精炼回答
大模型在数学推理上表现不好,核心原因是训练目标与推理能力不匹配。语言模型本质上是通过next token prediction学习的,这让它擅长模式匹配而非逻辑推演。数学推理需要严格的符号操作、多步骤因果链条和精确计算,但模型容易在中间步骤出错,而且误差会累积放大。特别是涉及大数运算、复杂方程求解时,模型经常产生看似合理但逻辑错误的答案。
提升方法主要有几个方向。首先是让模型显式输出推理过程,像Chain-of-Thought这样的提示技术强迫模型把中间步骤写出来,降低跳步出错的概率。其次是专门的数学数据训练,用高质量的数学题解对数据集做强化,甚至可以用过程监督(Process Supervision)而不仅是结果监督来训练。再就是工具增强,让模型调用Python计算器或符号运算库来处理精确计算部分,模型只负责问题理解和步骤规划。最后,像OpenAI的o1这样采用强化学习做推理时优化,给模型更多思考时间,通过搜索和验证来提高答案质量。本质上就是把统计学习和符号推理结合起来,各取所长。
扩展分析
问题本质:能力错配与误差累积
面试这道题时,你需要在开场就让面试官感觉到你对问题有结构化的理解。不要上来就讲Chain-of-Thought或者某个具体技术,那会显得你只是背了几个名词。面试官更想听到的是你能把问题拆解清楚,展现出工程思维。
大模型在数学推理上的问题,本质上是能力和任务的错配。语言模型是通过预测下一个词训练出来的,它学到的是统计规律而不是逻辑规则。你让它做数学题,就像让一个擅长写作文的人去做精密计算,表面上能输出答案,但中间步骤容易出错,而数学推理最怕的就是一步错步步错。
数学推理的核心是符号操作的严格性和推理链条的因果必然性。当你解一道方程,从第一步移项到最后求出x的值,每一步都必须精确无误,而且步骤之间是强逻辑依赖的。这和写一篇产品描述完全不同。写文案时,你可以说"这件衣服穿起来很舒服"也可以说"上身体验极佳",两种表达都对。但数学里,2+2只能等于4,你写个3.9都是错的,哪怕看起来"差不多"。这种精确性要求就是第一个门槛。
Transformer的自回归机制跟这个需求天然有矛盾。模型生成每个token时,是基于前面所有token的概率分布来预测的。它在训练时学到的是"在这个上下文下,下一个词最可能是什么"。这种机制在生成流畅文本时特别有效,因为自然语言本身就有很强的统计规律性。但数学推理不吃这一套。当模型算到"3x + 5 = 14"的下一步时,正确答案必须是"3x = 9",这不是概率问题,是逻辑必然。可模型没有内置的代数运算规则,它只是见过大量类似的题目,然后统计出"这种pattern下通常应该减5",这本质上是模式匹配而不是真正理解了移项法则。
举个具体的失败案例会让面试官更有感觉。比如让模型计算789×654这种多位数乘法,它经常会输出一个看起来位数差不多、数量级也合理的数字,但仔细一验算完全不对。为什么会这样?因为模型在训练数据里见过很多乘法运算的文本,它知道三位数乘三位数通常得到六位数,知道结果大概在几十万这个范围,但它没法真的去做竖式计算。它生成答案时是在做"这个位置应该填什么数字"的概率预测,而不是真的在计算进位和累加。这就像一个人背了很多算术题答案,碰到新题就凭印象猜,猜得八九不离十但就是不准。
训练数据的问题也值得深入思考。相比文本语料,高质量的数学推理数据其实是稀缺的。网上大量的数学内容都是题目和最终答案,中间的详细解题过程往往被省略或者写得很简略。模型如果只是学"看到这个题,输出那个答案",根本学不到推理能力,只是在记忆题型。更棘手的是,即使有详细步骤的数据,质量也参差不齐。网上的数学讨论帖里,有严谨的解法也有错误的思路,模型分不清哪个是对的,它只知道"这种表达方式在数学上下文里出现过"。这就导致模型可能把错误的推理模式也学进去了。
误差累积是数学推理特别致命的问题。假设模型在一道需要5步求解的题目中,每一步都有90%的准确率,听起来不错对吧?但因为步骤之间是强依赖的,第二步必须基于第一步的正确结果,第三步又依赖第二步,这样连乘下来,最终得到完全正确答案的概率只有0.9的5次方,大约是59%。而且一旦某步出错,后面的步骤即使"执行正确"也是在错误的基础上继续,最终答案几乎必然是错的。这个特性在自然语言生成里影响没那么大,写文章时某个词选得不够精准,不影响后面段落的整体意思。但数学推理里,一个符号写错,整个答案就废了。
面试官可能会追问:"那为什么模型在文本生成上表现这么好,偏偏数学推理不行?"你可以这样解释:文本生成本质上是一个容错性很高的任务。语言是模糊的、冗余的,同一个意思可以用无数种方式表达,读者还能根据上下文自动补全理解。模型只要把大方向把握对,细节上有点瑕疵也不影响整体语义。而且自然语言的训练数据海量且质量整体可控,模型能从几TB的文本里学到丰富的语言规律。相比之下,数学推理是个零容错的任务,容不得半点含糊,而且训练数据的规模和质量都远不如文本语料。这就像培养一个人,给他看一万本小说,他能学会写得文笔流畅;但只给他看一千道数学题,他很难真正掌握数学推理的逻辑框架。
具体的错误类型可以总结几个典型场景,这样显得你对问题有系统性认知。比如符号运算错误,模型可能把-(-3)算成-3而不是3,因为它只是记住了"两个负号"这个pattern常见的处理方式,但没有真正理解符号代数的规则。再比如单位换算问题,题目说"小明以每小时60公里的速度跑了30分钟",问跑了多少公里,模型可能直接输出60,因为它捕捉到了"60"和"公里"这两个关键词的关联,但忽略了时间单位的转换。还有逻辑链断裂的情况,模型在推导过程中可能突然跳步,从A直接跳到C,省略了中间的B,因为它在训练数据里见过很多"A和C同时出现"的例子,于是建立了直接关联,但这个关联在当前题目的逻辑下是不成立的。
提升方案:从提示到训练的全链路优化
当你在面试中把问题分析透彻后,面试官通常会追问具体的解决方案。这时候千万别急着把所有知道的技术名词一股脑倒出来,那会显得你只是在背材料。面试官想看到的是你能把不同层面的解决方案组织成一个清晰的技术演进路线,展现出你对技术选型的判断力。
最直接也最容易实施的改进,就是在推理时做文章。Chain-of-Thought这个思路特别简单,就是在提示词里明确告诉模型"请一步步思考",或者直接给几个示例,展示完整的推理过程是什么样的。这个方法为什么有效?因为它逼着模型把原本隐藏在内部的推理步骤显式地写出来。模型在生成"第一步是移项"这句话的时候,后续的token生成就被这个明确的中间状态约束住了,不太容易跳步或者逻辑断裂。就像你做数学题,如果只在草稿纸上心算很容易错,但写下每一步就能自己检查出问题。
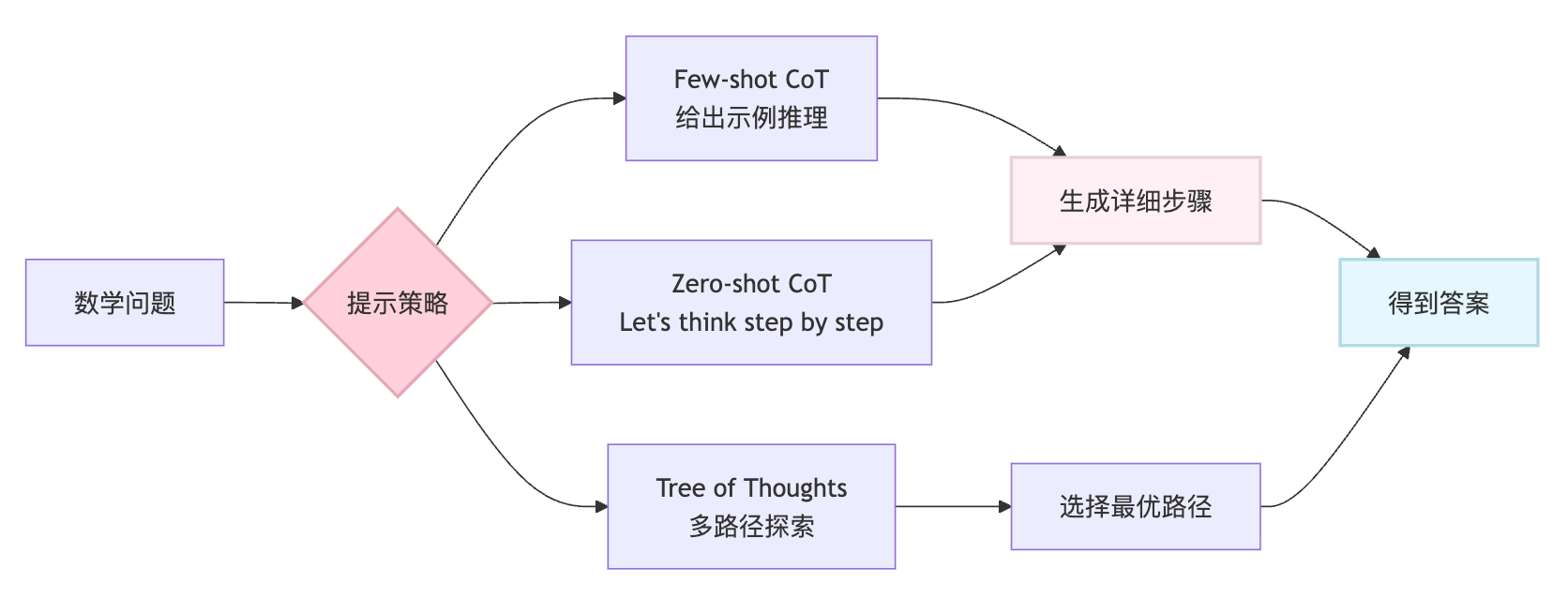
Few-shot CoT就是在提示词里先给两三个例题和详细解答,然后再让模型做新题目,这样模型能从例子里学到"这类题应该怎么拆解步骤"。Zero-shot CoT更简洁,就是一句"Let's think step by step",不给任何例子,纯靠这个指令来激活模型的推理能力。有意思的是,这种极简的提示在很多场景下效果也不错,说明大模型在预训练时确实见过大量的分步推理文本,只是需要一个明确的信号来触发这个模式。实际使用中,Few-shot在复杂题型上更稳定,但需要精心设计示例;Zero-shot更灵活,但对模型能力要求更高,像GPT-4这种大参数模型效果才明显。
更高级的提示策略比如Tree of Thoughts,核心想法是让模型在每个推理节点都生成多个可能的下一步,然后通过某种评估机制选出最优分支继续探索。这就像下象棋时要考虑几步之后的局面,而不是只看眼前一步。当然,这个方法的计算成本会高很多,因为你要为每个分支都跑一遍模型推理,所以更适合那些步骤不太多但每步选择很关键的题目。证明题就很适合用这种方法,因为可能有好几种证明思路,模型可以同时探索"用反证法"和"用数学归纳法"两个方向,看哪个走得通。
聊完提示工程这一层,就该自然过渡到工具增强的思路了。提示工程能提升推理的结构性,但有个根本问题它解决不了——模型对精确计算天生不擅长。你让模型写出再详细的步骤,它算437乘以829还是会出错。这时候就需要把计算的部分外包给真正擅长这件事的工具。现在很多AI应用会给模型配一个代码解释器,当模型意识到需要算一个复杂表达式时,它会生成一段Python代码,调用解释器执行,然后把结果拿回来继续推理。这个模式把劳动分工理顺了——模型负责理解题意、规划步骤、组织逻辑,计算器负责执行精确运算。就像一个工程师做方案设计,具体的数值仿真交给专门的软件来跑。
# 模型生成的推理过程示例
"""
问题:计算 437 * 829 + 156 / 12
推理步骤:
1. 这是一个需要精确计算的数学表达式
2. 包含乘法、加法和除法运算
3. 调用计算器执行
"""
# 模型生成的工具调用
result = calculate("437 * 829 + 156 / 12")
# 计算器返回: 362386.0
# 模型继续推理
"""
4. 得到计算结果 362386.0
5. 因此答案是 362386
"""面试官可能会问:模型怎么知道什么时候该调用工具?有两种常见的实现方式。一种是在训练时就教会模型识别需要计算的场景,让它学会输出特定格式的工具调用指令,比如生成calculator(437 * 829)这样的标记。另一种是用更明确的流程控制,先让模型生成完整的解题规划,然后由外部程序解析这个规划,把涉及计算的部分自动转成代码执行。前者更灵活但对模型能力要求高,后者更可控但需要设计好解析规则。实际产品里,像ChatGPT的Code Interpreter就是前一种思路,而一些专门的数学辅导应用可能会用后者,因为题型相对固定。
工具能解决计算准确性问题,但它处理不了推理逻辑本身的错误。如果模型对题目的理解就是错的,或者规划的解题步骤根本不对路,那计算再准确也没用。而且工具调用会增加延迟和复杂度,每次调用都要跨进程通信,遇到需要频繁交互的题目可能体验不太好。所以工具增强是个很好的补充,但不是万能药。
前面说的都是推理时的优化,治标不治本。要真正提升模型的数学推理能力,还得从训练阶段下功夫。最直接的做法是喂更多高质量的数学数据。这里的关键词是"高质量"——不只是题目和答案,而是完整的、逻辑严密的解题过程。一些公开数据集,比如GSM8K、MATH这些专门的数学推理benchmark,它们都带有详细的解题步骤标注。用这类数据做专门的微调或者混入预训练阶段,能让模型对数学推理的pattern有更深的学习。
更进一步的做法是改变训练目标。传统的监督学习只看最终答案对不对,这种反馈太粗糙了。模型可能因为错误的推理碰巧得到正确答案,也可能一步小错导致最终答案错误但中间大部分步骤都是对的,这两种情况应该得到不同的反馈。过程监督就是针对这个问题设计的,它会对推理过程中的每一步都给出评价,告诉模型"这步是对的""那步逻辑有问题"。这样训练出来的模型,对每个推理步骤的把控会更精细。OpenAI有篇论文专门讲这个,他们发现过程监督比结果监督在数学推理任务上效果提升很明显,尤其是那些需要多步推理的复杂题目。
标注过程级的反馈成本很高。每道题不是只标一个答案,而是要对每个推理步骤都判断对错,这需要人工标注员有相当的数学素养。所以实际操作中,可能会用一些半自动的方法,比如先让模型生成多个解题路径,然后用符号验证工具或者数值检验的方式筛选出正确的步骤,再用这些数据来训练。或者用强化学习的框架,把中间步骤的正确性作为奖励信号,让模型在探索中学习。这就引出了另一个方向,就是用强化学习来做推理时的优化,像OpenAI的o1就是这个思路,给模型更多的思考时间和试错空间,通过搜索和验证来提升答案质量。
还有些研究尝试在模型架构里引入专门的符号推理模块,或者加一个验证器来检查生成的推理步骤是否符合数学规则。这些方向比较前沿,工程上还不太成熟,但思路值得关注——本质上都是在探索如何把神经网络的统计学习能力和传统AI的符号推理能力结合起来。
实战权衡与验证机制
面试官很可能会在你讲完解决方案后,突然问你:"这么多方法,实际应用该怎么选?"这是个展现你工程判断力的好机会。如果是快速验证或者资源有限的场景,优先用提示工程,成本低见效快。如果是对准确率要求很高的产品,工具增强是必选项,把计算交给可靠的外部工具。如果你有足够的数据和算力,愿意投入训练成本,那就做专门的数学数据微调,配合过程监督来提升模型的内在能力。
实际的产品往往会组合使用,比如先用数学数据微调打好基础,推理时用CoT引导生成,遇到计算再调工具,这样各取所长。关键是理解每种方法解决的是哪个层面的问题,根据具体需求来做技术选型。
更进阶的追问可能会涉及验证机制的设计。你怎么确保模型生成的推理步骤是对的?这时候不要只说"加个验证器"就完了,那太浅了。可以展开讲几个层次的验证策略。最基础的是格式验证,检查生成的内容是否符合数学表达式的语法规则,这个可以用正则或者简单的parser来做。更深一层是逻辑一致性验证,比如检查方程变换前后是否等价,这可以用符号运算库来实现,把变换前后的式子都代入几个特殊值,看结果是否一致。最高层次是多路径验证,让模型用不同的解题思路都算一遍,如果多个路径得到相同答案,置信度就高很多。还有个self-consistency的技巧,就是让模型生成多次,然后通过投票选出最常见的答案,这在数学推理任务上被证明能显著提升准确率。
如果面试官对AGI的发展路径感兴趣,可能会问你怎么看符号主义和连接主义的融合。传统AI是符号主义路线,强调显式的逻辑规则和知识表示,这在处理数学推理这种需要严格逻辑的任务时有天然优势,但泛化能力差,遇到没见过的题型就不行了。深度学习走的是连接主义路线,通过海量数据学习隐式的pattern,泛化能力很强,但缺乏可解释性和逻辑保证。现在业界的趋势是把两者结合起来,用神经网络来做感知和理解部分,把符号系统用在推理和验证环节。具体到数学推理这个场景,就是让模型理解题意、生成解题框架,然后用符号运算引擎来执行具体的代数操作,最后再用逻辑验证器检查答案。这种混合架构其实在很多领域都在探索,比如自动驾驶里用神经网络做感知,用规则引擎做决策。
如果你有相关的项目经验或者实习经历,这是个绝佳的展示机会。但千万别生硬地说"我做过类似的",那会显得你在刻意往上靠。自然的切入方式是在讲到某个具体技术点时,顺带提一句:"我之前在某个智能问答系统里遇到过类似的问题,当时我们发现模型处理数值计算经常出错,后来接入了一个计算服务,把识别出的数学表达式转成API调用,准确率从70%提到了95%,但也遇到了调用延迟的问题,最后通过异步处理和结果缓存优化了体验。"这样既展示了你的实战经验,也体现了你在真实场景下做技术选型和问题解决的能力。
理解这道题背后的考察意图很重要,面试官其实不是在考你对某个具体技术的熟悉度,而是想看你对AI能力边界的认知深度。当你能清晰地说出"大模型在数学推理上表现不好"这个判断时,说明你不是把AI当成万能黑盒,而是真的理解了当前技术的局限性在哪里。这种对技术边界的清醒认知,在实际工作中特别重要。很多工程师容易陷入"既然模型这么强,什么问题都能解决"的盲目乐观,结果做产品时踩坑。面试官通过这道题能快速判断你是否具备这种技术判断力,能不能把技术真正落地。