精炼回答
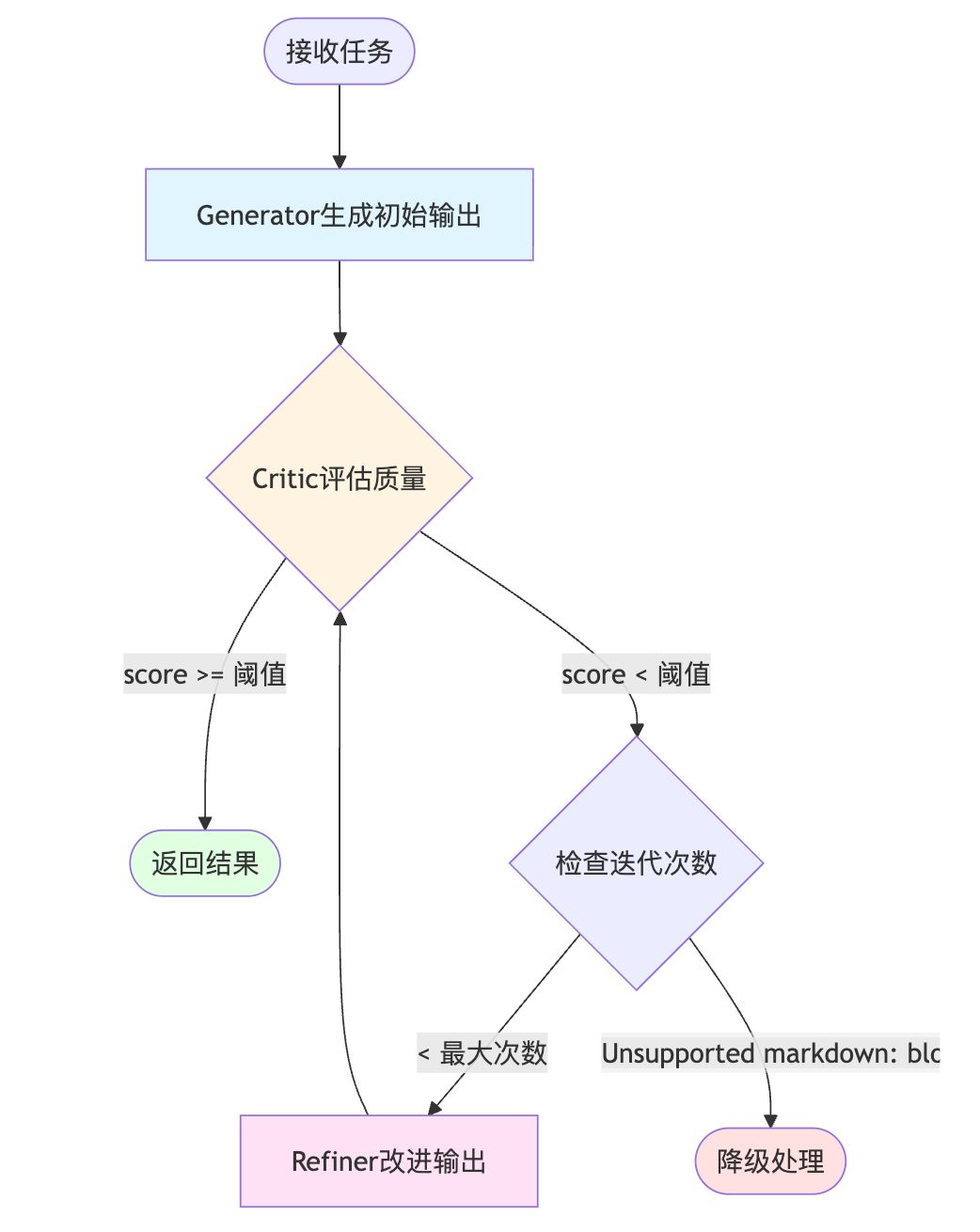
Agent的Self-Refinement本质是让Agent通过自我反馈循环来迭代优化输出结果。你可以把它类比成我们写文档的过程——先快速写个初稿,然后回过头审视哪里逻辑不通、哪里表达不清,再针对性修改。实现机制是Agent先生成初始响应,然后对这个响应进行critique评估,发现问题后重新生成改进版本,这个过程可以多轮迭代直到满足质量标准。
关键组件主要包括三个部分:Generator生成器负责产生初始输出,Critic评估器对输出进行批判性分析找出缺陷,Refiner改进器根据评估反馈重新生成优化后的结果。这三个角色可以是同一个大模型切换不同prompt实现,成本很可控。整个过程就是个闭环——生成结果后立刻自我批判,发现具体问题就带着改进建议重新生成,这个循环可以跑多轮直到质量达标。
实现时需要设计好评估维度,比如代码生成场景会检查语法正确性、逻辑完整性、边界条件处理等;文本生成则关注事实准确性、逻辑连贯性、表达清晰度。终止条件也很关键,可以设置最大迭代次数,或者当Critic评分达到阈值时停止。核心价值在于将人类的迭代思考过程内化到Agent的执行流程中,相比传统的单次生成,这种机制能显著提升复杂任务的成功率。
扩展分析
设计思想与核心机制
Self-Refinement的核心灵感来自人类专家的工作方式。我们写代码时不会一次就写完美,都是先实现功能,然后Review发现性能问题、边界情况没考虑,再回去优化。这个思考-反思-改进的循环被抽象成了Agent的执行模式。传统做法是收集大量失败案例去fine-tune模型,需要人工标注、成本高还不够灵活。Self-Refinement巧妙在让模型利用自己已有的评估能力来驱动改进,让Agent自己给自己当老师,不需要人工反复标注对错数据。
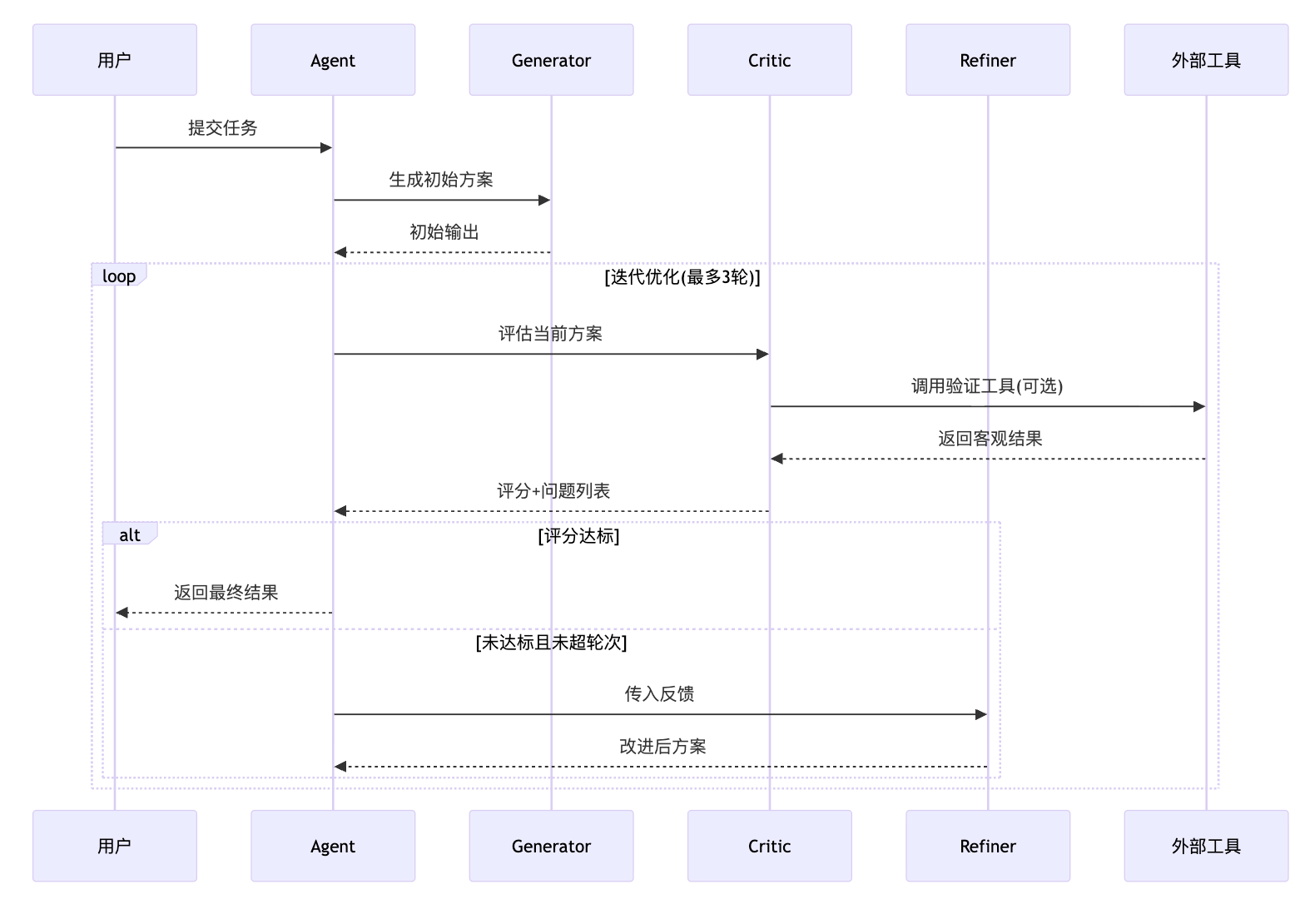
三大组件的协作逻辑需要讲清楚。Generator的职责是快速给出候选答案,这个阶段追求的是覆盖可能性而不是完美。比如让Agent生成商品推荐理由,第一版可能只是列举了基础属性。接下来Critic登场,它的prompt会被设计成挑剔的评审角色——检查推荐理由是否结合了用户历史行为、是否突出了差异化卖点、表达是否够吸引人。关键是Critic不只说"不好",而是给出结构化反馈,比如"缺少个性化元素"、"未体现时效性优势"。然后Refiner拿到这些具体意见,带着明确的改进目标重新生成。
这里有个重要的技术细节:这三个组件最经济的做法是用同一个LLM切换prompt角色。Generator的prompt是"根据用户需求生成推荐文案",Critic的prompt变成"你是一个严格的文案审核专家,从准确性、吸引力、个性化三个维度评估以下内容并指出问题",Refiner的prompt则是"根据以下反馈改进推荐文案"。三次调用同一个模型,但System Prompt的角色设定完全不同,这既展示了工程实用性,又体现了对Prompt Engineering的深刻理解。
反馈循环机制是实现的核心难点。怎么判断什么时候停止迭代?一直循环下去怎么办?你需要从两个维度设计终止策略。第一个是基于质量阈值:在Critic阶段给每个评估维度打分,比如代码正确性、性能、可读性各占权重,当综合得分超过8分就认为达标可以终止。这个阈值需要根据任务重要性调整,核心交易链路可能要求9分以上,辅助功能7分就够了。第二个是工程保底策略:设置最大迭代次数比如3轮,避免陷入无限循环。实际观察发现大部分任务在2-3轮内就能收敛,如果第三轮还没达标,说明任务本身可能超出了当前模型能力边界,这时候应该降级到人工介入或使用备选方案。
很多人容易混淆Self-Refinement和其他优化方法。Fine-tuning的思路是用大量标注好的正确答案去调整模型参数,适合任务模式固定的场景,但需要持续收集数据、训练成本高。RLHF依赖人类给reward信号,需要专业标注团队持续参与。Self-Refinement的独特之处在于完全自给自足——它假设模型已经具备了基础的生成能力和评估能力,只是需要一个机制把这两个能力串起来形成闭环。这让它特别适合快速迭代的业务场景,不需要等数据积累和模型训练周期。
还有个常见误区必须澄清。很多人以为Self-Refinement就是把同一个问题多问LLM几次,其实完全不是。多次独立调用是希望通过随机性碰运气,而Self-Refinement是结构化的反馈改进——每一轮的输入都包含了上一轮的输出和明确的问题诊断,是有向的迭代过程。另一个相关概念是Self-Consistency,它是生成多个独立答案然后投票选最一致的,本质是通过多样性降低随机误差。Self-Refinement是单条路径的深度优化,两者解决的问题维度不同,实际系统中可以结合使用。
Prompt Engineering在这里的作用常被忽视但至关重要。Self-Refinement的效果很大程度取决于Critic的prompt设计。糟糕的评估prompt只会说"这个答案不够好",但好的prompt会明确评估标准。拿SQL生成举例,Critic的prompt应该包含"检查是否有SQL注入风险、JOIN逻辑是否会产生笛卡尔积、是否使用了索引字段作为过滤条件"这些具体检查项。Refiner的prompt也需要技巧,要引导它针对性改进而不是全盘重写,比如"保留原有查询结构,仅优化WHERE子句中的索引使用"。
Self-Refinement的前提是模型本身具备评估能力,如果模型连什么是好答案都判断不准,Critic给出的反馈就是噪音。另外对于需要外部知识验证的任务,比如事实核查,光靠模型自己反思是不够的,需要引入外部工具做检索增强。还有就是迭代会增加推理成本,需要在质量提升和资源消耗之间做trade-off。
实战落地与代码实现
Self-Refinement最适合那些有明确质量标准但单次生成很难达标的任务。代码生成场景里,第一版代码可能实现了功能但没考虑异常处理,Critic能发现缺少try-catch、没校验入参这类问题,Refiner就能针对性补充。相比之下简单的问答任务,比如查询天气,单次生成就够了,加refinement反而浪费资源。文本创作场景也很典型,比如生成营销文案,初版可能平铺直叙罗列产品参数,Critic从用户视角审查会发现缺少情感共鸣、没有行动号召,Refiner就能调整表达重点。推理任务同样受益明显,像数学题求解,第一步可能推导方向就错了,通过Critic检查中间步骤的逻辑链条,能及早发现分支选择问题重新规划路径。
实现的核心难点在评估标准设计和停止条件设置。评估标准要具体可操作——不能只说检查代码质量,而是要拆解成语法正确性用编译检查、逻辑完整性看是否覆盖边界条件、性能合理性检测时间复杂度。停止条件需要双保险:既要设质量阈值比如Critic评分达到85分就停,也要设最大轮次比如3轮保底,避免无限循环消耗资源。
下面是一个完整的Java实现框架,展示核心流程和关键技术点:
publicclassSelfRefinementAgent{
privatefinalLLMClient llmClient;
privatefinalint maxIterations;
privatefinaldouble qualityThreshold;
publicSelfRefinementAgent(LLMClient llmClient){
this.llmClient = llmClient;
this.maxIterations =3;
this.qualityThreshold =0.85;
}
publicStringexecute(String task){
String output =generate(task);
for(int i =0; i < maxIterations; i++){
CriticResult evaluation =critique(output, task);
// 达标即返回
if(evaluation.getScore()>= qualityThreshold){
System.out.println("质量达标,迭代"+(i +1)+"轮后完成");
return output;
}
// 没发现具体问题也停止,避免空转
if(evaluation.getIssues().isEmpty()){
System.out.println("未发现改进点,提前终止");
break;
}
// 带着反馈重新生成
output =refineWithFeedback(output, evaluation.getIssues());
}
System.out.println("达到最大迭代次数,返回最终版本");
return output;
}
privateStringgenerate(String task){
String prompt ="根据以下需求生成解决方案,注重功能完整性:\n"+ task;
return llmClient.call(prompt);
}
privateCriticResultcritique(String output,String task){
String prompt =String.format(
"你是一个严格的质量评审专家。评估以下方案是否满足需求:\n\n"+
"原始需求:%s\n\n"+
"生成方案:%s\n\n"+
"评估维度:\n"+
"1. 准确性:是否正确理解需求并给出对应方案\n"+
"2. 完整性:是否覆盖所有必要场景和边界条件\n"+
"3. 健壮性:是否考虑异常处理和容错机制\n\n"+
"返回JSON格式:\n"+
"{\n"+
" \"score\": 0.0-1.0的综合评分,\n"+
" \"issues\": [\"具体问题1\", \"具体问题2\"]\n"+
"}",
task, output
);
String response = llmClient.call(prompt);
returnparseEvaluation(response);
}
privateStringrefineWithFeedback(String previousOutput,List<String> issues){
String prompt =String.format(
"请改进以下方案,针对性解决发现的问题:\n\n"+
"当前方案:\n%s\n\n"+
"发现的问题:\n%s\n\n"+
"改进要求:保留合理部分,仅修正问题点,不要全盘重写",
previousOutput,
String.join("\n", issues)
);
return llmClient.call(prompt);
}
privateCriticResultparseEvaluation(String jsonResponse){
// 解析JSON响应,提取score和issues
// 实际实现需要处理JSON解析异常
try{
JSONObject json =newJSONObject(jsonResponse);
double score = json.getDouble("score");
List<String> issues =newArrayList<>();
JSONArray issuesArray = json.getJSONArray("issues");
for(int i =0; i < issuesArray.length(); i++){
issues.add(issuesArray.getString(i));
}
returnnewCriticResult(score, issues);
}catch(Exception e){
// 解析失败时返回保守评估
returnnewCriticResult(0.5,List.of("无法解析评估结果"));
}
}
// 评估结果封装类
staticclassCriticResult{
privatefinaldouble score;
privatefinalList<String> issues;
publicCriticResult(double score,List<String> issues){
this.score = score;
this.issues = issues;
}
publicdoublegetScore(){return score;}
publicList<String>getIssues(){return issues;}
}
}
这段代码的价值在于展示了Prompt角色切换的具体实现。每轮都把上一轮的输出和评估反馈一起传给Refiner,形成上下文连贯的改进链条,而不是每次从头开始。Critic的prompt包含了明确的评估维度和结构化输出要求,必须明确告诉模型从哪些角度检查、用什么格式返回,不能让它自由发挥。
实际落地时有几个经验值得注意。迭代次数控制方面,不要贪心设置太多轮次,实测发现2-3轮就能覆盖大部分改进空间,第4轮往往开始出现过拟合——模型为了提高评分反而改出新问题。评估维度设计上,维度太少评估不全面,太多又容易冲突。一般3-5个维度就够,而且要给权重——核心功能正确性权重高,代码风格这种可以低一点。
最常见的问题是评估标准模糊,Critic只会说"逻辑不够严谨",但Refiner根本不知道怎么改。好的做法是让Critic指出具体位置和具体问题,比如"第15行缺少对空指针的判断"。这需要在Critic的prompt里加上"请指出问题的具体位置和改进建议"这类引导。在SQL查询生成任务中,Agent初次生成查询语句后,Critic会检查是否处理了NULL值、JOIN条件是否正确、索引使用是否合理,发现问题后Refiner根据这些具体反馈重写SQL。
性能优化方面,迭代过程会多次调LLM,成本会叠加。工程上可以把前几轮的输出缓存起来,如果后续遇到相似任务直接复用。另外Critic的评估逻辑如果包含规则检查部分,比如语法校验、格式检测,可以用传统工具先跑一遍,只把需要语义理解的部分交给LLM,能大幅降低调用次数。
进阶应用与架构思考
Self-Refinement的效果天花板取决于模型的评估能力上限。如果模型本身就分辨不出什么是好答案,再怎么迭代也是原地打转。遇到这种情况可以考虑引入外部工具做辅助评估,比如代码生成任务可以接入单元测试框架,用测试通过率作为客观评分,这比纯靠模型自己判断要可靠得多。对于能够客观验证的任务,可以结合工具输出。SQL生成可以在沙箱环境里实际执行看结果集是否符合预期,这样Critic的评估不是纯靠模型主观判断,而是有Ground Truth做支撑。
也可以设计多个Critic从不同角度评估,一个负责功能正确性,一个负责性能优化,一个检查安全风险,最后综合多维度反馈。这样单点失误的影响会被稀释,体现了Multi-Agent协作的思想。对于那些质量容忍度高、响应时延要求严格的场景,比如智能客服的闲聊问候,单次生成就够了。多轮迭代带来的几毫秒延迟和额外推理成本,对用户体验的边际收益很低。技术选型需要从成本收益角度权衡。
Self-Refinement和其他Agent框架的结合也值得思考。ReAct关注的是推理和行为的交替,Agent每一步都要决定是继续思考还是调用工具。Self-Refinement可以嵌入到ReAct的每个推理步骤里,比如Agent规划出一个行动方案后,先用Critic评估这个方案的合理性,发现逻辑漏洞就重新规划,通过评估后再执行。这相当于在行动前加了个质量门控,能减少无效的工具调用和资源浪费。
在多模态或具身智能场景,Self-Refinement的思路同样适用。图像生成任务里,Agent先生成初版图像,Critic可以调用目标检测模型检查是否包含了prompt要求的所有元素,或者用CLIP模型评估图文一致性,发现问题后通过调整生成参数或局部修复来改进。具身智能场景会更复杂,机器人执行任务时的Critic可能需要结合传感器反馈,比如抓取物体时通过力传感器判断抓稳了没有,没抓稳就调整手爪姿态重试。核心都是建立感知-评估-调整的闭环。
如果你做过文本摘要功能,可以借鉴Self-Refinement的思路加入校验环节——让模型对比原文和摘要,检查重要实体、数值、因果关系是否都覆盖了,发现缺失就重新生成并补充。虽然不是完整的多轮迭代,但这种即时反馈机制确实能把召回率显著提升。这种将学到的概念迁移到实际场景的能力,正是工程实践的核心价值所在。