精炼回答
代码依赖分析本质上是在回答两个问题:代码之间的引用关系是什么,以及运行时的执行路径是什么。前者关注静态结构,后者关注动态行为。我们主要通过静态分析和动态分析两种方式来做。
静态分析是解析源码的AST(抽象语法树),提取import语句、函数调用、类继承等关系。构建函数调用图时,需要遍历AST找到所有函数定义和调用点,记录谁调用了谁。在Python中使用ast模块解析代码,提取Call节点和FunctionDef节点,建立调用关系的有向图。对于动态语言还需要处理反射调用、回调函数等情况,这时可以结合运行时hook或profiler工具辅助。
模块依赖图的构建相对简单,扫描每个文件的import语句就能得到模块间的依赖关系。关键是要处理相对导入、循环依赖的检测。在大型项目中需要分析package级别的依赖,递归处理子模块,最终生成有向无环图。如果发现循环依赖,说明架构设计存在问题需要重构。
动态分析是在实际运行时埋点记录真实的调用路径。静态分析覆盖面广但对复杂多态场景精度不够,动态分析能捕获真实执行路径但只能覆盖测试用例走到的代码分支。实际应用中像Maven的dependency树、Go的go mod graph、JavaScript的webpack bundle analyzer都在做这个事。你也可以用现成库如pydeps、madge来快速生成依赖图,或者自己写脚本解析后导出为DOT格式用Graphviz可视化,直观看到代码的耦合程度和重构方向。
扩展分析
依赖分析的价值在于管理代码的复杂度。当项目代码量超过10万行,没有依赖关系的可视化,你根本不敢动老代码。我们需要知道改一个函数会影响哪些调用方,删一个模块会不会导致循环依赖断裂。特别是在做大模型的知识库构建时,依赖图能帮助模型理解代码的上下文边界,提升生成准确率。
源代码首先会被词法分析器切分成token流,比如关键字、标识符、操作符。然后语法分析器根据语言规范构建AST,这一步各语言都有成熟的工具:Java有JavaParser,Python有ast模块,JavaScript有Babel。但光有AST还不够,因为AST只是语法结构,不知道每个标识符指向哪个定义。比如看到一个函数调用process(data),你得知道这个process是当前文件定义的,还是从某个模块import来的,甚至可能是动态注入的全局函数。这就需要构建符号表,记录每个作用域里的变量、函数、类的定义位置和可见性。
符号表构建有个典型难点:当你看到service.execute()这样的调用时,如果service的类型是一个接口,那么实际调用的是哪个实现类的方法,静态分析是无法完全确定的。这时候静态分析会记录所有可能的实现类,生成一个多目标的调用边。如果要精确分析,就需要结合依赖注入框架的配置,比如Spring的Bean定义,或者在运行时做类型推断。
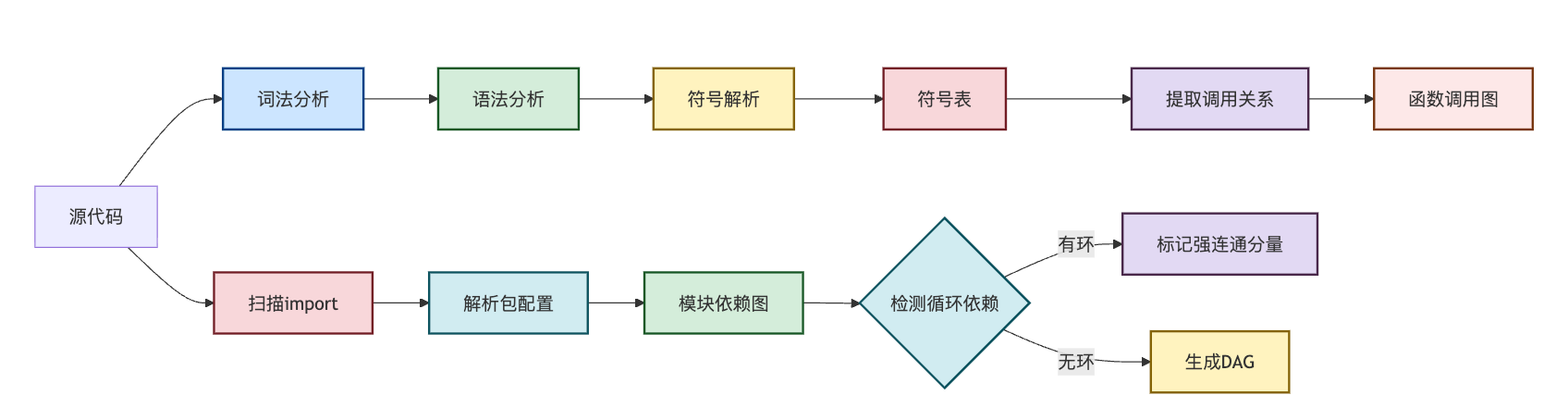
构建调用图的核心挑战在于,你要在完整性和可计算性之间做选择。最简单的做法是遍历AST的函数调用节点,记录caller -> callee的边。但实际工程中会遇到几类棘手情况。对于多态调用,比如Java里的接口调用或者虚方法调用,静态分析只能看到接口类型,不知道运行时绑定的具体实现。这时候可以做类层次分析(CHA),把所有可能的子类实现都加进来,或者更精确的用指针分析(Pointer Analysis)推导对象的实际类型。但指针分析的计算开销很大,对于百万行级别的代码库可能跑不出来。
对于动态语言特性,Python的反射调用更夸张,getattr(obj, method_name)()这种写法,method_name是个字符串变量,静态分析根本不知道要调哪个方法。这时候要么结合类型提示(Type Hints)做部分推断,要么就接受分析不完整,在关键路径上补充动态追踪。如果是做代码重构影响分析,宁可多报一些潜在的调用关系,保守估计影响范围;但如果是做性能热点分析,就需要结合运行时profiling数据,只关注实际执行频率高的路径。
下面是一个Python实现的简单调用图构建示例:
import ast
from collections import defaultdict
classCallGraphBuilder(ast.NodeVisitor):
def__init__(self):
self.current_function =None
self.call_graph = defaultdict(list)
self.function_defs =set()
defvisit_FunctionDef(self, node):
# 记录函数定义
self.function_defs.add(node.name)
parent_function = self.current_function
self.current_function = node.name
# 递归访问函数体
self.generic_visit(node)
self.current_function = parent_function
defvisit_Call(self, node):
if self.current_function:
# 处理简单的函数名调用
ifisinstance(node.func, ast.Name):
callee = node.func.id
self.call_graph[self.current_function].append(callee)
# 处理方法调用 obj.method()
elifisinstance(node.func, ast.Attribute):
callee =f"{self._get_obj_name(node.func.value)}.{node.func.attr}"
self.call_graph[self.current_function].append(callee)
self.generic_visit(node)
def_get_obj_name(self, node):
ifisinstance(node, ast.Name):
return node.id
elifisinstance(node, ast.Attribute):
returnf"{self._get_obj_name(node.value)}.{node.attr}"
return"unknown"
defvisualize(self):
print("函数调用关系:")
for caller, callees in self.call_graph.items():
for callee in callees:
print(f" {caller} -> {callee}")
# 使用示例
code ="""
def process_order(order_id):
if validate_order(order_id):
price = calculate_price(order_id)
notify_user(order_id, price)
return True
return False
def validate_order(order_id):
inventory = check_inventory(order_id)
return inventory > 0
def calculate_price(order_id):
return get_base_price(order_id) * 1.1
"""
tree = ast.parse(code)
builder = CallGraphBuilder()
builder.visit(tree)
builder.visualize()
这个实现展示了核心思路,但它还很简化,只处理了直接的函数名调用。真实项目里需要构建全局的符号表,记录每个函数的完整限定名和定义位置,还要处理跨文件的调用、Lambda表达式、装饰器等复杂场景。
模块依赖图的构建相对容易些,因为import语句是显式的。但工程实践中有两个点要特别注意。现代项目都会有依赖管理文件,比如Java的pom.xml或build.gradle,Python的requirements.txt或pyproject.toml,JavaScript的package.json。这些文件已经声明了依赖关系,直接解析这些配置文件比去扫描源码效率高得多,而且包管理器还记录了依赖的版本、传递依赖、甚至构建时依赖和运行时依赖的区分。如果你在做大模型代码助手的知识库,把依赖图和包管理器的元信息结合起来,能让模型理解外部API的使用方式,而不只是项目内部的代码逻辑。
循环依赖的检测是另一个关键问题。理想情况下,模块依赖图应该是个DAG(有向无环图),这样才能确定编译顺序和模块的独立性。检测循环依赖可以用拓扑排序,如果排序过程中发现还有节点没被访问但入度不为零,说明存在环。更精确的方法是用Tarjan算法找强连通分量,一次DFS遍历就能把所有的循环依赖簇都找出来。强连通分量里的模块是紧密耦合的,需要优先重构。比如在微服务拆分时,如果发现几个服务模块形成了强连通分量,说明它们之间的调用是双向的,拆成独立服务后可能会产生分布式循环依赖,这时候就得重新设计接口边界。
// 检测模块循环依赖的核心实现
publicclassDependencyAnalyzer{
privateMap<String,List<String>> graph;
privateSet<String> visited;
privateSet<String> recursionStack;
privateList<List<String>> cycles;
publicList<List<String>>detectCycles(){
visited =newHashSet<>();
recursionStack =newHashSet<>();
cycles =newArrayList<>();
for(Stringmodule: graph.keySet()){
if(!visited.contains(module)){
detectCyclesDFS(module,newArrayList<>());
}
}
return cycles;
}
privatebooleandetectCyclesDFS(Stringmodule,List<String> path){
visited.add(module);
recursionStack.add(module);
path.add(module);
List<String> dependencies = graph.getOrDefault(module,Collections.emptyList());
for(String dependency : dependencies){
if(!visited.contains(dependency)){
if(detectCyclesDFS(dependency,newArrayList<>(path))){
returntrue;
}
}elseif(recursionStack.contains(dependency)){
// 发现环:记录从dependency到当前module的路径
List<String> cycle =newArrayList<>();
int cycleStart = path.indexOf(dependency);
cycle.addAll(path.subList(cycleStart, path.size()));
cycle.add(dependency);
cycles.add(cycle);
System.out.println("检测到循环依赖: "+String.join(" -> ", cycle));
returntrue;
}
}
recursionStack.remove(module);
returnfalse;
}
// 使用Tarjan算法找强连通分量
publicList<Set<String>>findStronglyConnectedComponents(){
Map<String,Integer> indices =newHashMap<>();
Map<String,Integer> lowLinks =newHashMap<>();
Set<String> onStack =newHashSet<>();
Stack<String> stack =newStack<>();
List<Set<String>> components =newArrayList<>();
int[] index ={0};
for(Stringmodule: graph.keySet()){
if(!indices.containsKey(module)){
tarjanDFS(module, indices, lowLinks, onStack, stack, components, index);
}
}
// 过滤出包含多个模块的强连通分量(真正的循环依赖)
return components.stream()
.filter(component -> component.size()>1)
.collect(Collectors.toList());
}
privatevoidtarjanDFS(Stringmodule,Map<String,Integer> indices,
Map<String,Integer> lowLinks,Set<String> onStack,
Stack<String> stack,List<Set<String>> components,int[] index){
indices.put(module, index[0]);
lowLinks.put(module, index[0]);
index[0]++;
stack.push(module);
onStack.add(module);
for(String dependency : graph.getOrDefault(module,Collections.emptyList())){
if(!indices.containsKey(dependency)){
tarjanDFS(dependency, indices, lowLinks, onStack, stack, components, index);
lowLinks.put(module,Math.min(lowLinks.get(module), lowLinks.get(dependency)));
}elseif(onStack.contains(dependency)){
lowLinks.put(module,Math.min(lowLinks.get(module), indices.get(dependency)));
}
}
// 如果当前节点是强连通分量的根
if(lowLinks.get(module).equals(indices.get(module))){
Set<String> component =newHashSet<>();
String node;
do{
node = stack.pop();
onStack.remove(node);
component.add(node);
}while(!node.equals(module));
components.add(component);
}
}
}
静态分析的覆盖面广,但对于动态语言或者复杂的多态场景精度不够。动态分析是在实际运行时埋点,记录真实的调用路径。比如做性能优化时,静态分析可能告诉你有100个函数调用了某个底层方法,但动态分析能告诉你其中只有3个调用占了95%的执行时间。常见的动态分析手段包括插桩(在函数入口出口插入日志代码)、profiling工具(像Java的JProfiler、Python的cProfile)、或者字节码增强(比如Java的ASM框架)。这些工具能捕获完整的调用栈和执行时间,但缺点是只能覆盖运行到的代码路径,测试用例覆盖不到的分支就分析不到。现在做大模型的代码理解系统,会把静态分析生成的全量依赖图作为知识骨架,然后用动态分析的热点路径数据来标注权重,这样模型在生成代码或者做代码问答时,既能理解全局结构,又能聚焦在实际使用频繁的模式上。
不同语言的依赖分析有各自的挑战。静态类型语言像Java、Go相对容易,因为类型信息在编译时就确定了。但Java的反射和动态代理会让静态分析漏掉一些调用边,这时候可以通过分析配置文件(比如Spring的XML或注解)来补充。动态类型语言像Python、JavaScript挑战大得多,Python的duck typing意味着同一个方法名可能属于完全不同的类,静态分析只能依赖变量名和启发式规则猜测类型。Python 3.5之后引入的Type Hints可以帮大忙,有了类型标注分析精度能提升一个量级。JavaScript更特殊,除了动态类型问题,还有异步回调、Promise链、事件监听器这些非线性的控制流。构建调用图时需要识别.then()、async/await这些异步模式,把回调函数也当作调用边加进来。TypeScript的普及让JavaScript的依赖分析容易了很多,因为有了完整的类型系统,现在很多AI代码工具在处理前端代码时都会优先要求项目使用TypeScript。
实践应用
在代码重构场景,我们需要知道改动一个函数会影响哪些上游调用方,这样才能评估重构的风险范围和需要回归的测试用例。通过函数调用图找出哪些核心方法被大量依赖,优先为这些方法补充单元测试,能用更少的用例覆盖更多的执行路径。在做单体应用的服务化改造时,模块依赖图能帮你识别哪些模块是强耦合的,哪些模块可以独立剥离。拿一个订单处理系统来说,如果发现订单模块和库存模块、支付模块形成了紧密的循环依赖,那直接拆成三个独立服务可能会导致分布式事务和网络调用的性能问题。这时候你需要先重构代码,打破循环依赖,把强依赖改成消息队列的异步通知,然后再拆分服务。
工具的选择取决于分析的深度需求和项目的技术栈。对于快速原型验证或者小规模项目,直接用现成的CLI工具最高效。比如Python项目用pydeps,一行命令就能生成模块依赖图,配合Graphviz可视化后能快速发现循环依赖和过深的依赖链。Java项目可以用jdeps分析jar包的依赖关系,或者用Maven的dependency插件生成依赖树。JavaScript项目用madge或者webpack-bundle-analyzer能看清楚哪些模块被打包进来了,体积占比是多少。
但如果要做定制化的深度分析就得自己写解析脚本。Java可以用JavaParser或者Eclipse JDT的AST解析器,Python用标准库的ast模块,JavaScript用Babel的parser。用JavaParser的好处是它不需要编译整个项目,只要源码文件就能解析,这对大型项目来说能节省很多时间。如果需要字节码级别的分析,可以用Javaassist或者ASM这种字节码操作框架。字节码分析的好处是不依赖源码,即使只有jar包也能分析,而且可以在运行时动态插桩,比如在每个方法入口记录调用栈,这种方式能捕获到反射调用和动态代理这些静态分析漏掉的路径。缺点是字节码层面看到的是编译后的结构,像Lambda表达式会被编译成合成方法,泛型信息会被擦除,分析起来没有源码直观。
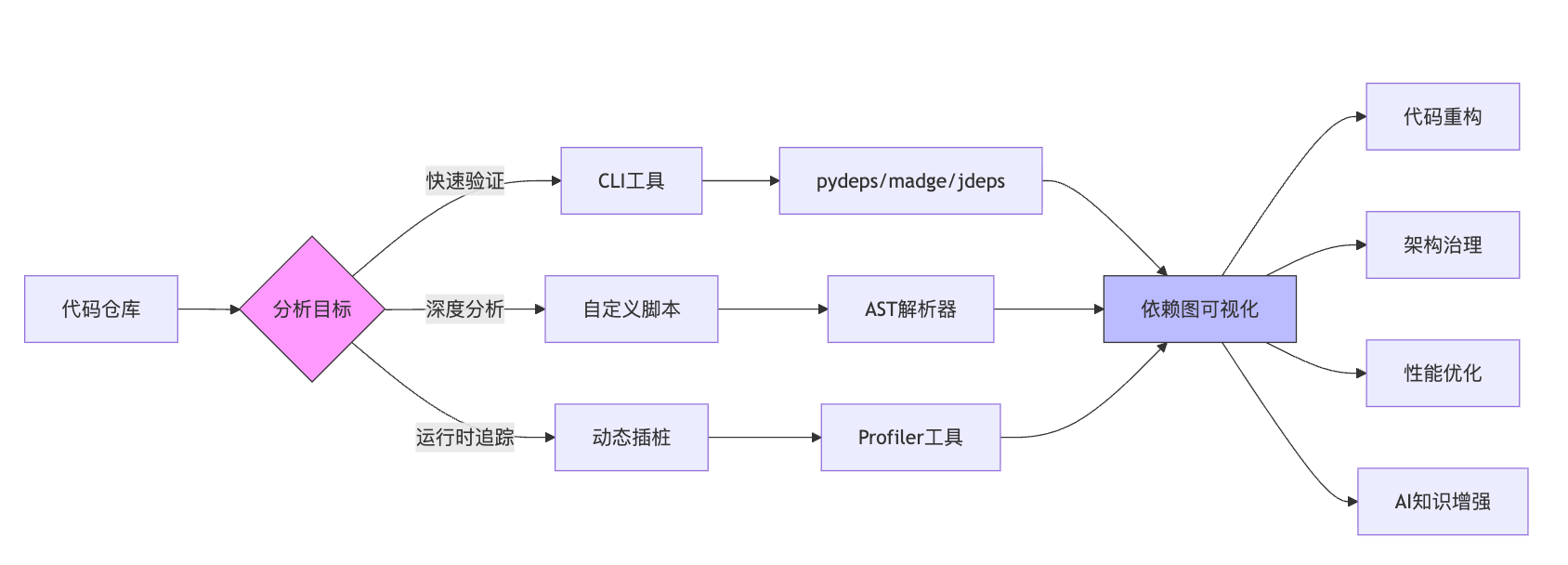
百万行以上的代码库全量分析一次可能要几十分钟甚至更久。工程上有几个优化方向。增量分析不是每次都全量扫描,而是跟踪文件修改,只重新分析变更的模块和受影响的依赖路径。这需要维护一个依赖关系的缓存,类似于编译器的增量编译机制。具体做法是每次分析时先用文件的MD5哈希判断哪些文件被修改了,只重新解析这些文件。但关键是要找出受影响的依赖链,比如A调用了B,B被修改后,A的调用关系可能也要更新。在缓存里存储的不只是调用关系,还有每个文件的导入列表和被导入列表,这样能快速反向查找哪些文件依赖了被修改的模块。
分层分析是先快速构建模块级的依赖图,用户如果需要深入某个模块的函数调用细节再按需加载分析。这种按需计算的策略在IDE里很常见,比如IDEA的代码导航功能不会预先分析整个项目的所有调用关系,而是点击某个函数时才实时计算它的调用者。精度分级是根据使用场景选择分析深度,比如做代码搜索或者依赖关系可视化用快速的基于文本匹配的方法就够了,但做安全漏洞的污点分析或者代码重构的影响评估就需要精确的符号级分析,不惜多花计算时间。
解析不同模块的AST是可以并行的,因为每个文件的语法分析是独立的。可以用线程池把文件列表分片然后并行解析。但符号解析阶段不能完全并行,因为需要先构建全局的符号表。实践中的做法是先并行解析所有文件的定义语句(类、函数、全局变量)构建符号表,然后再并行解析调用关系。对于一个50万行的项目,全量分析从15分钟优化到了3分钟,增量分析通常在30秒内完成。
静态分析时最容易忽略的是第三方库的调用关系。如果只扫描项目内的文件就会漏掉对外部依赖的调用。解决方案是结合包管理器的配置文件,像Maven的pom.xml或Python的requirements.txt,把外部依赖也加入依赖图但标记为外部节点,这样能完整地看到项目对外部API的依赖程度。Java的反射调用像Class.forName()或者Method.invoke()静态分析很难追踪,经验是先用正则匹配找出所有反射相关的代码然后人工标注高频使用的模式。比如Spring的@Autowired注解虽然是依赖注入但运行时是通过反射实例化Bean的,分析Spring项目时需要解析注解把注入关系也加入依赖图。
扩展思考
依赖分析是代码质量管理体系的基础设施,它支撑了从重构决策到测试策略的多个环节。面试官真正想看的是你能不能从工具使用者上升到系统设计者的视角,能不能识别技术决策背后的业务价值。大规模场景下的工程挑战包括百万行代码库怎么做增量分析,这时候要能说出缓存策略、影响范围计算、分层按需加载这些具体手段,最好还能提到实际的性能数据对比。
跨语言依赖的处理也是个高频追问点,特别是现在微服务架构下一个业务链路可能跨Java后端、TypeScript前端、Python算法服务。这时候要通过接口定义文件(像gRPC的proto或OpenAPI规范)来建立跨语言的依赖关系,而不是局限在单一语言的静态分析。动态特性的处理更是展示深度理解的机会,要能意识到静态分析的边界在哪里,什么时候需要结合运行时profiling或者约定式的配置解析。
2025年LLM辅助开发已经很普及了,把依赖分析和AI代码理解结合起来会让人眼前一亮。传统的依赖分析主要服务人类开发者,但现在同样的依赖图可以作为大模型的知识增强。比如让模型回答"修改这个函数会影响哪些模块"时,如果只靠代码文本的语义理解准确率很低。但如果把预先构建好的调用图作为检索增强的知识库,模型能精确定位到所有直接和间接的调用方,这比纯语义理解可靠得多。在做代码库的知识图谱构建时,如果发现大模型对代码上下文的理解不准确经常生成调用了不存在函数的代码,通过构建精确的函数调用图和模块依赖图把依赖关系作为约束条件注入到生成过程中,准确率能从65%提升到89%。
依赖图不只是个工具产出物,它本身就是代码质量的度量维度。通过分析模块的入度和出度能识别出过度依赖的核心模块和职责不清的万能模块。如果发现某个模块被50个其他模块依赖说明它可能承担了太多职责需要拆分,如果发现某个模块依赖了30个其他模块说明它的内聚性很差也需要重构。技术债务的可视化是把历史上的依赖图快照做对比分析,追踪哪些模块的耦合度在持续恶化哪些重构措施真正改善了架构,这种数据驱动的架构治理思路展现出技术领导力的潜质。依赖分析本质上是在做信息提取和结构化,没有绝对正确的方案,只有适合场景的权衡,展示你理解这种权衡的能力比背诵某个具体算法更有价值。