精炼回答
技术债务的检测主要依靠静态代码分析工具和代码审查的组合。常用的工具像 SonarQube 会通过分析代码复杂度、重复率、测试覆盖率等指标来计算技术债务比率,给出量化的评估结果。你也可以在 CI/CD 流程中配置 ESLint、Checkstyle 这类工具,设置质量门禁来阻止债务累积。关键是要建立自动化检测机制,让问题在合并代码前就被发现。
代码坏味道本质上是那些让代码难以维护的结构性问题。重复代码是最常见的坏味道,同一段逻辑在多处出现会让后续修改变成噩梦。过长函数也很典型,比如一个处理订单的方法写了 300 行,包含验证、计算、通知等所有逻辑,读起来就像迷宫。过长参数列表同样糟糕,当方法需要传七八个参数时就该考虑封装对象了。还有发散式变化,指一个类因为多种原因需要修改,比如 User 类既处理权限又处理账单。相反的是霰弹式修改,改一个功能要同时修改十几个类。依恋情结则是指一个方法频繁访问另一个类的数据,说明职责放错了地方。这些坏味道本质都在告诉你:当前的代码组织方式正在增加理解和修改的成本。
扩展分析
技术债务不等于烂代码,这是很多人的认知误区。它更像金融债务,是团队在面对交付压力时主动选择的策略——用短期的代码质量妥协换取快速上线的收益。关键在于你是否有还债意识。比如活动大促前临时加个硬编码的优惠规则,团队心里清楚这是笔债,等大促结束就该重构成策略模式,这就是合理的债务管理。但如果直接把硬编码当正常写法持续使用,那就不是债务而是灾难了。
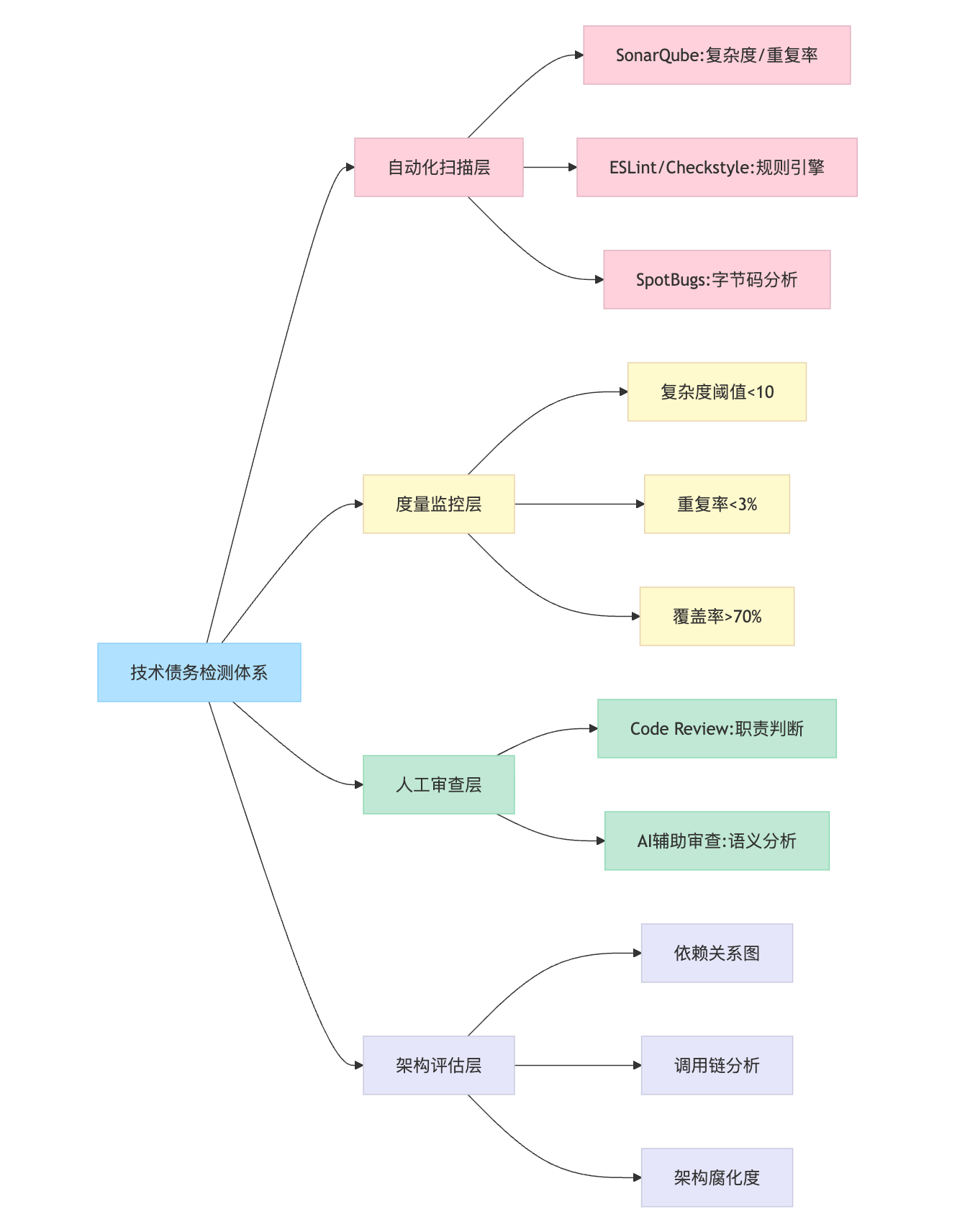
检测技术债务需要构建多层防御体系。第一层是静态分析工具的自动化扫描。SonarQube 这类平台本质上是把代码当数据来分析,通过抽象语法树计算复杂度和重复率这些结构性指标。它会给每个问题打分并累加成技术债务时间成本,比如显示修复某个类需要 4 小时,这个量化很关键,能让债务从抽象感知变成可排期的任务。PMD 基于规则引擎做模式匹配,SpotBugs 侧重字节码分析找潜在 bug,不同工具的侧重点要根据技术栈来选择。
第二层是度量指标的阈值监控。这里要设定具体的数字标准,比如圈复杂度超过 10 就要拆分方法,代码重复率高于 3% 就启动去重任务,单元测试覆盖率低于 70% 不允许上线。这些阈值不是拍脑袋定的,而是根据团队历史数据和行业基准逐步校准的。一开始可能圈复杂度阈值设成 15,团队适应后再收紧到 10,这种渐进式调整比一刀切更实际。
第三层是 Code Review 的人工审查,这是工具无法替代的环节。工具能检测到一个方法有 50 行,但判断不了这 50 行是纯计算逻辑还是混杂了 IO 操作和业务判断。这种职责混乱只有人能识别。现在有些团队在用大模型辅助 Code Review,让 AI 先过一遍语义层面的问题,人再聚焦架构决策,这能节省不少人力但准确率还需要权衡。
第四层是架构评估的定期体检。前面三层都是战术级检测,但技术债务也会累积成架构问题。比如微服务拆分不合理导致调用链过长,或者数据库设计冗余导致迁移困难,这需要季度性的架构 Review,用 C4 模型或者依赖图来可视化系统复杂度。
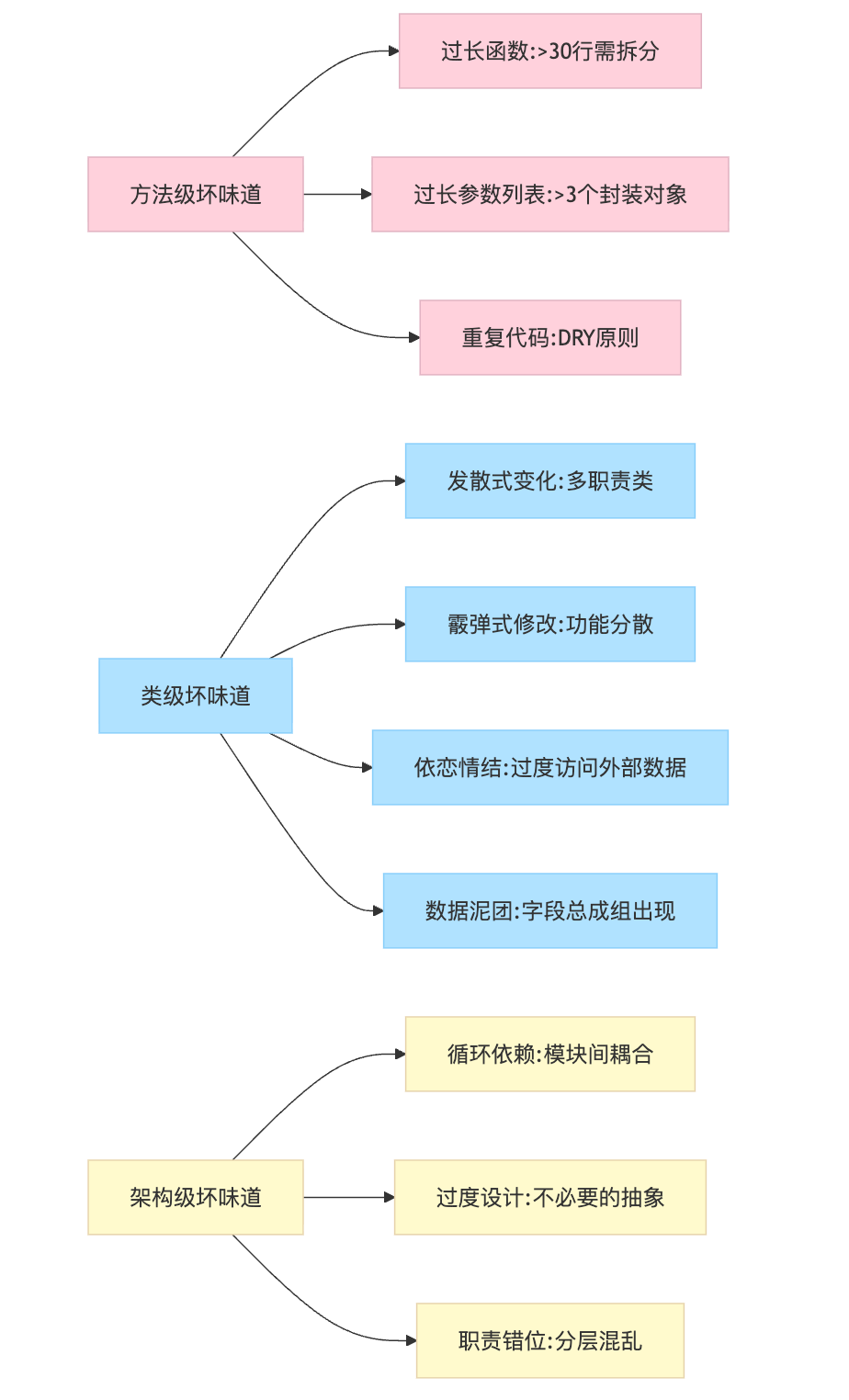
说到代码坏味道,最聪明的记忆方式是按影响半径分类。方法级的坏味道影响可读性,类级的坏味道影响可维护性,架构级的坏味道影响可扩展性。过长函数是方法级问题的重灾区,识别特征很直观:一屏放不下通常超过 30 行,或者需要用注释分段说明逻辑。比如支付处理方法里既校验参数、又查库、又计算金额、最后还发通知,读代码的人根本抓不住主线。这时候应该按职责拆成 validatePayment、calculateAmount、executePayment 几个小方法,让主流程一目了然。
// 坏味道:过长函数把所有逻辑堆在一起
publicvoidprocessPayment(Order order){
// 50行参数校验
if(order ==null|| order.getAmount()<=0){
thrownewIllegalArgumentException("Invalid order");
}
// 验证用户余额、优惠券等更多逻辑...
// 30行优惠计算
double discount =0;
if(order.getCoupon()!=null){
// 复杂的优惠规则判断...
}
// 40行支付调用和异常处理
try{
paymentGateway.charge(order.getAmount()- discount);
// 更新订单状态、发送通知...
}catch(Exception e){
// 复杂的错误处理...
}
}
// 重构后:职责清晰易于理解和测试
publicvoidprocessPayment(Order order){
validateOrder(order);
Money finalAmount =calculateFinalAmount(order);
executePayment(order, finalAmount);
notifyPaymentResult(order);
}
过长参数列表也很典型,超过 3 个参数就该警惕了。当一个方法需要传 userId、userName、userAge、userAddress 四五个参数时,说明这些参数本该封装成 User 对象。参数列表长不仅调用麻烦,更可怕的是参数顺序错了编译器也查不出来,这种隐性风险在重构时会埋下大量 bug。
类级问题更考验设计能力。发散式变化和霰弹式修改是一对反义词,对比着说印象深刻。发散式变化是指一个类承担了太多职责,修改不同需求都要改这个类。如果 UserService 里既有登录逻辑、又有积分计算、还有权限校验,那加个新的登录方式、改积分规则、调整权限策略都要动这个类,它就成了修改热点。霰弹式修改相反,是一个功能散落在多个类里,比如给系统加个多语言功能,发现十几个类都硬编码了中文字符串,要改就得霰弹枪式地扫射一遍,这时候应该抽取 ResourceBundle 统一管理。
依恋情结这个比喻很形象,当一个方法频繁调用另一个类的 getter 获取数据再计算时,就像恋爱中的人老惦记对方的事儿:
// 坏味道:OrderService 频繁访问 Customer 的数据
publicclassOrderService{
publicdoublecalculateDiscount(Order order,Customer customer){
if(customer.getLevel()== VIP && customer.getPoints()>1000){
return order.getAmount()*0.8;
}
return order.getAmount();
}
}
// 重构后:让 Customer 自己负责折扣计算
publicclassCustomer{
publicdoublegetDiscountRate(){
if(this.level == VIP &&this.points >1000){
return0.8;
}
return1.0;
}
}
publicclassOrderService{
publicdoublecalculateDiscount(Order order,Customer customer){
return order.getAmount()* customer.getDiscountRate();
}
}
数据泥团指的是总有几个字段打包出现。比如代码里到处都是 startDate、endDate、timezone 这三个参数一起传,那就该定义个 TimeRange 对象把它们封装起来。这不仅减少参数数量,还能在 TimeRange 里加上重叠判断、时长计算这些行为,让数据和行为内聚在一起。
架构级问题在面试中提到能加分,因为它显示你的思考层次。循环依赖是个经典问题:如果订单模块依赖库存模块,库存模块又依赖订单模块查预占信息,这种循环会让系统很难拆分和测试。解决方法可以用依赖倒置原则,或者抽取共同依赖的领域事件来解耦。
实践落地
从零搭建检测机制要分阶段推进。第一阶段是建立基线,上手一个新项目先跑一遍 SonarQube 扫描生成债务报告。重点不是立刻修复所有问题,而是设定一个可接受的阈值。比如发现当前债务比率是 15%,那就先定个目标:新代码不新增债务,存量债务每个迭代降低 1 个百分点。这种渐进式策略比一刀切更实际,也能避免团队抵触情绪。
第二阶段是把检测嵌入日常流程。在 GitLab CI 或 Jenkins 里配置质量门禁,设置几个硬指标:单元测试覆盖率必须达到 70%,新增代码的圈复杂度不能超过 10,代码重复率不能高于 3%。这些门禁在 merge request 阶段自动触发,不通过就无法合并到主分支。关键是要区分新老代码,存量代码可以暂时豁免,只对最近 30 天的改动做严格检查,用 SonarQube 的 New Code Period 功能就能实现。
配置流水线时要注意三道检查的顺序。第一道是静态扫描,在编译后立刻触发 SonarScanner,扫描结果自动推送到 SonarQube 服务器。很多团队把扫描放在 pipeline 末尾,导致跑完所有测试才发现代码质量不过关,浪费了十几分钟。更好的做法是把静态扫描前置到编译后的第一步,快速失败能节省大量时间。第二道是增量检查配置,SonarQube 默认是全量扫描,但对于大型项目这会拖慢流水线。配合 SCM 插件只扫描当前分支相对于主分支的变更部分,设置 sonar.pullrequest.branch 参数,一次扫描从 5 分钟缩短到 30 秒。第三道是质量门禁的精细化配置,不要用 SonarQube 内置的 Sonar Way 规则,那个标准太宽松。创建自定义 Quality Gate,针对不同模块设置不同阈值,比如核心支付服务的代码覆盖率要求 85%,而管理后台允许降到 60%。
第三阶段是建立可视化看板。把债务数据同步到 Jira 看板上,新增一个"技术债务"泳道,每个债务项都转化成可量化的任务卡片,标注修复工时。这样站会和迭代回顾时,债务就跟业务需求同等可见。如果用过 CodeScene 这类工具,能生成代码老化热力图,直观显示哪些模块又复杂又频繁改动,这种可视化比冰冷的数字更有说服力。
债务优先级排序要用"影响范围×修改频率"这个二维矩阵模型。横轴是影响范围从单个方法到整个模块,纵轴是修改频率从一年改一次到每周都改。落在右上角的债务最该优先处理——既影响广泛又经常改动。假设有个工具类的方法写得很乱,但它被 50 个地方调用,而且每次加新功能都要改它,这种债务不还就是定时炸弹。相反,一个三年没人碰的老模块,就算写得再烂也可以暂时忽略。除了技术维度,也要考虑重构成本。比如一个模块债务很高,但重构需要两周而且有回归风险,这时候可能不如先处理几个小时就能修完的低垂果实。
重构时机可以用红绿灯模型来判断。绿灯情况是小范围重构,比如方法内部逻辑优化、变量重命名,遵循童子军规则随时做——离开时让代码比来时更干净。在修 bug 或加功能时,顺手把周边代码调整一下,比如把三个 if-else 改成策略模式,这种改动风险小收益明显。黄灯情况是中等规模重构,涉及多个类或模块的调整,通常选在功能迭代的间隙,比如版本发布后的缓冲期或大促结束的维护窗口。这个阶段业务压力小,有充足时间写测试、做 Code Review。把重构包装成技术故事,明确标注节省的未来成本,比如"重构订单状态机可以减少 30% 的 if-else 分支,预计每次改动能节省 2 小时调试时间",用数据说话比讲情怀有效。红灯情况是大规模架构调整,比如微服务拆分、数据库分库分表,这种重构往往伴随业务架构升级需要专项立项,分多个阶段渐进实施而不是推倒重来。
Code Review 时准备一份动态检查清单会更高效。第一层是工具能抓到的问题,比如代码格式、命名规范,通过 Checkstyle 或 ESLint 自动化检查,Code Review 时不用浪费时间。第二层是代码坏味道的模式识别,要求审查者重点看五个维度——方法是否过长、参数是否过多、职责是否单一、依赖是否合理、命名是否清晰。每个维度给出具体判断标准,比如方法超过 30 行就要追问能否拆分。第三层是架构视角的全局审查,除了看单个类的质量,还要看新增代码对整体架构的影响。这次改动是不是引入了循环依赖?是不是让某个模块的职责更模糊了?这些问题需要有架构意识的 senior 来审查。
债务偿还通常采用"80/20"原则——每个迭代 80% 精力做业务需求,20% 处理技术债务。比如两周一个迭代,预留 2 天的 Buffer Time 专门还债,这段时间不安排新功能,团队可以自由选择最困扰他们的债务项来处理。用看板跟踪债务存量的变化趋势,每个 Sprint 结束时对比债务比率,如果连续三个迭代都在上升,说明还债速度跟不上欠债速度,这时候要拉响警报,跟产品团队重新协商需求节奏。遇到大促前的紧急需求可能会连续几个迭代不还债,那就要在大促后安排专门的重构周来集中清理,这种弹性策略比死守规则更实际。
技术债务管理最怕的是一阵风,领导重视时拼命还债,过一阵又放松了。真正有效的是把质量检查嵌入基础设施,让它成为开发流程的默认环节而不是额外负担。MVP 阶段可以放松质量要求允许快速试错,但一旦产品验证成功进入规模化阶段,就要收紧门禁建立自动化检测机制。成熟产品的维护期,重点转向架构债务的清理,为下一代技术演进做准备。