精炼回答
面对这道题,很多候选人容易陷入纯技术细节的陷阱,要么大谈模型优化理论,要么死磕代码质量标准。面试官其实想考察的是你对工程化落地的理解,也就是在真实场景中如何让AI工具既快又好地生成代码。
回答时可以采用"双线并进"的思路。先说工具侧的性能优化,这部分点到即止就好,重点说清楚"让AI响应更快"的几个关键手段,比如模型压缩、KV cache、流式输出这些。这块不用展开太多原理,用一句话说明"通过量化把模型从几十GB压到几GB,推理速度提升3-5倍"这种具体效果更有说服力。
然后把重心转移到生成代码的质量保障上,这才是面试官真正关心的。可以这样组织:"代码性能不能靠AI自觉,得靠流程兜底"。先讲前置约束,在prompt里明确要求"使用缓存避免重复查询"或"禁止三层以上循环嵌套";再讲后置检测,集成静态分析工具自动扫描时间复杂度、数据库慢查询这些;最后讲验证闭环,把benchmark结果反馈给AI迭代优化。
举个具体场景会让回答更有画面感。比如用AI生成商品推荐接口时,初版代码可能对每个商品都单独查数据库,典型的N+1问题。这时候通过profiling发现慢查询,把监控日志作为context追加到prompt里,要求"改用批量查询+Map索引",AI就能生成优化版本。这种"问题驱动迭代"的例子比空谈原理更能体现工程能力。
扩展分析
工具性能与代码质量的双重优化
这道题目藏着一个认知陷阱,很多候选人一听到"AI编程工具性能优化",第一反应就是去讲模型推理加速、GPU调度这些偏底层的技术。但你要明白,面试官问这个问题的真实意图是想看你对整个研发链路的理解深度。AI编程工具的性能优化本质上是一个系统工程问题,它涉及三个层次的性能:模型响应性能、生成代码的运行性能,以及人机协作的效率性能。
工具侧的性能优化其实是有演进历程的。早期的代码生成工具像CodeT5、Codex这些都是走云端大模型的路线,每次生成都要经过网络传输,延迟可能要几秒甚至十几秒。到了2023年之后,随着模型压缩技术成熟,出现了一批端侧运行的小模型,比如StarCoder的1B、3B版本,可以在本地实时补全代码。这背后的核心技术包括量化、剪枝、知识蒸馏这些手段,通过INT8量化能把模型体积压缩到原来的四分之一,配合KV cache复用历史计算结果,首token延迟可以控制在100ms以内,这对开发体验至关重要。
更进阶的做法是混合架构。比如日常的代码补全用本地小模型快速响应,涉及复杂逻辑生成时才调用云端大模型。这种策略能在性能和质量之间找到平衡点。基于prompt复杂度的路由策略可以这样设计:检测到包含"多线程"、"事务处理"这类关键词时就走云端模型,单纯的getter/setter就用本地模型秒出。
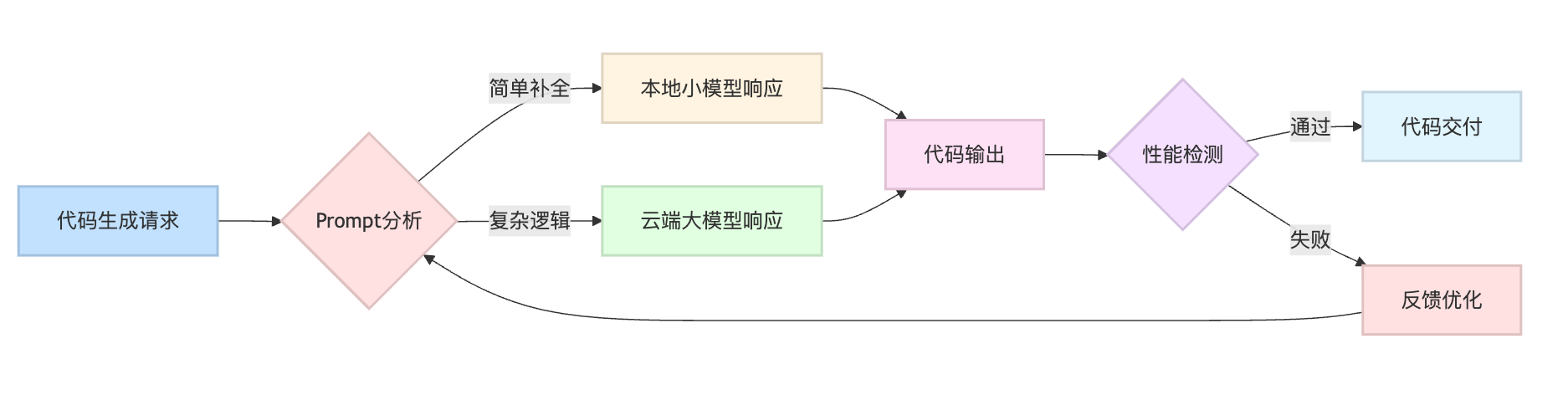
但这里有个容易被忽略的点,工具再快也只是手段,真正考验工程能力的是生成代码的性能保障体系。面试官更想听到的是你怎么在实际场景中防止AI生成低效代码。这就要讲到"左移"和"右移"两个策略。左移是指在生成阶段就通过Prompt Engineering约束行为,右移是指在生成后通过自动化工具检测和修复。
Prompt Engineering这块不是写几句话要求"代码要高效"这种模糊描述,对AI来说没什么用。有效的做法是把性能规则结构化,比如在prompt里注入这样的约束:"遵循以下规范:数据库查询必须使用预编译语句,循环内禁止执行IO操作,集合遍历优先使用Stream API而非嵌套for循环。"这种具体到操作层面的指令,AI的执行效果会好很多。更高级的团队会维护一个性能模式库,不同场景自动注入对应的约束规则。
再往下走就是后置检测机制。这里要避免陷入工具罗列的误区,面试官不想听你把SonarQube、CheckStyle这些工具名字背一遍。我们会在CI流程中集成静态分析,重点检测三类问题:时间复杂度退化、资源泄漏风险、阻塞操作。举个具体的检测案例,比如生成的分页查询代码里出现了全表扫描,通过执行计划分析工具能自动识别出缺失索引的问题,这时候可以把慢查询日志作为反馈追加到prompt里,让AI重新生成优化版本。
这就引出了整个体系最核心的部分——闭环优化机制。AI编程工具跟传统的代码生成器不同,它是可以基于反馈持续进化的。性能保障不是一次性动作,而是构建一个观测-分析-优化的循环。具体来说,线上运行的代码会产生各种监控数据,比如接口响应时间、数据库慢查询日志、CPU/内存profiling结果。把这些真实的性能瓶颈数据整理成案例,沉淀到知识库里,后续生成类似代码时就能作为参考上下文。
假设你在开发一个内容推荐功能,AI生成的初版代码是这样的逻辑:从数据库取出1000个候选内容,然后逐个调用算法服务计算相似度,最后排序取Top10。这种实现在测试环境可能没问题,但上线后发现P99延迟达到3秒。这时候通过链路追踪发现瓶颈在频繁的RPC调用上,把trace数据作为context反馈给AI,要求"改为批量请求,单次传输不超过100个",生成的新版本就会加上分批逻辑。如果团队把这个优化案例记录到知识库里,下次生成推荐相关代码时,AI就能自动检索到这个最佳实践。
现在比较流行的做法是结合Observability平台和RAG技术。监控系统自动标注性能异常代码片段,通过向量检索匹配到历史优化案例,再用小模型总结出性能改进建议,最后推送给开发者或者直接触发AI重生成。这种从数据到知识再到行动的链路,体现的是工程化思维而不仅仅是工具使用。
还有一个容易被忽视的角度是人机协作的效率优化。AI生成代码的过程不是黑盒,开发者的交互方式会直接影响最终质量。比如采用渐进式生成策略,先让AI输出核心逻辑框架,人工review确认后再生成细节实现。或者用Diff模式展示修改建议而不是整段替换,这样能保留开发者的上下文理解。这些细节看起来不起眼,但能显著提升协作效率,减少返工成本。
真实场景下的实践落地
面试时讲完理论框架,面试官十有八九会追问"能不能说个具体场景"。最容易展开的场景是API接口生成,因为这类代码性能问题最直观。拿常见的列表查询接口举例,这是AI编程工具最高频的使用场景,但也最容易踩性能坑。开发者给AI一个需求"生成用户订单列表接口,支持按时间筛选和分页",AI可能会生成这样的代码结构:
// AI初版生成的代码 - 典型的N+1问题
publicList<OrderVO>getOrderList(Long userId,Date startTime,Date endTime){
List<Order> orders = orderMapper.selectByUserIdAndTime(userId, startTime, endTime);
List<OrderVO> result =newArrayList<>();
for(Order order : orders){
OrderVO vo =newOrderVO();
vo.setOrder(order);
// 每个订单单独查询商品详情 - 性能隐患
vo.setProduct(productRpc.getProductDetail(order.getProductId()));
// 每个订单单独查询物流信息 - 性能隐患
vo.setLogistics(logisticsRpc.getLogisticsInfo(order.getOrderId()));
result.add(vo);
}
return result;
}
这种实现在测试数据下跑得挺快,但一上生产就出现慢查询告警。我们在代码生成后会自动跑性能检测流程,用explain分析生成的SQL语句,如果发现全表扫描或者嵌套循环查询,直接打回要求重新生成。这里很多人会说"把错误信息反馈给AI",但这还不够具体。更有说服力的做法是把慢查询日志中的执行计划、扫描行数这些指标提取出来,组装成结构化的反馈prompt,明确告诉AI"当前实现扫描了10万行数据,需要改用批量查询+内存join的方式,预期扫描行数降到100以内"。
基于性能反馈重新生成的代码会有关键改动:
// 基于性能反馈重新生成的代码 - 批量查询优化
publicList<OrderVO>getOrderList(Long userId,Date startTime,Date endTime){
List<Order> orders = orderMapper.selectByUserIdAndTime(userId, startTime, endTime);
// 批量收集需要查询的ID
Set<Long> productIds = orders.stream()
.map(Order::getProductId)
.collect(Collectors.toSet());
Set<Long> orderIds = orders.stream()
.map(Order::getOrderId)
.collect(Collectors.toSet());
// 单次批量RPC调用
List<Product> products = productRpc.batchGetProducts(newArrayList<>(productIds));
List<Logistics> logistics = logisticsRpc.batchGetLogistics(newArrayList<>(orderIds));
// 构建Map索引加速查找
Map<Long,Product> productMap = products.stream()
.collect(Collectors.toMap(Product::getProductId, p -> p));
Map<Long,Logistics> logisticsMap = logistics.stream()
.collect(Collectors.toMap(Logistics::getOrderId, l -> l));
// O(n)时间复杂度组装结果
return orders.stream().map(order ->{
OrderVO vo =newOrderVO();
vo.setOrder(order);
vo.setProduct(productMap.get(order.getProductId()));
vo.setLogistics(logisticsMap.get(order.getOrderId()));
return vo;
}).collect(Collectors.toList());
}
这个场景体现的是约束前置加检测后置的组合策略。前置约束是在prompt里要求"禁止在循环内执行RPC或数据库查询",后置检测是用静态分析工具扫描代码结构,两道关卡确保生成代码不会出现明显的性能劣化。
如果是更复杂的数据处理类任务,比如生成一个数据导出功能,需要从数据库读取百万级记录然后转换格式输出。AI初版代码可能会一次性load全部数据到内存,直接导致OOM。这时候你的应对策略就要体现分层思维,不能指望AI一次就生成完美方案,而是要在prompt里注入流式处理的模板。我们会在知识库里沉淀高频场景的最佳实践,比如大数据处理场景会自动注入"使用游标分批读取,每批1000条,处理完立即释放"这样的代码片段作为参考。AI在生成时会检索到这个模板,照着这个模式来组装逻辑。
这里可以自然引出2025年的新趋势——基于RAG的性能模式库。现在很多团队会把历史上踩过的性能坑整理成向量知识库,AI生成代码前会先检索相似场景,如果发现有人在"订单导出"任务里遇到过内存溢出,就会主动采用流式处理方案。这种方式让AI能学习团队的历史经验,而不是每次都从零开始试错。
说完正向案例,一定要讲避坑经验,这能体现你的实战深度。最典型的误区是过度依赖AI的自我优化能力。很多人以为把性能要求写在prompt里AI就能搞定,但实际上AI对"高性能"这种抽象概念理解很模糊。比如你要求"优化查询性能",AI可能只是加个索引提示注释,根本没改查询逻辑。有效的做法是把性能要求量化,比如明确说"接口响应时间不超过200ms,数据库查询次数不超过3次",这种可度量的约束AI才能准确执行。
另一个容易踩的坑是忽略渐进优化策略。有些团队追求一步到位,在prompt里堆砌各种性能规则,结果AI生成的代码过度设计,加了一堆用不上的缓存和异步逻辑。更成熟的做法是采用三轮迭代策略:第一轮让AI生成功能正确的基础版本,跑benchmark测试;第二轮针对性能瓶颈点追加优化提示;第三轮做压测验证。这种渐进式方式比一次性生成复杂方案更可控,也更容易定位问题。
最后可以提一个进阶技巧来拔高回答层次。怎么评估AI生成代码的性能是否达标?我们会维护一个性能基线库,记录人工编写的同类功能的性能指标。AI生成代码后会自动跟基线做对比,如果响应时间、资源消耗等指标超过基线的20%,就触发人工review流程。这个阈值是基于历史数据统计出来的,既不会误杀正常波动,也能拦截明显的性能劣化。
从工具使用到工程哲学的跃迁
当面试官抛出这道题时,表面上是在考AI工具的性能优化,实际上是在设置一个多维度的观察点。他想看的不是你能背出多少技术名词,而是你有没有经历过AI工具从引入到落地的完整周期。面试官最常见的后续追问会围绕"如何平衡"展开,比如他可能会问:"生成速度和代码质量发生冲突时怎么办?"
这时候千万别说"两个都要保证"这种空话。更聪明的回答方式是先分场景:高频简单任务优先保证速度,用本地小模型秒级响应,核心业务逻辑宁可慢一点也要用大模型生成后多轮检测。然后补充决策机制:我们会根据代码的影响范围来动态调整策略,比如公共库的工具函数会走严格的三轮检测流程,临时脚本就允许快速生成快速验证。这种回答既体现了权衡思维,又展现了实际经验。
另一个高频追问是"怎么让团队接受AI生成的代码"。这个问题背后考察的是你的工程化推广能力。初期最大的阻力往往不是技术问题,而是信任问题。我们的做法是先建立透明的度量体系,让每段AI生成的代码都能追溯到生成prompt、检测报告、人工review记录。然后设置灰度期,AI生成的代码必须由senior开发者review通过才能合入主干,积累三个月的数据后,发现AI生成代码的线上bug率反而比纯手写低15%,这时候团队自然就接受了。
如果面试官想考察你的技术深度,可能会问到跟架构设计的关联。AI编程工具本质上改变了代码的生产方式,这要求我们在架构设计时就要考虑"可生成性"。比如采用清晰的分层架构、定义标准的接口规范、维护详细的API文档,这些都能让AI更准确地生成符合预期的代码。2025年开始出现架构即代码的新模式,开发者先用AI生成系统架构图和接口定义,确认无误后再让AI填充具体实现。这种自顶向下的方式能显著降低AI生成代码的返工率。
还有一个容易被忽略的关联点是跟DevOps流程的整合。AI编程工具不是独立存在的,它需要嵌入到整个CI/CD链路里。代码生成后自动触发单元测试、性能基准测试、安全扫描,所有报告汇总成反馈数据再输入给AI。关键是要把这个循环做到自动化,否则人工介入的成本会抵消掉AI带来的效率提升。
随着MCP协议这类标准的推广,未来AI编程工具可能会具备更强的上下文感知能力,它不仅能读取代码仓库,还能实时获取监控数据、用户反馈、线上性能指标。这意味着性能优化会变成一个持续的自动化过程,AI能根据真实运行情况自主提出优化建议甚至直接生成补丁。到那时候,我们的重点可能会从"怎么让AI生成好代码"转向"怎么设计让AI能理解的系统"。这种前瞻性思考能让面试官感受到你的技术敏感度和学习能力,也是区分普通工程师和技术专家的关键分水岭。