精炼回答
评估AI Agent响应质量需要建立多维度的评价体系。准确性评估是核心,通过人工标注建立ground truth数据集,计算Agent回答的事实正确率和逻辑一致性。相关性评估使用BLEU、ROUGE等指标衡量回答与问题的匹配度,同时引入语义相似度计算确保回答切题。
实时评估机制包括用户反馈收集(点赞/点踩、满意度评分)和行为分析(用户是否继续提问、会话时长)。对于客服场景,可以追踪问题解决率和用户转人工比例;对于代码助手,监控生成代码的编译通过率和执行成功率。
改进策略主要包括数据层面优化和模型调优。通过错误案例分析识别知识盲区,补充训练数据或更新知识库。使用RLHF(人类反馈强化学习)根据评估结果调整模型行为偏好。Prompt工程也很关键,通过优化指令模板和上下文设计提升响应质量。
建议搭建A/B测试框架,对比不同版本的Agent表现,并建立持续监控dashboard跟踪关键指标变化。同时要根据具体应用场景调整评估权重,比如金融场景更注重准确性,创意写作场景更看重多样性和创新性。
扩展分析
深度技术解析
AI Agent响应质量的评估改进是一个系统工程,需要从评估、改进、实施三个层面来思考。评估维度包括准确性、相关性和用户体验三大核心指标,每个维度都有对应的量化方法和实时监控机制。改进策略分为数据优化、模型调优和工程实现三个方向,具体实施上会先建立基准测试集,然后搭建A/B测试框架进行迭代优化。
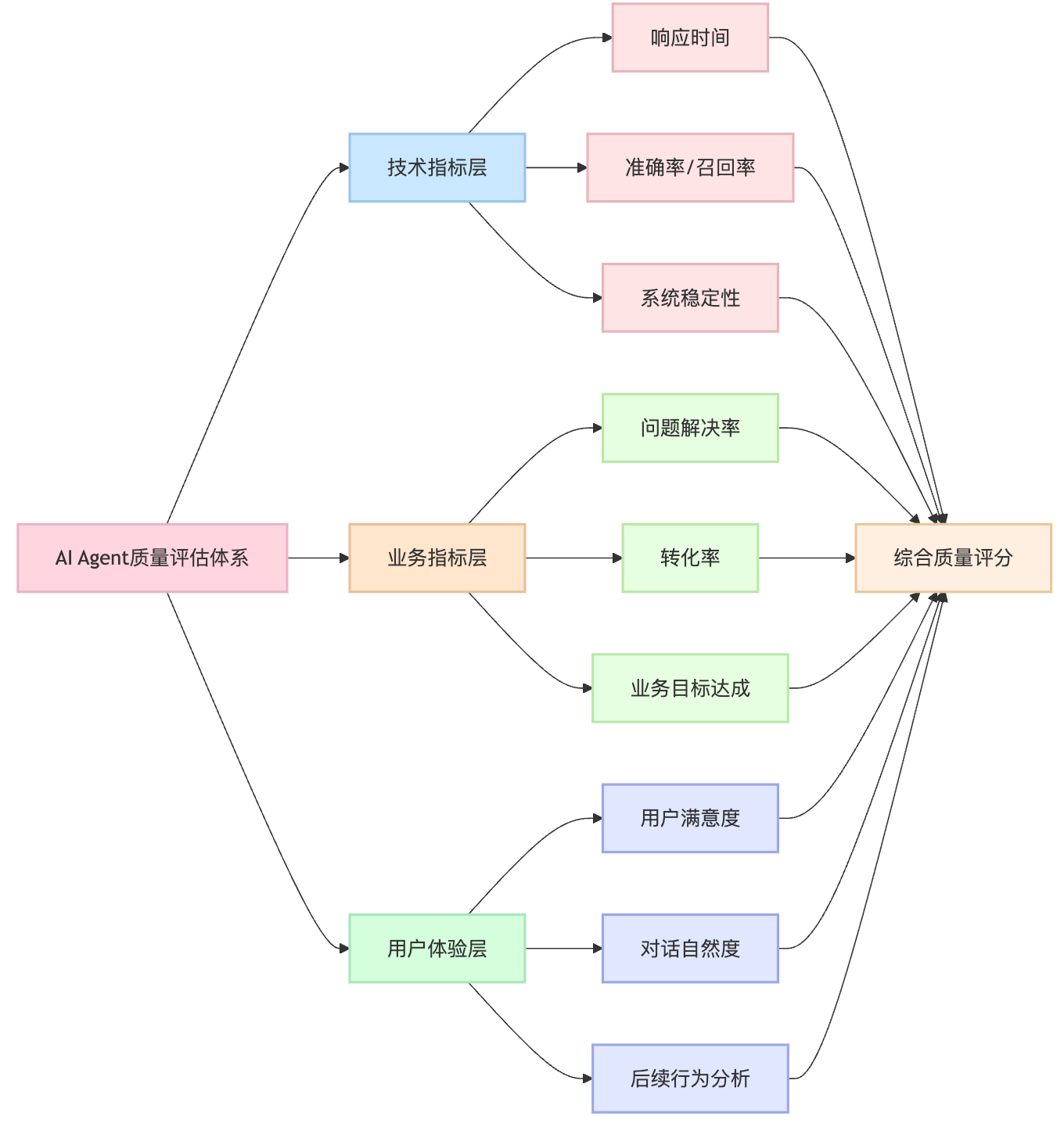
建立评估体系时需要突出分层思维。按照技术指标、业务指标和用户体验指标三个层次来构建评估体系效果最佳。技术指标包括响应时间、准确率、召回率这些可以自动化计算的指标。业务指标则要结合具体场景,拿电商场景举例,智能客服Agent的业务指标就包括订单咨询的解决率、退款流程的引导成功率、商品推荐的点击转化率等。用户体验指标相对主观,但同样重要,比如对话的自然度、回答的有用性、整体满意度等。
技术指标与业务指标之间存在平衡关系。技术指标容易量化但可能脱离实际需求,业务指标贴近目标但受外部因素影响较大。在实际应用中,建立指标权重体系,根据不同场景动态调整各类指标的重要性非常关键。比如在处理售后投诉时,准确性权重会提高,而在商品咨询场景下,响应速度和推荐相关性的权重会更大。
数据收集的实时性和多样性决定了评估效果。评估数据来源包括用户显性反馈、隐性行为数据和专家评估三个渠道。用户显性反馈就是点赞点踩、评分、文字评价等直接表达。隐性行为数据更有价值,包括用户是否继续追问、会话时长、是否中途退出对话、后续是否转人工客服等。专家评估则通过人工抽样的方式,定期对Agent回答进行专业标注。
publicclassAgentQualityMetrics{
privateUserFeedbackCollector feedbackCollector;
privateBehaviorAnalyzer behaviorAnalyzer;
privateExpertEvaluator expertEvaluator;
publicQualityScorecalculateRealTimeScore(String sessionId,String response){
// 实时计算响应质量分数
double relevanceScore =calculateSemanticRelevance(response);
double accuracyScore =validateFactualAccuracy(response);
double userSatisfaction = feedbackCollector.getRecentFeedback(sessionId);
// 结合用户行为数据
UserBehavior behavior = behaviorAnalyzer.analyze(sessionId);
double behaviorScore =calculateBehaviorScore(behavior);
returnnewQualityScore(relevanceScore, accuracyScore, userSatisfaction, behaviorScore);
}
privatedoublecalculateBehaviorScore(UserBehavior behavior){
double score =0.5;// 基础分
if(behavior.isSessionEndedNaturally()){
score +=0.3;// 自然结束对话,说明问题得到解决
}
if(behavior.getFollowUpQuestions()==0){
score +=0.2;// 没有追问,回答可能比较完整
}
if(behavior.isTransferredToHuman()){
score -=0.4;// 转人工,说明Agent未能解决问题
}
returnMath.max(0,Math.min(1, score));
}
}
根因分析思路是区分初级和高级工程师的重要标准。发现质量问题后,需要从数据、模型、工程三个维度进行根因分析。数据维度检查训练数据的覆盖度、标注质量、数据分布是否均衡;模型维度分析是否存在过拟合、知识边界不清晰、上下文理解偏差等问题;工程维度排查prompt设计、参数配置、系统集成等环节的问题。
建立错误案例分析流程,对每类问题进行标签分类,然后统计各类问题的出现频率和影响程度,这样就能找到优化的优先级。比如发现Agent在处理退款政策咨询时准确率偏低,通过分析发现是因为电商平台的退款规则经常更新,但知识库同步不及时导致的,这就是典型的数据层面问题。
实战落地方案
技术栈选择需要根据团队规模和业务复杂度来决定。对于初期团队,推荐使用开源方案快速搭建基础框架,比如用Prometheus + Grafana做监控,用MLflow管理模型版本和实验记录。如果是大规模应用,会考虑自研评估平台,集成更丰富的自定义指标和业务逻辑。建立从数据收集到决策执行的完整链路非常重要,用户交互数据通过埋点系统实时采集,存储到数据湖中进行离线分析,同时搭建流式计算管道,对关键指标进行实时监控和预警。
publicclassQualityMonitoringPipeline{
privateKafkaConsumer<String,UserInteraction> consumer;
privateQualityScoreCalculator calculator;
privateAlertingService alertingService;
privateMetricsStorage metricsStorage;
privatestaticfinaldouble QUALITY_THRESHOLD =0.7;
publicvoidprocessRealTimeData(){
while(true){
ConsumerRecords<String,UserInteraction> records = consumer.poll(Duration.ofMillis(100));
for(ConsumerRecord<String,UserInteraction>record: records){
UserInteraction interaction =record.value();
QualityMetrics metrics = calculator.evaluate(interaction);
// 存储指标数据
metricsStorage.store(metrics);
// 实时监控和预警
if(metrics.getOverallScore()< QUALITY_THRESHOLD){
alertingService.sendAlert(createAlert(metrics, interaction));
}
// 触发自动优化流程
if(shouldTriggerOptimization(metrics)){
optimizationService.scheduleOptimization(interaction.getContext());
}
}
}
}
privateAlertcreateAlert(QualityMetrics metrics,UserInteraction interaction){
returnAlert.builder()
.severity(determineSeverity(metrics))
.message("Quality score below threshold: "+ metrics.getOverallScore())
.context(interaction.getContext())
.timestamp(System.currentTimeMillis())
.build();
}
}
A/B测试设计时需要特别关注样本分组的随机性和统计功效。用户分组不能简单按照用户ID取模,要考虑用户画像的均衡分布,避免因为用户群体差异导致的偏差。实验周期设定也很关键,太短可能无法观察到真实效果,太长又会影响迭代速度。根据历史数据估算达到统计显著性所需的最小样本量,然后结合业务节奏确定实验周期,通常会设定1-2周的观察期,同时监控是否有明显的负面影响需要提前终止实验。
拿电商场景举例,智能客服Agent的A/B测试就要特别注意控制外部变量。如果测试期间正好遇到大促活动,用户咨询量激增可能会影响Agent的响应质量,这时候需要扩展观察窗口或者调整实验设计。
用户反馈收集的关键在于降低反馈门槛和提高反馈质量。反馈收集不能影响用户的正常使用流程,要做到无感知或者低干扰。可以在对话结束后自然地询问满意度,或者通过用户后续行为来推断满意度。比如用户在得到回答后立即结束对话,可能说明问题得到了解决;如果继续追问或者转人工客服,可能说明回答质量不够好。
publicclassFeedbackCollector{
privateFeedbackRepository feedbackRepository;
privateUserBehaviorAnalyzer behaviorAnalyzer;
publicvoidcollectImplicitFeedback(String sessionId,UserBehavior behavior){
FeedbackScore score =newFeedbackScore();
// 根据用户行为推断满意度
if(behavior.isSessionEnded()&& behavior.getFollowUpQuestions()==0){
score.setImpliedSatisfaction(0.8);// 问题可能得到解决
score.setConfidence(0.7);
}elseif(behavior.isTransferredToHuman()){
score.setImpliedSatisfaction(0.3);// Agent未能解决问题
score.setConfidence(0.9);
}elseif(behavior.getRepeatQuestions()>2){
score.setImpliedSatisfaction(0.4);// 用户重复提问,可能回答不清晰
score.setConfidence(0.8);
}
// 结合会话时长和用户操作频率
double sessionDuration = behavior.getSessionDuration();
double avgResponseTime = behavior.getAvgResponseTime();
if(sessionDuration >0&& avgResponseTime >0){
double engagementScore =calculateEngagementScore(sessionDuration, avgResponseTime);
score.setEngagement(engagementScore);
}
feedbackRepository.save(sessionId, score);
}
privatedoublecalculateEngagementScore(double duration,double avgResponseTime){
// 适中的会话时长和响应时间通常表示良好的用户体验
double idealDuration =120.0;// 2分钟
double idealResponseTime =30.0;// 30秒
double durationScore =1.0-Math.abs(duration - idealDuration)/ idealDuration;
double responseScore =1.0-Math.abs(avgResponseTime - idealResponseTime)/ idealResponseTime;
return(durationScore + responseScore)/2.0;
}
}
进阶思考与发展趋势
指标冲突本质上反映了业务需求的多样性,建立动态权重机制来应对这个问题效果最好。比如在电商客服场景中,日常咨询更注重效率,但投诉处理时准确性权重会大幅提升。这种权重调整需要基于对业务场景的深度理解,而不是单纯的技术指标优化。
随着多模态AI的发展,未来的质量评估会更加复杂,不仅要考虑文本回答,还要评估图片、语音等多种输出形式的质量。这要求我们在设计评估体系时具备前瞻性,能够适应技术发展的趋势。同时要强调用户体验的重要性,技术指标的提升最终要服务于用户价值的创造,特别关注用户在使用过程中的真实感受,而不是单纯追求技术指标的优化。
质量管理涉及算法、工程、产品、运营多个团队,建立定期的质量评审机制必不可少。比如每周进行质量数据回顾,月度进行深度问题分析和改进计划制定。同时要建立明确的责任分工,算法团队负责模型层面的优化,工程团队负责基础设施和工具链,产品团队负责用户体验和需求分析,运营团队负责业务指标的解读和改进建议。
建立质量问题的快速响应流程,确保关键问题能够在24小时内得到初步处理,这对线上服务稳定性至关重要。在实际项目中,经常遇到用户满意度高但业务转化率低的情况,通过分析发现用户喜欢Agent的对话风格,但Agent给出的商品推荐不够精准。这种情况需要重点关注解决问题的思路和方法,而不是单纯炫耀项目规模。
优秀的技术人员不仅要懂技术,更要懂业务、懂用户。把复杂的技术问题转化为清晰的产品价值,这种能力在AI Agent质量管理中尤为重要。未来的发展趋势是技术与业务的深度融合,质量评估体系也会朝着更加智能化、自动化的方向发展。