精炼回答
使用LangChain构建多轮对话系统的核心在于对话记忆管理和上下文维护。你需要通过ConversationChain配合合适的Memory组件来实现对话状态的持续跟踪。
最基础的实现是使用ConversationBufferMemory,它会保存完整的对话历史。当你需要控制上下文长度时,可以选择ConversationBufferWindowMemory来限制保留的轮次,或者使用ConversationSummaryMemory对历史对话进行摘要压缩。对于更复杂的场景,ConversationSummaryBufferMemory能够结合摘要和缓冲机制。
在实际应用中,比如客服系统,你可以通过ConversationChain.from_llm()初始化对话链,然后在每次用户输入时调用predict()方法,LangChain会自动将历史对话作为prompt的一部分传递给大语言模型。关键是要正确配置memory的**memory_key**和**input_key**参数,确保对话历史能够正确注入到prompt模板中。
如果你需要更精细的控制,可以自定义ConversationChain的prompt模板,明确指定对话历史的格式和位置。对于需要持久化的场景,可以将Memory组件与数据库结合,实现跨会话的对话状态保存。整个过程中,LangChain会透明地处理对话历史的序列化和反序列化工作。
扩展分析
深入分析
多轮对话系统本质上是一个有状态的智能交互系统,需要在多次用户交互中保持上下文连贯性,LangChain通过其Memory机制和Chain抽象很好地解决了这个问题。要构建一个真正有效的多轮对话系统,你需要从系统架构的高度来思考整个问题。
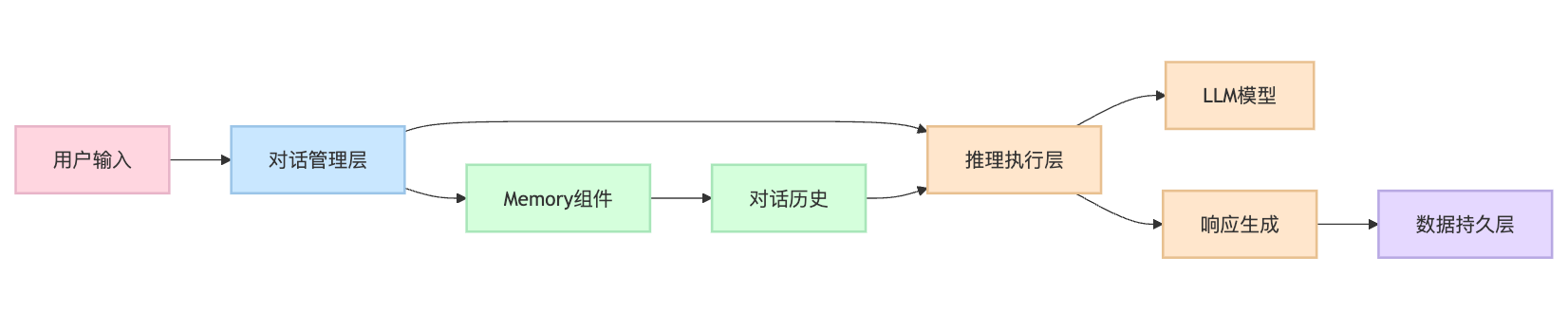
从架构设计角度来看,我推荐采用三层架构:对话管理层负责会话状态维护,推理执行层处理具体的AI推理任务,而数据持久层确保对话历史的可靠存储。这种分层设计让系统具备了良好的扩展性和维护性。
LangChain本质上是将AI应用开发中的常见模式进行了抽象和封装,其中Chain代表了一种可组合的计算管道,而Memory则是状态管理的抽象。这种抽象的真正价值不在于提供了多少API,而在于它将复杂的AI应用构建过程标准化了。每个组件都有明确的职责边界,Chain负责调用逻辑,Memory负责状态管理,Prompt负责输入格式化,这种职责分离的设计让系统更容易维护和扩展。
// 框架的抽象设计体现在组件的可插拔性
ConversationChain chain =ConversationChain.builder()
.llm(openAIModel)// 可以替换为任意LLM
.memory(bufferMemory)// 可以替换为不同的Memory策略
.prompt(customTemplate)// 可以自定义Prompt格式
.build();会话状态管理是整个系统的核心挑战。在无状态的HTTP请求中维护有状态的对话,需要系统在每次用户发送消息时,将当前输入与历史上下文合并,形成完整的prompt发送给大语言模型。拿电商客服场景举例,用户可能先问"这个商品有现货吗",然后问"什么时候能发货",第二个问题中的"这个商品"需要从前一轮对话中获取上下文才能理解。
Memory组件内部维护着一个对话历史的数据结构,每次新的交互都会触发两个操作:读取历史生成当前prompt,以及将新的交互结果写入历史记录。这种读写分离的设计让系统具备了很好的扩展性,你可以很容易地将Memory的存储后端从内存切换到Redis或数据库。
publicclassConversationBufferMemoryimplementsBaseMemory{
privateList<ChatMessage> chatMessages =newArrayList<>();
publicvoidsaveContext(Map<String,Object> inputs,Map<String,Object> outputs){
chatMessages.add(newHumanMessage((String) inputs.get("input")));
chatMessages.add(newAIMessage((String) outputs.get("response")));
}
publicMap<String,Object>loadMemoryVariables(){
returnMap.of("history",formatMessages(chatMessages));
}
}
Memory组件的选择策略体现了工程思维。BufferMemory虽然实现简单,但在长对话场景下会导致prompt过长,影响推理效率并增加成本。WindowMemory通过限制历史轮数解决了长度问题,但可能丢失重要的早期上下文。SummaryMemory通过AI摘要压缩历史,在保持上下文的同时控制了长度,但引入了额外的推理成本和潜在的信息损失。选择Memory策略需要在上下文完整性、推理成本和系统性能之间找平衡点。
实践应用
在实际开发中,展示代码实现能力需要体现分层设计思想。构建一个会话管理器作为核心控制器,配置合适的存储后端和异常处理机制,这样的设计体现了系统性思维。核心实现通常包含会话初始化、消息处理和状态持久化三个主要环节。
@Service
publicclassConversationService{
privatefinalMap<String,ConversationChain> activeChains =newConcurrentHashMap<>();
privatefinalConversationRepository repository;
publicStringprocessMessage(String sessionId,String userInput){
ConversationChain chain =getOrCreateChain(sessionId);
try{
return chain.predict(userInput);
}catch(Exception e){
handleConversationError(sessionId, e);
return"抱歉,系统暂时无法处理您的请求,请稍后重试";
}
}
privateConversationChaingetOrCreateChain(String sessionId){
return activeChains.computeIfAbsent(sessionId, id ->{
returnConversationChain.builder()
.llm(chatModel)
.memory(newRedisConversationMemory(id))
.build();
});
}
}
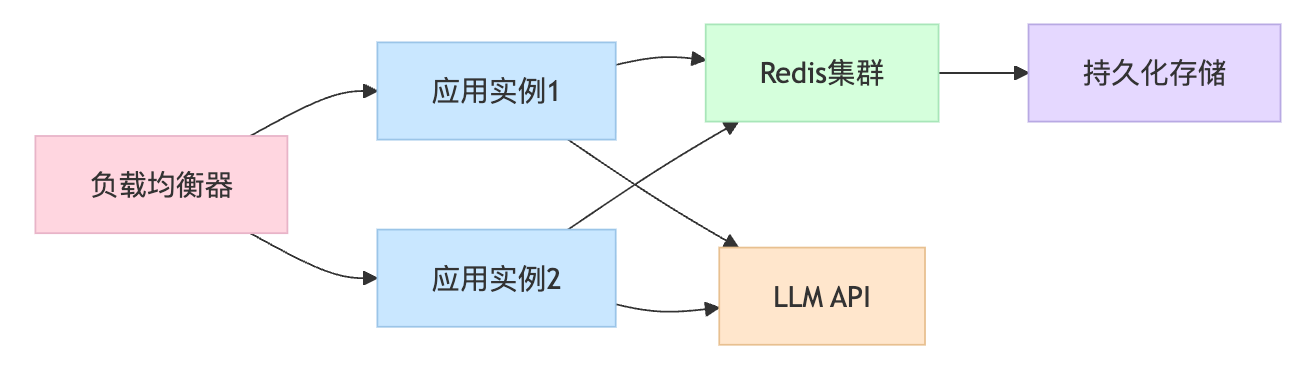
生产环境中内存存储显然不够用,需要设计一个持久化的Memory实现,将会话状态保存到Redis或数据库中。设计考量的关键在于:Redis适合频繁读写的热数据,数据库适合需要复杂查询的冷数据。
publicclassRedisConversationMemoryimplementsBaseMemory{
privatefinalRedisTemplate<String,Object> redisTemplate;
privatefinalString sessionId;
@Override
publicvoidsaveContext(Map<String,Object> inputs,Map<String,Object> outputs){
ConversationHistory history =loadHistory();
history.addMessage(newUserMessage((String) inputs.get("input")));
history.addMessage(newAssistantMessage((String) outputs.get("response")));
redisTemplate.opsForValue().set(
"conversation:"+ sessionId,
history,
Duration.ofHours(24)
);
}
@Override
publicMap<String,Object>loadMemoryVariables(){
ConversationHistory history =loadHistory();
returnMap.of("history",formatHistory(history));
}
}
多轮对话本质上是一个状态机,每次交互都可能触发状态转换。拿电商客服举例,用户可能从商品咨询切换到订单查询,再转向售后服务,系统需要能够识别这些意图转换并相应调整对话策略。
publicclassConversationFlowController{
publicConversationStatedetermineNextState(String currentState,String userInput){
if(containsOrderKeywords(userInput)){
returnConversationState.ORDER_INQUIRY;
}elseif(containsProductKeywords(userInput)){
returnConversationState.PRODUCT_CONSULTATION;
}
returnConversationState.GENERAL_CHAT;
}
}
性能优化主要从三个维度考虑:减少模型调用延迟、优化上下文管理成本、提升并发处理能力。具体措施包括连接池管理、异步处理、缓存策略等。在实际部署时,需要考虑模型API的稳定性、会话数据的安全性和系统的可扩展性,包括API密钥管理、会话数据加密、负载均衡配置等关键点。
扩展思考
在AI系统中,异常不仅包括技术异常,还包括模型理解错误和用户意图模糊等情况。需要设计多层次的容错机制:网络异常时切换备用模型,理解错误时启动澄清对话,系统过载时启用限流保护。这种全面性的考虑体现了处理生产系统的成熟度。
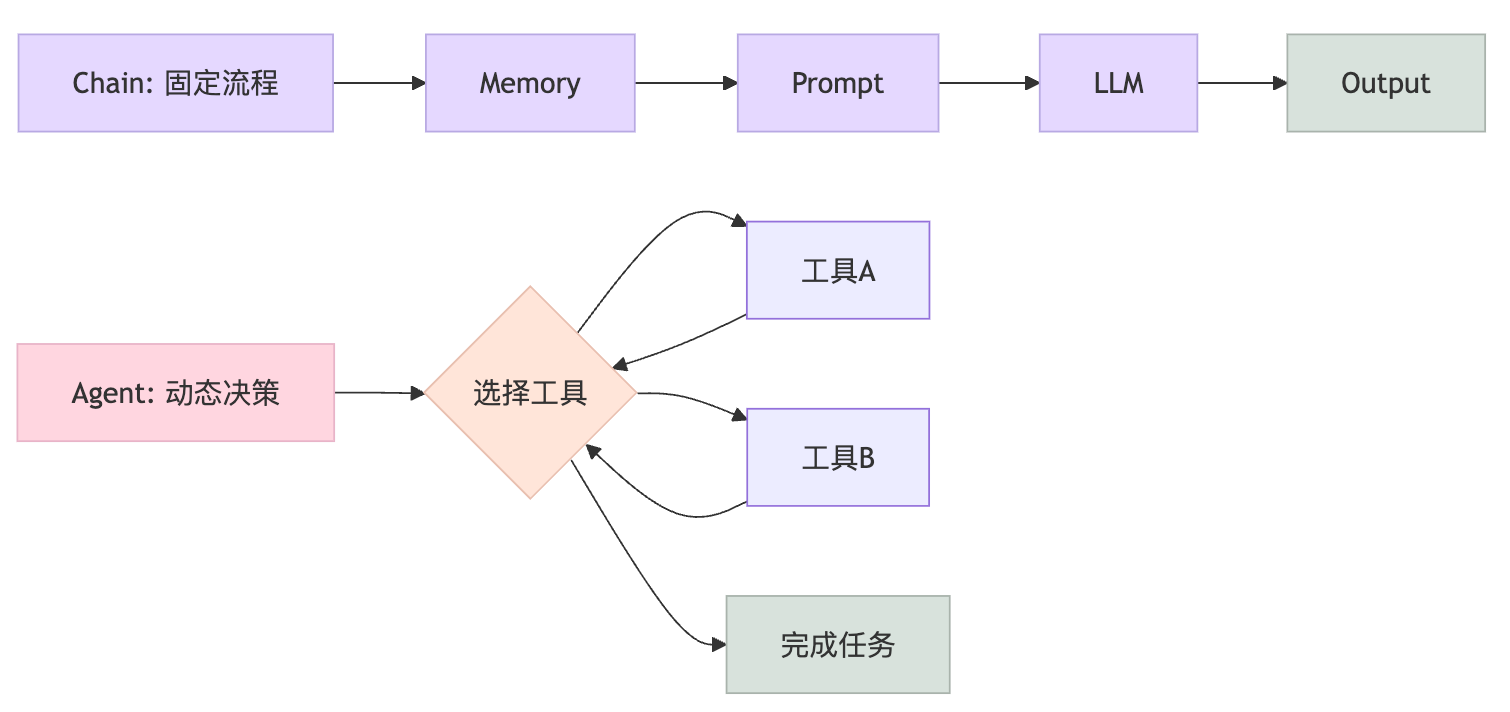
从技术发展的角度来看,Chain和Agent代表了不同的设计理念。Chain是预定义的执行路径,像一条固定的流水线,每个步骤的执行顺序是确定的。而Agent具备动态决策能力,它会根据当前输入和可用工具来规划执行路径。ConversationChain属于Chain类型,它的执行流程是固定的:读取Memory-格式化Prompt-调用LLM-保存结果。
在选择技术方案时,要根据业务场景的实时性要求来决定。客服场景通常需要实时响应,适合同步处理;而内容生成场景可以容忍一定延迟,适合异步处理以提升系统吞吐量。监控策略应该设置对话质量监控、API调用监控和用户体验监控三个维度的指标,包括响应时间、成功率、用户满意度等关键指标。
LangChain的真正价值在于它将AI应用开发从面向API的编程转变为面向组件的编程。开发者不再需要手动拼接prompt、处理API调用、管理对话状态,而是专注于业务逻辑的实现。这种抽象层次的提升让AI应用开发变得更加工程化和可维护,也为后续的功能扩展和系统优化奠定了良好的基础。
当面对系统可扩展性挑战时,比如用户同时发起大量会话的情况,需要从资源隔离、优雅降级和成本控制三个角度来分析。通过合理的架构设计和技术选型,可以构建出既能满足业务需求又具备良好扩展性的多轮对话系统。