.0时,"好"可能得到70%概率,"很好"20%,"不错"10%;当Temperature=0.5时,高分项被强化,"好"会飙到85%,"很好"12%,"不错"只剩3%;当Temperature=2.0时,分布被拉平,"好"降到50%,"很好"涨到30%,"不错"也有20%。变化规律很明显:Temperature越低,概率分布越尖锐,头部效应越明显;Temperature越高,概率分布越平缓,尾部选项获得更多机会。
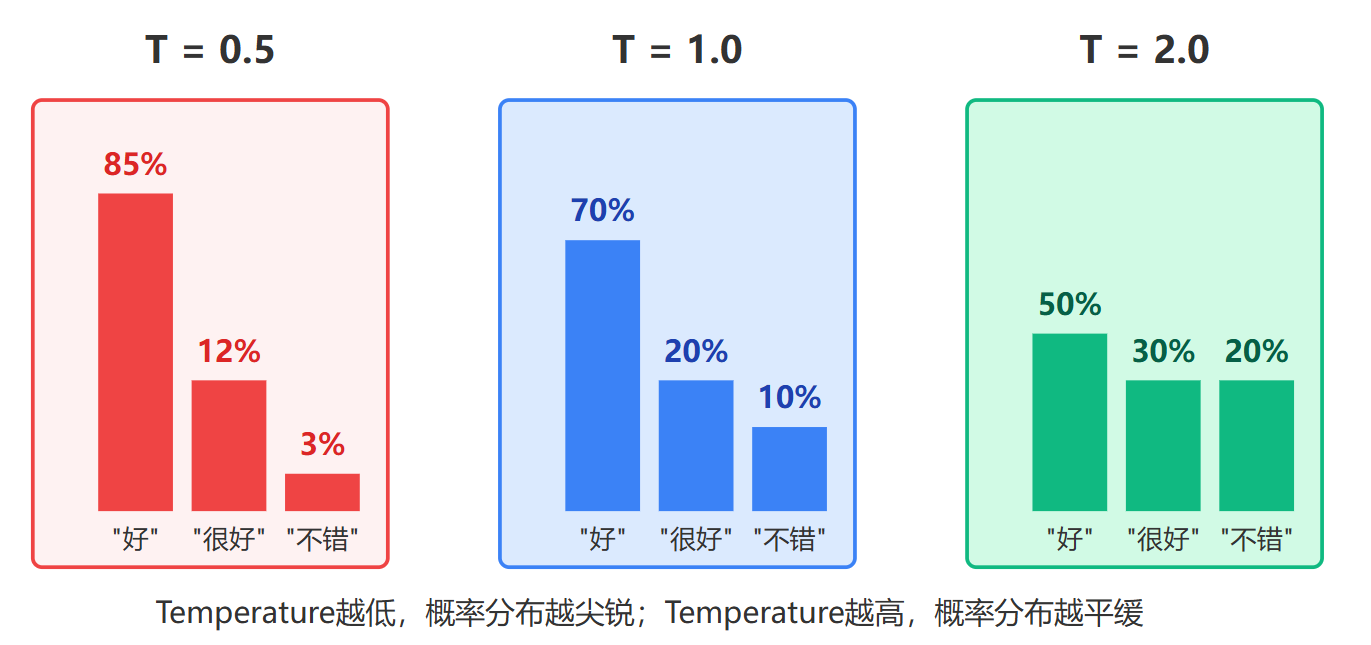
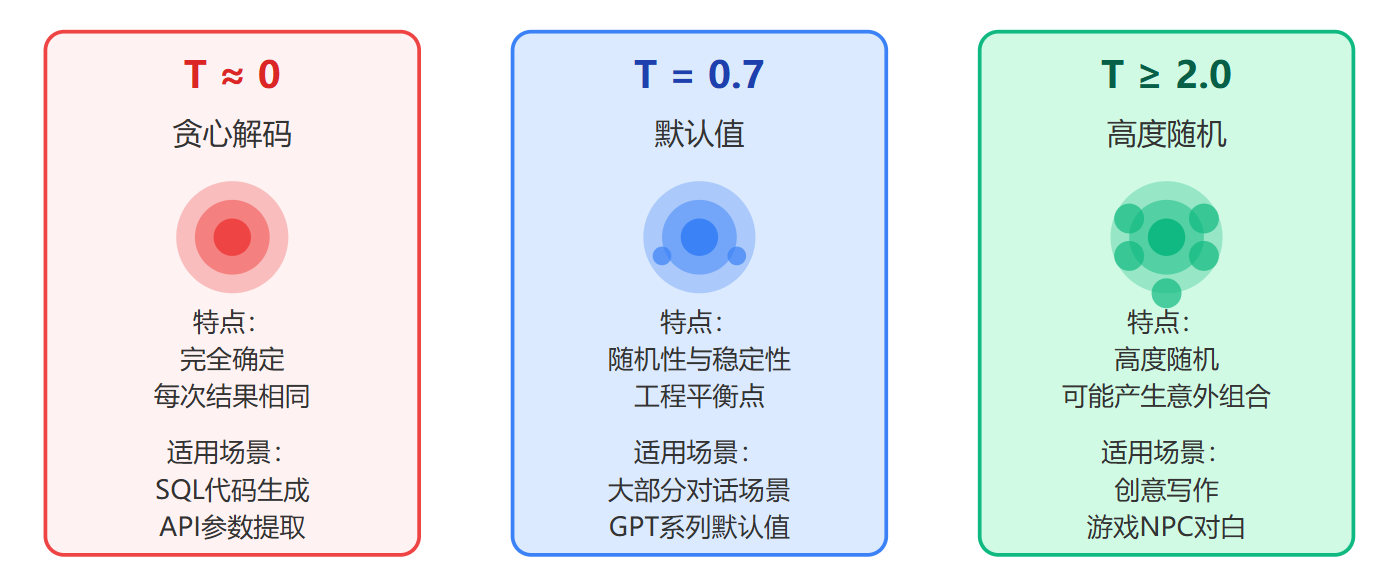
几个特殊值的效果值得记住。Temperature=0是个理论极限,实际应用中会用0.01这种接近零的值来近似,这时候模型会完全确定地选择概率最高的词,每次生成结果都一样,这叫贪心解码。像SQL代码生成、API参数提取这种容错率极低的任务就适合用接近零的值。Temperature=0.7是很多模型的默认值,包括GPT系列,这个值在随机性和稳定性之间找到了一个工程上的平衡点,大部分对话场景都适用。Temperature=2.0或更高就进入了高度随机区域,模型可能会说出一些意想不到的词组合,创意写作或者游戏NPC对白生成会用到,但风险是可能产生不通顺甚至无意义的句子。
有个容易被忽略的技术细节:Temperature调整的是概率分布,但最终选哪个词还要看采样方法。常见的采样有贪心采样(始终选概率最高的)、随机采样(按概率分布随机选)、Top-K采样(只从概率最高的K个候选里选)、Top-P采样(从累积概率达到P的最小候选集里选)。Temperature可以和这些策略组合使用。比如即使Temperature=0.1让分布很尖锐,如果用随机采样理论上还是可能选到低概率词,只是概率极小;而如果用贪心采样,Temperature设多少都是选最高概率的那个。实际生产中经常看到的组合是:Temperature=0.7 + Top-P=0.9这样的配置,既有一定随机性又不至于太发散。
import numpy as np
defsoftmax_with_temperature(logits, temperature):
"""演示Temperature如何影响概率分布"""
# 原始logits除以temperature
scaled_logits = logits / temperature
# 计算softmax
exp_logits = np.exp(scaled_logits - np.max(scaled_logits))
probabilities = exp_logits / np.sum(exp_logits)
return probabilities
# 假设三个词的原始得分
logits = np.array([4.0,2.0,1.0])# "好"、"很好"、"不错"
print("Temperature=0.5 (低温,更确定):")
print(softmax_with_temperature(logits,0.5))
# 输出: [0.84 0.12 0.04] - 第一个词占绝对优势
print("\nTemperature=1.0 (标准):")
print(softmax_with_temperature(logits,1.0))
# 输出: [0.67 0.24 0.09] - 分布相对平衡
print("\nTemperature=2.0 (高温,更随机):")
print(softmax_with_temperature(logits,2.0))
# 输出: [0.52 0.31 0.17] - 概率更加平均这里有个关键特性:Temperature不会改变词的概率排序。无论Temperature是0.1还是2.0,原本得分最高的词在调整后依然概率最高,只是和第二名、第三名的差距被放大或缩小了。用刚才的例子,"好"始终排第一,"很好"始终排第二,只是领先幅度在变化。这个特性很重要,因为它意味着Temperature是个纯粹的随机性调节器,不会引入新的偏好或改变模型的基本判断,只是在控制你要多相信模型的判断还是愿意给其他可能性多少空间。所以调Temperature是安全的,不像调模型权重或者prompt那样可能带来不可预期的语义变化。
实战应用
不同任务对确定性的要求完全不一样,所以Temperature设置也有经验区间。像商品属性提取、FAQ问答、客服机器人这类事实性问答任务,肯定希望每次回答都一致,用户问"退货政策是什么",不能今天说7天明天说15天,这种场景就把Temperature压到0.1到0.3之间,甚至直接用0.01让它完全确定。代码生成是另一个典型场景,虽然也需要准确性,但有时候同一个功能有多种实现方式,完全不给模型发挥空间也不合适,所以稍微放宽一点,用0.2到0.5,既保证语法正确,又允许一些实现细节上的变化。
对话聊天场景就要平衡了,你希望机器人的回复自然不呆板,但也不能每次跑题,这时候0.7到0.9是个甜蜜区间,也是为什么很多模型默认0.7的原因。而创意写作、营销文案生成这些任务,就是要那种"每次都不一样"的惊喜感,可以把Temperature推到0.8甚至1.2,让模型大胆组合词汇。
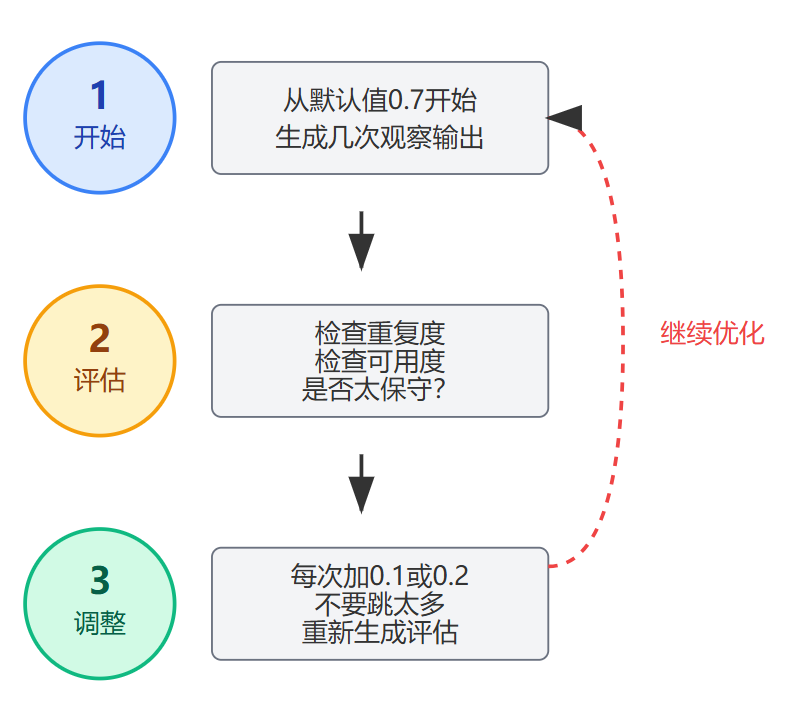
调参时别盲目试数字,要有个系统的方法。先从默认值0.7开始跑几次,观察输出的多样性和质量。如果发现模型连续生成的几段文本几乎一模一样,只是换了几个同义词,那就是太保守了,需要往上调。具体调多少?每次加0.1或0.2,不要一下子跳太多。调完之后再生成同样数量的样本,重点看两个指标:一个是重复度,可以用简单的方法,比如连续10次生成,看有几次输出是明显不同的;另一个是可用度,就是生成的内容里有多少比例是能直接用的,有多少是需要大改甚至完全不能用的。这两个指标一个代表多样性,一个代表质量,你要在它们之间找平衡点。
实际生产中Temperature很少单独使用,最常见的搭配是Temperature加Top-P采样,也叫核采样。这个组合的逻辑是:Temperature调整了概率分布的陡峭程度,但模型的词表可能有几万个词,即使调了Temperature,那些概率极低的词理论上还是有机会被采到。Top-P就是在这个基础上再加一道筛选,比如设置Top-P等于0.9,意思是只从累积概率达到90%的那些候选词里选,把那些概率加起来都不到10%的长尾词直接排除。这样做的好处是既保留了随机性,又把胡言乱语的风险降到最低。经验配置是Temperature=0.7配Top-P=0.9,或者Temperature=0.8配Top-P=0.85,前一个偏稳健,后一个偏创新。还有Top-K采样,比如Top-K=50意思是只从概率最高的50个词里选,这个策略相对粗暴一点,但计算简单,适合对延迟敏感的场景。
publicclassTemperatureConfig{
// 不同场景的Temperature配置策略
publicstaticclassScenarioConfig{
privatedouble temperature;
privatedouble topP;
privateString description;
publicScenarioConfig(double temperature,double topP,String description){
this.temperature = temperature;
this.topP = topP;
this.description = description;
}
}
// 预定义场景配置
publicstaticfinalMap<String,ScenarioConfig> SCENARIO_CONFIGS =Map.of(
"CODE_GENERATION",newScenarioConfig(0.2,0.95,"代码生成,需要准确性"),
"CUSTOMER_SERVICE",newScenarioConfig(0.3,0.9,"客服问答,必须一致"),
"CHAT_CONVERSATION",newScenarioConfig(0.7,0.9,"日常对话,平衡随机性"),
"CREATIVE_WRITING",newScenarioConfig(1.0,0.85,"创意写作,鼓励创新"),
"BRAINSTORMING",newScenarioConfig(1.2,0.8,"头脑风暴,最大化多样性")
);
// 根据任务类型获取推荐配置
publicstaticScenarioConfiggetRecommendedConfig(String scenario){
return SCENARIO_CONFIGS.getOrDefault(scenario,
newScenarioConfig(0.7,0.9,"默认配置"));
}
// 动态调整Temperature的示例
publicstaticdoubleadjustTemperature(double currentTemp,
int repetitionCount,
double qualityScore){
// 如果重复率太高,增加温度
if(repetitionCount >7){
returnMath.min(currentTemp +0.2,1.5);
}
// 如果质量下降,降低温度
if(qualityScore <0.6){
returnMath.max(currentTemp -0.1,0.1);
}
return currentTemp;
}
}有个容易踩的坑:不同模型对Temperature的敏感度是不一样的。同样是0.7,在GPT-3.5上可能输出很稳定,在某个开源模型上可能就开始飘了。这是因为模型训练时的目标函数、数据分布、模型大小都会影响它输出的logits分布形态。小一点的模型,比如7B参数的,本身预测就不够自信,logits分布可能比较平,这时候即使用0.5的Temperature,随机性都可能比大模型用0.8还高。所以在实际使用新模型时,会先用几个典型case跑一遍0.3、0.5、0.7、0.9这几个档位,观察每个档位的实际表现,而不是直接套用之前的经验值。
进阶思考
Temperature这个词其实是从统计物理学借过来的。在物理学里,温度越高,粒子运动越剧烈,分布越均匀;温度越低,粒子倾向于待在低能态,分布越集中。这个类比直接对应到模型生成上,高温让概率分布更分散,低温让概率更集中在头部选项。这也是为什么我们说"高温"生成更有创造性,"低温"生成更确定,这套话语体系背后有物理直觉在支撑。
如果产品经理要你在用户界面上暴露Temperature参数,让用户自己调,直接放个0到2的滑块肯定不行,用户根本不知道该选什么。比较好的做法是转化成场景化的选项,设计成几个档位,比如"准确模式""平衡模式""创意模式",分别对应0.3、0.7、1.0这几个值,用户不需要理解Temperature是什么,只需要知道自己想要什么效果。更进阶一点的做法是根据用户的具体任务类型自动推荐,比如用户选择"写工作邮件"就默认用低温,选择"创作故事"就默认用高温,但保留手动调节的入口给高级用户。这样既降低了使用门槛,又保留了灵活性。

Temperature主要管随机性,但它不是唯一的控制参数。Max Tokens控制生成长度,Frequency Penalty和Presence Penalty控制重复度,前者惩罚高频词让表达更丰富,后者惩罚已出现的词让内容不重复。这几个参数各管一块,实际使用时会组合调整。调参的优先级通常是先定Temperature,因为它影响最大,然后调Max Tokens保证长度合适,最后用Penalty微调来解决重复问题。
不同业务场景的默认参数策略也很有讲究。智能客服系统,你肯定会把默认Temperature设得很低,因为客服最怕说错话,宁可呆板一点也要保证准确。但如果是做内容创作工具,服务的是作家或者营销人员,那默认值就要往上提,因为这些用户来找AI就是要灵感和新意的,太保守反而没价值。还有一种场景是多轮对话,第一轮可以用高一点的Temperature让回答有趣一些,但如果检测到用户在问具体事实性问题,后续轮次要自动降温确保准确性。设置默认参数本质上是在替用户做决策,你要理解用户在这个场景下最核心的诉求是什么,然后用参数去实现它。

调Temperature本质上是个实验过程,没有一劳永逸的万能值。你需要明确任务目标是要确定性还是多样性,然后从经验区间起步,通过小批量测试观察效果,再结合采样策略做微调。这个参数看起来简单,就是一个浮点数,但背后承载的是对生成质量、用户预期、业务场景的深刻理解。