精炼回答
Agent的动态重规划本质上是在执行过程中检测到当前计划不可行或低效时,重新生成执行路径的自适应机制。这个机制让Agent具备了容错性和环境适应能力,避免一条路走到黑。
触发条件主要覆盖几个维度。执行层面最常见的是工具调用失败,比如API返回错误、调用超时或者权限不足。环境层面要关注状态偏离预期,Agent观察到的实际情况和计划假设不一致,比如计划查询商品库存时假设商品存在,结果发现已经下架了。资源约束也是重要的触发因素,当token预算即将耗尽或时间窗口不足时,必须调整策略才能在限制内完成任务。此外,Agent通过反思机制发现当前策略效率低下时,即使能完成任务也会主动优化路径。
重规划过程通常是这样运作的:Agent先将失败信息或新观察结果反馈给规划模块,然后基于更新后的状态重新调用LLM生成新计划。有些实现会保留部分可复用的子计划,只调整受影响的分支;有些则完全推翻重来。比如在ReAct框架中,当工具调用失败后,Agent会在下一轮Thought中分析失败原因,然后生成替代Action。在AutoGPT这类系统中,会维护一个动态的任务队列,失败任务会被重新分解或调整优先级。实际应用中,比如电商客服Agent在查询订单失败后,会切换到让用户提供更多信息的分支;代码生成Agent在编译报错时,会根据错误信息修改代码生成策略。
扩展分析
执行流程与重规划机制的深度解析
要真正理解重规划机制,得先看清楚Agent平时是怎么工作的。Agent执行任务就像导航软件规划路线,最开始会生成一个初始计划,然后边走边看实际情况。标准的执行流程是个循环——先Planning规划出几个步骤,接着Execute执行具体动作,然后Observe观察执行结果和环境反馈,最后Reflect反思当前进展是否符合预期。这个循环会一直转,直到任务完成或者明确失败。这个循环其实体现了闭环控制的思想,跟控制论里的反馈回路是一个道理。
重规划发生在Reflect阶段发现问题之后。就像你开车导航,本来规划走高速,结果Observe阶段发现前方堵车,Reflect判断按原路走肯定迟到,这时候就触发重规划——导航重新计算路线。重规划和初始规划的本质区别在于:初始规划面对的是静态的任务描述,基于假设的理想环境;而重规划拿到的是真实的执行反馈,知道哪些路走不通、哪些假设不成立。所以重规划的信息更充分,但时间压力更大,因为已经消耗了部分资源。
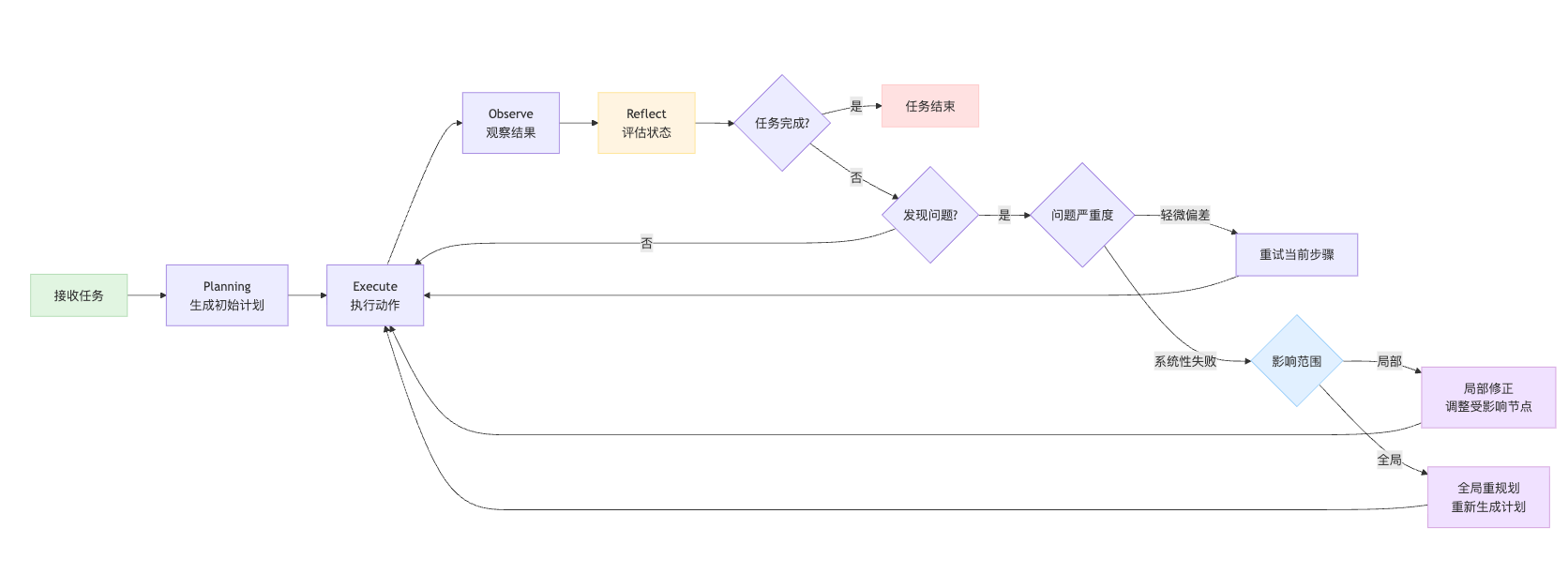
触发条件需要分层次理解,不能平铺直叙。最直接的触发信号是Action执行返回了异常,但不是所有异常都该重规划——如果只是网络抖动导致的偶发超时,Agent应该重试而不是推翻计划。真正需要重规划的是系统性失败,比如调用的API根本不存在,或者返回的错误码表明参数设计就有问题。拿电商场景来说,Agent计划先查库存再下单,结果查库存接口返回403无权限。这时候重试没用,必须重规划——要么切换到其他数据源,要么调整任务路径先去获取权限。
环境变化这类触发条件要强调"预期vs实际"的gap。Agent在Planning时会基于当前状态做假设,比如假设某个商品有货。但Observe阶段发现实际已售罄,这个状态偏差就会触发重规划。关键点是:不是环境变了就重规划,而是变化影响到了计划的可行性才需要调整。Agent通常会维护一个前置条件列表,任何前置条件失效都会触发检查。
资源约束的触发条件要跟成本意识挂钩。Agent通常有预算限制,比如最多调用10次API或者必须在30秒内完成。当Reflect发现按当前计划执行下去会超预算,就得重规划优化路径。就像你去超市购物,发现购物车里的东西快超预算了,你会重新规划——换掉贵的商品或者调整购买数量。
效率低下这个触发条件最能体现Agent的智能性。有些Agent会在执行过程中做效率评估,发现当前策略虽然能work但太慢了。比如计划用遍历方式查找数据,执行了几步发现数据量巨大,这时候会重规划改用索引查询。这类重规划通常需要配置一个效率阈值,避免为了追求极致优化而陷入不断重规划的死循环。
决策时有个关键问题:是不是一发现问题就整个计划推翻重来?这就涉及到修正和重规划的选择了。我的理解是,这取决于问题的影响范围。如果只是某个子任务失败,但不影响整体目标,那局部修正就够了——比如计划是A→B→C三步,B失败了但可以换成B',那就只调整这一步。但如果失败暴露出整个计划的前提假设错了,就得全局重规划。Agent计划帮用户订酒店,先查可用房间再预订。如果查询接口临时故障,换个接口就行,这是局部修正;但如果发现用户提供的日期是过去时间,那整个计划的逻辑都错了,必须重新理解需求。
决策时要评估已执行步骤的可复用性。有些Agent实现会维护一个执行历史,重规划时会检查哪些中间结果还有效,避免重复劳动。就像你做饭做到一半发现缺食材,不会把已经切好的菜倒掉重来,而是基于现有进度调整菜谱。
重规划不是免费的,它的成本要认真考虑。首先是时间成本,调用LLM重新生成计划通常需要几秒钟,在实时场景下可能等不起。其次是计算成本,每次重规划都要消耗token,频繁重规划会快速耗尽预算。但更隐蔽的是一致性风险。重规划可能导致Agent的行为看起来很混乱。用户看到Agent先说要做A,突然又改口做B,会觉得不靠谱。拿客服Agent举例:用户问退款进度,Agent先说帮你查订单,突然重规划改成查物流,再重规划又说要核实身份——用户肯定一脸懵。所以工程上要设计好对外交互的连贯性,重规划时给用户一个合理的解释。
平衡的方法通常是设置重规划的次数上限和冷却时间,避免震荡。同时对于不同严重程度的问题设置不同的决策阈值——轻微偏差容忍一下,严重失败才立即重规划。业界主流有三种策略,各有适用场景。局部修正策略适合问题孤立的情况,只调整失败节点及其下游依赖,保留其他部分。优点是快速、成本低,缺点是可能治标不治本,就像修bug只改出问题的那个函数,不重构整个模块。全局重规划适合前提假设崩塌的情况,完全抛弃原计划重新生成。优点是能找到更优解,缺点是成本高且浪费已有进展,就像下棋发现布局彻底错了,认输重开。混合策略是大多数生产系统的选择,先尝试局部修正,修正N次还不行才触发全局重规划,这就像医生看病,先开药保守治疗,不行再考虑手术。具体选哪种策略,要看任务的容错性要求和资源预算。实时性要求高的场景倾向局部修正,探索性任务可以多用全局重规划。
实战落地与框架实现
在实际项目中落地重规划机制,最重要的是理解它在不同场景下的价值。智能客服是最典型的应用场景,用户问"我的包裹怎么还没到",Agent最初规划是先查订单状态,再查物流信息,最后给出答复。但执行第一步时发现用户提供的订单号格式不对,这时候就得重规划——改成先引导用户提供正确的订单号,或者换个思路通过手机号查历史订单。这个场景的价值在于,重规划不仅要处理技术层面的失败,还要考虑用户体验,不能让对话断掉。
任务规划助手的场景更复杂一些。比如帮用户安排一天的行程,Agent计划了早上开会、中午聚餐、下午拜访客户这个流程,结果执行到查询餐厅预订时发现目标餐厅今天休息。这时候重规划要做的不只是换一家餐厅,还要检查新餐厅的位置会不会影响下午的拜访行程,可能需要调整整个时间线。这个例子能说明重规划的级联效应——一个环节的变化会波及到整个计划。
框架层面,LangChain的ReAct模式和AutoGPT的循环机制代表了不同的设计思路。ReAct模式的核心是把Thought、Action、Observation显式地串起来。每一轮循环中,Agent先输出Thought说明当前打算做什么,然后执行Action,最后拿到Observation结果。如果Observation显示Action失败了,下一轮Thought就会分析失败原因并生成新的Action。重规划是隐式发生的,体现在Thought的变化上——系统会把之前所有的Thought-Action-Observation历史都喂给LLM,让它自己判断要不要调整计划。这种实现的好处是灵活,LLM可以根据上下文自主决策;缺点是不够可控,你很难预测它什么时候会重规划。
AutoGPT的做法更工程化一些。它维护了一个显式的任务队列,每个任务有状态标记——待执行、执行中、已完成、失败。当某个任务失败时,系统会根据失败类型决定是重试、跳过还是分解成更小的子任务。重规划体现在对任务队列的动态调整上,比如插入新任务、调整优先级、删除不可达的任务。AutoGPT的这种设计更像是一个任务调度系统,重规划的逻辑相对透明,便于调试和优化。ReAct适合交互式任务,每一步都需要根据反馈灵活调整,比如客服对话;AutoGPT适合目标明确但路径复杂的任务,比如数据分析流程,需要完成多个相互依赖的步骤。
代码实现上,触发条件的检测主要通过几种机制。异常捕获是最直接的方式,Agent在执行每个Action时都会用try-catch包裹起来,捕获到异常后不是直接抛出,而是把异常信息封装成一个特殊的Observation返回给规划模块:
publicclassActionExecutor{
privatestaticfinalint MAX_RETRY =3;
publicObservationexecute(Action action){
int retryCount =0;
while(retryCount < MAX_RETRY){
try{
Result result = action.invoke();
returnnewSuccessObservation(result);
}catch(APIException e){
// 区分不同类型的异常
if(e.isRetryable()&& retryCount < MAX_RETRY -1){
retryCount++;
sleepWithBackoff(retryCount);
continue;
}
returnnewErrorObservation(
"API调用失败: "+ e.getMessage(),
e.getErrorCode(),
action,
false// 不可重试
);
}catch(TimeoutException e){
returnnewErrorObservation(
"执行超时,可能需要优化策略",
"TIMEOUT",
action,
true// 可通过重规划优化
);
}
}
returnnewErrorObservation("重试次数耗尽","MAX_RETRY_EXCEEDED", action,false);
}
privatevoidsleepWithBackoff(int retryCount){
try{
Thread.sleep((long)Math.pow(2, retryCount)*1000);
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
}java
关键是要把异常转换成Agent能理解的信息,而不是让整个流程崩溃。目标验证的实现通过前置条件检查来完成:
publicclassPlanValidator{
publicValidationResultvalidate(State currentState,Plan plan){
List<String> violations =newArrayList<>();
for(Step step : plan.getSteps()){
for(Condition precondition : step.getPreconditions()){
if(!precondition.isSatisfied(currentState)){
violations.add(String.format(
"步骤 %s 的前置条件 '%s' 不满足,当前状态: %s",
step.getName(),
precondition.getDescription(),
currentState.getValue(precondition.getKey())
));
}
}
}
return violations.isEmpty()
?ValidationResult.success()
:ValidationResult.failure(violations);
}
}
// 在执行循环中使用
publicclassAgentExecutor{
publicvoidexecuteWithValidation(Plan plan){
State currentState =initializeState();
for(Step step : plan.getSteps()){
ValidationResult validation = validator.validate(currentState, plan);
if(!validation.isValid()){
// 触发重规划
Plan newPlan = replanner.replan(
plan,
currentState,
validation.getViolations()
);
plan = newPlan;
}
Observation obs = executor.execute(step.getAction());
currentState = currentState.update(obs);
}
}
}java
环境监控通过资源追踪来实现,这在生产环境中非常重要:
publicclassResourceMonitor{
privatestaticfinalint TOKEN_THRESHOLD =1000;
privatestaticfinallong TIME_THRESHOLD_MS =25000;// 留5秒缓冲
privateint usedTokens =0;
privatelong startTime;
privateint maxTokens;
privatelong maxTimeMs;
publicResourceMonitor(int maxTokens,long maxTimeMs){
this.maxTokens = maxTokens;
this.maxTimeMs = maxTimeMs;
this.startTime =System.currentTimeMillis();
}
publicvoidrecordTokenUsage(int tokens){
this.usedTokens += tokens;
}
publicReplanTriggercheckResources(Plan remainingPlan){
int remainingTokens = maxTokens - usedTokens;
long remainingTime = maxTimeMs -(System.currentTimeMillis()- startTime);
// 估算剩余计划的资源需求
int estimatedTokens =estimateTokenCost(remainingPlan);
long estimatedTime =estimateTimeCost(remainingPlan);
if(remainingTokens < estimatedTokens + TOKEN_THRESHOLD){
returnReplanTrigger.tokenBudgetInsufficient(
remainingTokens, estimatedTokens
);
}
if(remainingTime < estimatedTime + TIME_THRESHOLD_MS){
returnReplanTrigger.timeInsufficient(
remainingTime, estimatedTime
);
}
returnReplanTrigger.none();
}
privateintestimateTokenCost(Plan plan){
// 基于历史数据或启发式估算
return plan.getSteps().size()*200;// 简化估算
}
privatelongestimateTimeCost(Plan plan){
return plan.getSteps().size()*2000L;// 假设每步2秒
}
}java
重规划算法的实现分为基于规则和基于LLM两种。基于规则的重规划适合决策逻辑比较固定的场景:
publicclassRuleBasedReplanner{
publicPlanreplan(Plan originalPlan,ErrorObservation error,State currentState){
String errorCode = error.getErrorCode();
// 根据错误类型选择策略
if("PERMISSION_DENIED".equals(errorCode)){
returninsertAuthenticationStep(originalPlan, error.getFailedAction());
}
if("NOT_FOUND".equals(errorCode)){
returnswitchToAlternativeDataSource(originalPlan, currentState);
}
if("TIMEOUT".equals(errorCode)){
returnoptimizeForSpeed(originalPlan);
}
if("RATE_LIMIT".equals(errorCode)){
returninsertDelayAndRetry(originalPlan, error.getFailedAction());
}
// 未知错误,使用通用回退策略
returngenerateFallbackPlan(originalPlan.getGoal(), currentState);
}
privatePlaninsertAuthenticationStep(Plan plan,Action failedAction){
// 在失败步骤前插入认证步骤
List<Step> newSteps =newArrayList<>();
boolean inserted =false;
for(Step step : plan.getSteps()){
if(!inserted && step.getAction().equals(failedAction)){
newSteps.add(newStep("authenticate",newAuthAction()));
inserted =true;
}
newSteps.add(step);
}
returnnewPlan(plan.getGoal(), newSteps);
}
privatePlanoptimizeForSpeed(Plan plan){
// 将串行步骤改为并行,或使用更快的替代方案
List<Step> optimizedSteps = plan.getSteps().stream()
.map(this::findFasterAlternative)
.collect(Collectors.toList());
returnnewPlan(plan.getGoal(), optimizedSteps);
}
}java
基于LLM的重规划更灵活,但需要精心设计prompt:
publicclassLLMReplanner{
privateLLMClient llmClient;
publicPlanreplan(Plan originalPlan,List<Step> executedSteps,
ErrorObservation error,State currentState){
String replanPrompt =buildReplanPrompt(
originalPlan, executedSteps, error, currentState
);
String response = llmClient.generate(replanPrompt);
returnparsePlanFromResponse(response);
}
privateStringbuildReplanPrompt(Plan originalPlan,List<Step> executedSteps,
ErrorObservation error,State currentState){
StringBuilder prompt =newStringBuilder();
prompt.append("你是一个任务规划助手。当前任务遇到了问题,需要重新规划。\n\n");
prompt.append("**原始目标**: ").append(originalPlan.getGoal()).append("\n\n");
prompt.append("**原计划**:\n");
for(int i =0; i < originalPlan.getSteps().size(); i++){
Step step = originalPlan.getSteps().get(i);
prompt.append(String.format("%d. %s\n", i +1, step.getDescription()));
}
prompt.append("\n**已成功执行的步骤**:\n");
for(int i =0; i < executedSteps.size(); i++){
Step step = executedSteps.get(i);
prompt.append(String.format("%d. %s ✓\n", i +1, step.getDescription()));
}
prompt.append("\n**失败信息**: ").append(error.getMessage()).append("\n");
prompt.append("**错误类型**: ").append(error.getErrorCode()).append("\n\n");
prompt.append("**当前状态**:\n");
prompt.append(currentState.toReadableString()).append("\n\n");
prompt.append("**要求**:\n");
prompt.append("1. 保留已成功执行步骤的结果,不要重复执行\n");
prompt.append("2. 分析失败原因,避免重蹈覆辙\n");
prompt.append("3. 生成新的执行计划,确保能达成原始目标\n");
prompt.append("4. 如果原目标不可达,说明原因并调整为可行目标\n\n");
prompt.append("请以JSON格式输出新计划:\n");
prompt.append("{\n");
prompt.append(" \"analysis\": \"失败原因分析\",\n");
prompt.append(" \"strategy\": \"调整策略说明\",\n");
prompt.append(" \"steps\": [\n");
prompt.append(" {\"action\": \"动作类型\", \"params\": {...}, \"description\": \"步骤说明\"}\n");
prompt.append(" ]\n");
prompt.append("}");
return prompt.toString();
}
}java
生产实践中,最重要的是设置好保护机制。设置重规划次数上限是最基本的:
publicclassSafeReplanner{
privatestaticfinalint MAX_REPLAN_COUNT =3;
privatestaticfinallong REPLAN_COOLDOWN_MS =5000;
privateint replanCount =0;
privatelong lastReplanTime =0;
privateSet<String> triedStrategies =newHashSet<>();
publicOptional<Plan>replan(Plan currentPlan,ErrorObservation error,
State currentState){
// 检查重规划次数限制
if(replanCount >= MAX_REPLAN_COUNT){
log.error("达到最大重规划次数,任务失败");
returnOptional.empty();
}
// 检查冷却时间
long now =System.currentTimeMillis();
if(now - lastReplanTime < REPLAN_COOLDOWN_MS){
log.warn("重规划过于频繁,等待冷却");
returnOptional.empty();
}
// 生成新计划
Plan newPlan =generateNewPlan(currentPlan, error, currentState);
// 检查是否重复尝试相同策略
String strategySignature =computeStrategySignature(newPlan);
if(triedStrategies.contains(strategySignature)){
log.warn("检测到重复策略,避免死循环");
returnOptional.empty();
}
// 记录并返回
replanCount++;
lastReplanTime = now;
triedStrategies.add(strategySignature);
log.info("第{}次重规划完成,新计划包含{}个步骤",
replanCount, newPlan.getSteps().size());
returnOptional.of(newPlan);
}
privateStringcomputeStrategySignature(Plan plan){
// 计算计划的特征签名,用于检测重复策略
return plan.getSteps().stream()
.map(step -> step.getAction().getClass().getSimpleName())
.collect(Collectors.joining("->"));
}
}java
记录规划历史对于后续优化非常重要:
publicclassReplanningHistory{
privateList<ReplanRecord> records =newArrayList<>();
publicvoidrecordReplan(Plan oldPlan,Plan newPlan,
ErrorObservation trigger,State state){
ReplanRecordrecord=newReplanRecord(
System.currentTimeMillis(),
oldPlan,
newPlan,
trigger,
state
);
records.add(record);
}
publicvoidanalyzePatterns(){
// 分析重规划模式
Map<String,Long> errorFrequency = records.stream()
.collect(Collectors.groupingBy(
r -> r.getTrigger().getErrorCode(),
Collectors.counting()
));
log.info("重规划触发统计: {}", errorFrequency);
// 识别频繁失败的操作
Map<String,Long> failedActions = records.stream()
.map(r -> r.getTrigger().getFailedAction().getClass().getSimpleName())
.collect(Collectors.groupingBy(a -> a,Collectors.counting()));
log.info("频繁失败的操作: {}", failedActions);
}
}java
常见问题的处理经验值得分享。死循环规划通过策略去重和黑名单机制来避免,过度重规划通过触发阈值来控制,规划抖动通过冷却期来缓解。这些机制组合起来,就能构建一个既灵活又稳定的重规划系统。
架构思考与工程权衡
重规划机制的深层意义在于,它不是孤立的功能模块,而是牵扯到整个Agent系统的异常处理、容错设计、资源管理这些工程上的核心问题。怎么避免重规划的死循环,表面上看是设个计数器限制次数,但深层的问题是Agent在状态空间里反复震荡,说明它的决策依据不够稳定。所以除了次数限制这种硬约束,更重要的是引入状态记忆机制——记住哪些策略已经尝试过并且失败了,重规划时主动避开。这就像人走迷宫,你不会在两个岔路口之间来回走,因为你会记住哪条路已经证明走不通。
性能开销的优化也需要系统性思考。重规划的代价不只是调用一次LLM那么简单,它会打断整个执行流程,已经做的中间计算可能要重来,这些隐性成本往往更大。优化的思路可以从两个方向展开:减少触发频率,通过更精准的前置检查和更鲁棒的初始规划来降低失败概率;加快重规划速度,比如预生成几个备选方案,失败时直接切换而不是现场重新生成。流程编排系统在某个节点失败时,如果每次都要重新编译整个DAG图,性能肯定扛不住,所以通常会维护局部的修复策略。
即使没做过Agent项目,你也能把这个问题映射到自己熟悉的领域。任务调度系统里的任务重分配、分布式系统的故障转移、甚至游戏AI的策略切换,本质上都是在运行时根据反馈调整计划。某个Worker节点挂了,调度器要把它上面的任务重新分配给其他节点,这时候就要考虑任务之间的依赖关系、资源约束、公平性等因素,这跟Agent重规划的逻辑是相通的。
从架构层面看,重规划其实是可靠性和灵活性之间的权衡点。一个Agent如果完全不重规划,遇到问题就直接失败,虽然行为可预测但适应性差;如果重规划太频繁,系统的行为就会飘忽不定,用户体验很糟糕。设计重规划机制就像给系统装弹簧,太硬了震不掉冲击,太软了系统自己都站不稳。你要根据具体场景找到合适的刚度——金融交易类的Agent倾向于保守,宁愿失败也不要乱改计划;探索性的研究助手可以激进一些,多试错才能找到新路径。
人机协作的边界也是个重要话题。不是所有问题都该让Agent自己重规划解决,有些时候人工介入反而更高效。判断标准主要看两个维度:问题的复杂度和决策的风险。如果Agent连续重规划三次还没找到可行路径,说明问题超出了它的能力范围,这时候应该升级给人类处理而不是继续消耗资源。风险方面,涉及到敏感操作比如资金转账、数据删除,重规划前最好有人类审批环节。这个思考体现出对生产系统的责任意识,不是为了技术而技术。
前沿技术方向上,强化学习里的在线策略调整跟重规划有异曲同工之处——都是基于反馈动态调整行为。区别在于RL是通过奖励信号缓慢迭代参数,而LLM驱动的重规划是直接生成新的符号化计划。未来这两个方向可能会融合,比如用RL来学习什么时候该触发重规划、选择哪种重规划策略,而不是完全依赖人工设定的规则。这种前瞻性的思考说明你不只是会用现成的工具,还在关注技术演进的方向。