精炼回答
AutoGPT的核心原理是将大语言模型包装成一个循环执行的智能代理,通过持续的"思考-行动-观察"循环来自主完成复杂任务。它本质上是把GPT从对话工具升级成了能自主执行任务的智能代理,最大的特点是能把"写一份竞品分析报告"这种模糊目标,自己拆解成搜索信息、提取数据、对比分析、生成文档这一系列具体步骤,然后循环执行直到完成。
具体工作机制是这样的:首先你给它设定一个目标,比如"调研竞品并生成分析报告",AutoGPT会调用GPT模型将这个大目标分解成多个子任务,形成执行计划。然后进入循环:每一步它会思考当前应该做什么,从预设的工具集中选择合适的工具执行,比如用搜索API收集信息、用代码执行器处理数据、用文件操作保存结果等。执行完毕后,它会把结果反馈给GPT,让模型评估进展、判断是否需要调整策略,然后继续下一步行动。
和ChatGPT的区别在于,ChatGPT是你问一句它答一句,而AutoGPT是你给个目标它就开始自己规划、自己调用工具、自己检查结果,形成一个完整的执行闭环。关键技术点在于提示词工程和记忆管理。AutoGPT在每次调用GPT时,会把目标、历史操作、当前状态都塞进提示词里,让模型保持上下文连贯性。为了突破token限制,它使用向量数据库存储长期记忆,只把相关信息检索出来参与决策。这种自主性的实现本质是让GPT既当大脑又当执行者,通过工具调用能力把纯文本生成扩展到实际操作层面。
不过它也有明显局限:容易陷入循环思考、API调用成本高、对复杂任务的规划能力还不够稳定。
扩展分析
核心机制深度解析
从一个任务的生命周期来说明AutoGPT的工作原理,这样能把各个核心组件串起来。假设你给它的目标是"分析最近三个月用户对某款手机的评价趋势",AutoGPT首先会调用GPT模型进行任务分解,这个过程其实就是让大模型做思维链推理。它会在prompt里告诉GPT:"你是一个任务规划专家,现在要把这个目标拆解成可执行步骤"。GPT会输出类似这样的计划——第一步从电商平台抓取评论数据,第二步清洗和结构化数据,第三步按时间维度做情感分析,第四步生成可视化图表,第五步总结趋势和洞察。这个拆解过程不是预设的规则,而是大模型根据目标语义理解后生成的,这就是为什么它能处理各种不同类型的任务。
任务规划阶段最能体现AutoGPT的智能性。但它怎么知道该用什么工具呢?AutoGPT维护了一个工具清单,每个工具都有详细的功能描述和参数说明。比如搜索工具会注明"可以根据关键词检索网页内容,参数包括query和max_results",文件操作工具会说明"可以读写本地文件,参数是file_path和content"。当GPT在规划阶段决定下一步要搜索信息时,它会输出结构化的调用指令,通常是JSON格式。执行器接收到GPT输出的指令后,会解析出工具名称和参数,然后真正去调用对应的API或函数。假设GPT输出了{"tool": "web_search", "query": "iPhone 15 用户评价", "max_results": 50},执行器就会调用搜索API,把返回的网页内容再反馈给GPT。这个过程本质上就是函数绑定机制——把自然语言的意图翻译成可执行的代码调用。
每次工具执行完,AutoGPT不会直接进入下一步,而是把执行结果、当前进展、遇到的问题都整理成一段文本,再次输入给GPT,让它评估这一步是否成功、是否需要调整策略。拿刚才搜索评论的例子来说,如果搜索返回的结果太少或者质量不高,GPT在下一轮推理时可能会决定:"需要调整搜索关键词,增加'电池续航'、'拍照效果'等具体维度",或者"改用爬虫工具直接抓取电商详情页的评论区"。这种纠错能力来自于大模型本身的推理能力,AutoGPT的作用是把推理结果转化成实际行动,再把行动结果反馈回去形成闭环。
由于GPT的token限制,不可能把所有历史操作都放进prompt,所以AutoGPT设计了分层记忆结构。短期记忆就是当前对话窗口内的最近几轮交互,会完整保留在prompt里,确保上下文连贯性。长期记忆则会把历史操作、中间结果、关键信息都提取摘要,存入向量数据库,比如用embedding模型把"已完成的任务清单"转成向量存储。每次GPT需要做决策时,AutoGPT会根据当前任务从向量库里检索相关的历史信息,比如"上次执行类似任务时遇到了什么问题"、"哪些工具的组合效果比较好",把这些检索出的片段插入到prompt里,相当于给GPT提供参考案例。这不是简单的日志记录,而是一种检索增强的决策机制,让Agent能从过往经验中学习。
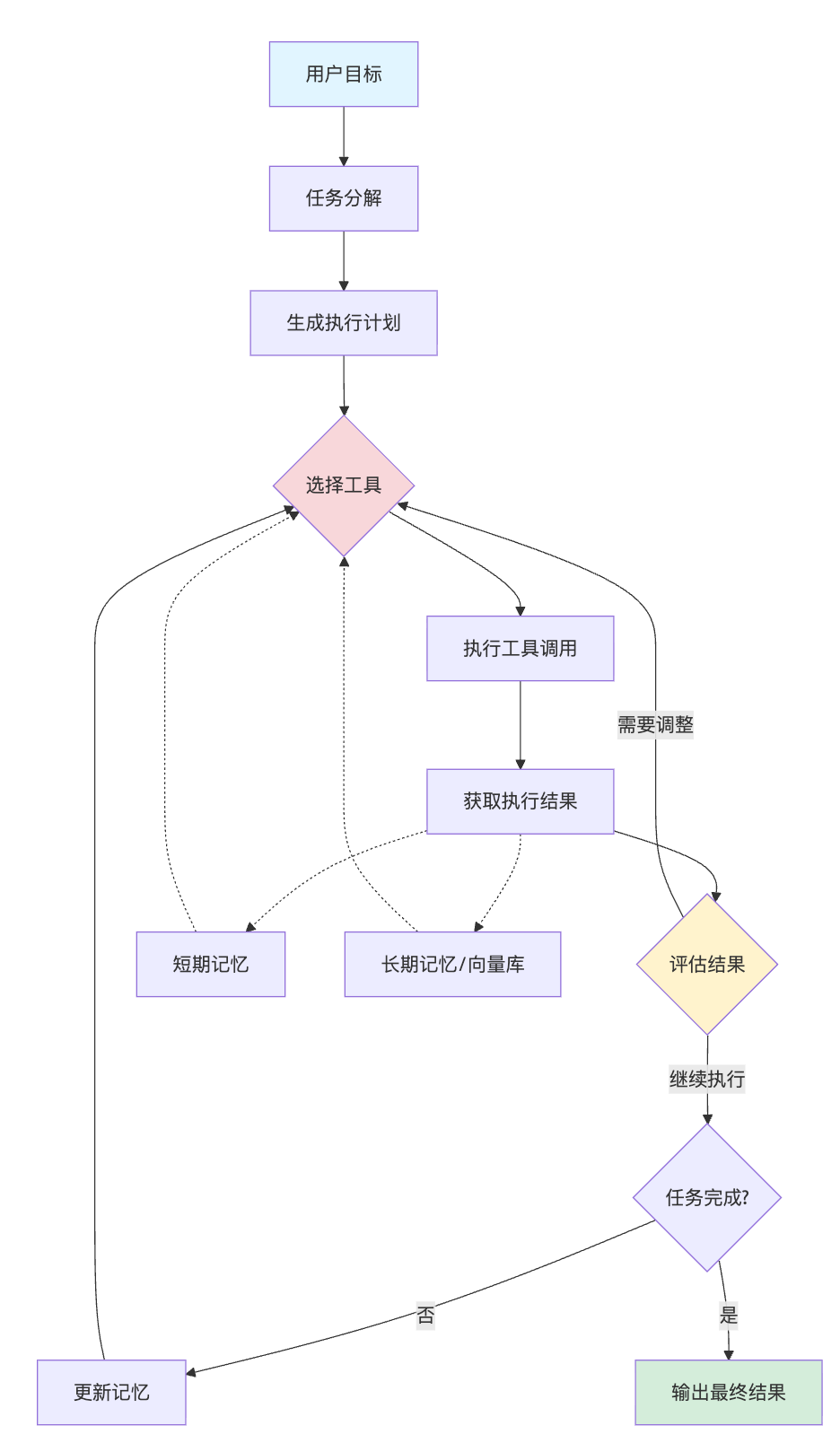
用一个完整的例子把这些组件都串起来会更清楚。假设目标是"生成一份竞品价格对比表",AutoGPT启动后,首先Planner模块会把它拆解成:确定竞品清单、获取各家价格、整理成表格、保存文件。第一轮执行时,GPT可能会说"先用搜索工具找出主要竞品",执行器调用搜索API返回结果后,GPT根据搜索内容提炼出三个品牌。第二轮,GPT决定"对每个品牌调用价格查询工具",但发现某个品牌没有直接的API,它会调整策略改用爬虫。第三轮整理数据时,发现价格单位不统一,GPT会调用代码执行工具写个转换脚本。最后调用文件操作工具生成CSV文件。整个过程中,每一步的决策都基于上一步的结果,而且遇到问题能动态调整,这就是自主执行的完整体现。
和传统的RPA有什么本质区别呢?传统RPA比如UiPath、Blue Prism,本质是录制人的操作轨迹,然后像播放录像一样重复执行。如果页面元素位置变了、流程逻辑调整了,RPA就傻眼了,必须人工重新录制。而AutoGPT是基于目标和语义理解的,它不关心具体怎么点按钮,而是理解"要获取用户评论数据"这个目标,自己选择合适的方式,可能今天用API、明天用爬虫,遇到问题还能自己想办法绕过去。与普通LLM的对比也要讲清楚:普通的LLM应用,比如ChatGPT或者我们自己做的对话系统,本质是"函数式"的——输入prompt,输出response,每次调用都是独立的。AutoGPT则是"有状态的循环系统"——它维护着任务状态、执行历史、工具调用链,每一次GPT调用都是在前一次基础上的延续,整个过程是一个不断演进的决策链。
当然AutoGPT也有明显的限制。自主决策依赖于GPT的推理能力,如果任务过于复杂或者领域知识不足,它的规划可能不靠谱。而且每次决策都要调用GPT API,成本很高,执行效率也不如预设好的工作流。再就是缺乏明确的终止条件,有时候会陷入无意义的循环尝试,这需要人为设置最大执行步数或者预算限制。
实践应用与工具设计
AutoGPT最适合那种目标明确但路径模糊的任务,也就是你知道要什么结果,但不确定具体该分几步、每步用什么方法。比如"整理最近一个月关于AI Agent的重要论文并生成综述",这个目标很清楚,但实现路径可以有很多种——是去arXiv搜索、还是Google Scholar检索、要不要包含博客文章、怎么判断论文重要性、综述用什么结构组织,这些都需要在执行过程中动态决策。这样的开场直接点出了适用场景的本质特征——需要多步推理和动态调整。
拿数据分析场景来说,比如电商平台想分析"为什么某个品类最近转化率下降",这个问题没法用固定SQL查出来。AutoGPT可以先从订单表查整体转化趋势,发现是移动端下降明显,然后调整方向去查移动端的用户行为日志,发现某个支付环节跳出率高,再去调取那个页面的加载性能数据,最后可能发现是因为新上线的功能导致页面加载慢。整个分析路径是根据中间结果逐步调整的,这就是AutoGPT的强项。这不是为了用新技术而用,而是确实解决了固定流程解决不了的问题。
工具设计是成败的关键。最核心的不是选什么技术栈,而是设计一套合理的工具接口规范。每个工具必须包含三个要素:功能描述、参数Schema、返回值约定。功能描述要写得让GPT能理解,比如"根据商品ID获取用户评论,支持按时间范围筛选",而不是技术术语"调用评论服务的queryReviews接口"。参数Schema用JSON Schema定义,明确哪些必填、哪些可选、数据类型是什么。返回值要约定成功和失败的标准格式,这样GPT才能从返回结果中提取有效信息。
工具的粒度设计特别关键。粒度太细,比如把"查询数据库"和"解析JSON"拆成两个工具,GPT就需要更多步骤才能完成任务,既费token又容易出错。粒度太粗,比如整合成一个"生成数据分析报告"的工具,那本质就退化成调用固定函数了,失去了自主性。更好的做法是按照语义完整性来划分——"获取某类数据"是一个工具、"对数据做某种转换"是一个工具、"输出某种格式"是一个工具,这样组合起来既灵活又不会步骤爆炸。
publicclassSearchToolimplementsAgentTool{
@Override
publicStringgetDescription(){
return"搜索互联网信息,根据关键词返回相关网页内容摘要";
}
@Override
publicJsonSchemagetParameterSchema(){
returnJsonSchema.builder()
.addProperty("query","string","搜索关键词",true)
.addProperty("max_results","integer","最大返回条数",false)
.build();
}
@Override
publicToolResultexecute(Map<String,Object> params){
String query =(String) params.get("query");
int limit =(int) params.getOrDefault("max_results",10);
try{
List<String> results = searchEngine.search(query, limit);
returnToolResult.success(results);
}catch(Exception e){
returnToolResult.failure("搜索失败: "+ e.getMessage());
}
}
}GPT拿到这个工具描述后,它知道可以用这个工具搜东西,知道必须提供query参数,max_results可以不给。执行结果统一包装成ToolResult,成功就带上数据,失败就带上错误信息,这样下一轮GPT推理时能准确理解发生了什么。
Prompt的设计直接决定了AutoGPT的可靠性。AutoGPT的Prompt不是简单的一句话指令,而是一个精心设计的提示词模板。通常会分成几个部分:系统角色定义、任务目标、可用工具清单、执行规则、历史上下文。系统角色定义告诉GPT"你是一个任务执行助手,擅长分解复杂目标并选择合适工具",这个定调很重要,能让模型进入正确的推理模式。任务目标就是用户输入的那个最终目的,要清晰无歧义。可用工具清单把那些工具描述都列出来,让GPT知道自己的能力边界。
执行规则是最容易被忽视但又最关键的部分。要明确告诉GPT:每次只输出一个工具调用,输出格式必须是指定的JSON结构,执行前要先思考这一步的目的是什么。还要加上约束条件,比如"如果连续三次工具调用都失败,停止执行并报告问题"、"单次任务最多执行20步",这些规则能防止它陷入死循环或者无限制地消耗资源。
你是一个任务执行助手。当前目标:{user_goal}
可用工具:
1. web_search: 搜索网页内容,参数query(必填)、max_results(可选)
2. data_query: 查询数据库,参数sql(必填)
3. file_write: 保存文件,参数path(必填)、content(必填)
执行规则:
- 每次输出一个JSON格式的工具调用:{"tool": "工具名", "params": {...}, "reasoning": "选择理由"}
- 如果上一步失败,分析原因并调整策略
- 最多执行15步,完成后输出{"action": "finish", "result": "任务总结"}
当前进度:{history_summary}
上一步结果:{last_result}
请决定下一步行动:reasoning字段要求GPT解释为什么选这个工具,这不是多余的,而是强制它做思维链推理,减少随机决策。history_summary是从长期记忆里检索出的相关历史,而不是完整日志,这样既保留了上下文又不会超token限制。finish动作的设计也很重要,给它一个明确的退出机制,否则它不知道什么时候该停。
安全和成本是绕不开的坑。AutoGPT的安全控制需要在多个层面设防。工具层面,所有涉及写操作的工具都要加白名单限制,比如文件写入只能在指定目录下、数据库操作只允许SELECT和有限的UPDATE、API调用要设置Rate Limit。执行层面,引入沙箱机制,代码执行工具必须在隔离容器里跑,访问外部资源要经过代理校验。决策层面,对于高风险操作可以加入人工确认环节,比如GPT要执行"删除超过1000条数据"这种操作时,先暂停执行、通知人工审批,批准后才继续。
成本控制也要具体讲。每次调用GPT都要花钱,如果任务复杂,几十轮交互下来成本就很可观了。策略是设置多级预算控制——单次任务的最大token消耗、单日总调用额度、异常情况的熔断机制。还可以用缓存优化,对于相同的工具调用结果,在一定时间内直接返回缓存,不重复执行。另外选择合适的模型也很关键,简单的决策用GPT-3.5就够了,不一定每次都上GPT-4,这能大幅降低成本。
AutoGPT目前在生产环境用得还比较少,主要是几个硬伤。稳定性不够,GPT的推理有时候会跑偏,同一个任务执行两遍可能走完全不同的路径,结果一致性难保证。效率问题也很明显,动态决策虽然灵活,但比预设工作流慢得多,不适合对响应时间敏感的场景。还有可观测性差,传统系统可以打日志、看调用链,AutoGPT的决策过程在GPT黑盒里,出了问题很难排查。现阶段更实际的做法是混合架构——核心流程用确定性的工作流,在需要灵活决策的环节嵌入AutoGPT式的Agent。比如电商的客服系统,标准问题用规则引擎或固定对话流,遇到复杂的售后纠纷才调用Agent去分析订单历史、查询政策、生成处理方案。这样既保证了主流程的稳定高效,又在需要的地方获得了灵活性。
技术演进与未来思考
AutoGPT、LangChain、Semantic Kernel这些框架解决的问题域其实不太一样。AutoGPT更像是一个完整的自主执行系统,它的重点是"让AI自己跑起来",适合那种给个目标就不管了的场景。LangChain则是一个工具箱性质的框架,它提供了大量预制组件——Chain、Agent、Memory、Tool,你可以像搭积木一样组装成自己需要的应用,更强调灵活性和可组合性。Semantic Kernel是微软推出的,它的设计理念是把AI能力集成到现有应用里,更偏向企业级场景,强调和.NET、Java这些技术栈的深度整合。
如果是做POC验证想法,LangChain的快速迭代能力更合适,几十行代码就能把一个简单的Agent跑起来。如果要做生产级的企业应用,Semantic Kernel的工程化支持更完善,比如它对并发、异常处理、可观测性这些都有考虑。AutoGPT更像是一个研究原型,它展示了Agent系统的完整形态,但要真正用在产品里,通常需要基于它的思想自己实现一套。
怎么评估一个Agent任务执行得好不好?Agent系统的评估不能只看最终结果,因为即使结果对了,过程可能也是低效或者不安全的。任务完成度是最基本的,比如用户要生成一份报告,最后确实拿到了完整的报告文档。但更重要的是执行效率,同样的任务,有的Agent三步就搞定了,有的可能绕了十几步弯路,这背后反映的是规划能力的差异。还有资源消耗,比如API调用次数、token使用量、执行时间,这些直接关系到成本和用户体验。
安全性也很关键但容易被忽视。Agent在执行过程中有没有尝试危险操作、有没有访问不该访问的数据、遇到错误时的降级策略是否合理,这些都需要评估。比如一个数据分析Agent,如果它为了完成任务直接执行了DROP TABLE这种操作,那就算最终给出了答案也是不可接受的。从产品角度看,可解释性也很重要。用户需要理解Agent为什么这么做,如果整个过程是个黑盒,出了问题都不知道从哪里查。所以要关注Agent有没有记录决策依据、中间步骤是否可追溯、能不能生成易懂的执行报告。
幻觉问题在Agent系统里会被放大,因为一步错了后面可能就全错了。应对思路是多层防御。首先在Prompt层面加约束,明确告诉模型"如果不确定就说不知道,不要编造信息",同时提供清晰的事实依据来源要求。工具调用层面做校验,比如SQL工具会先检查语句是否只包含SELECT,文件操作会验证路径是否在白名单内。执行结果层面引入验证机制,比如搜索到的信息可以要求多源交叉验证,数据分析结果可以加基本的合理性检查,如果数值突然暴涨十倍就标记异常让人工介入。
更进一步的方案是引入反思机制,让另一个LLM专门负责审查第一个Agent的输出,类似代码审查的思路。还有就是关键决策点的人机协同,不是所有步骤都自主执行,在高风险节点暂停等待人工确认。比如要发送邮件给客户前,先把邮件内容展示给用户审核,批准了再发送。这种混合模式在现阶段更实用。
Agent技术未来会往几个方向发展。多Agent协作是一个很值得关注的方向,现在大部分都是单Agent系统,但复杂任务往往需要专业分工。比如一个市场分析任务,可能需要一个Agent专门负责数据收集、一个负责数据清洗、一个负责建模分析、一个负责报告撰写,它们之间通过结构化的协议通信,每个Agent专精自己领域,整体效果会比单一Agent强很多。
另一个方向是从Prompt工程走向Fine-tuning。现在的Agent系统严重依赖Prompt质量,但Prompt太长又费token还容易出错。未来可能会出现专门为Agent任务优化的小模型,通过强化学习让它自己学会什么时候该调什么工具、怎么规划路径更高效,这样就不需要每次都在Prompt里塞一堆指令了。
从应用角度看,垂直领域的专用Agent会比通用Agent先成熟。比如专门做SQL生成的Agent、专门做数据可视化的Agent、专门做代码审查的Agent,这些边界清晰、评估标准明确的场景更容易做到生产可用。而且用户对它们的容错度更高,如果一个通用助手出错了用户会觉得"这AI不行",但如果一个SQL助手偶尔生成的语句需要调整,用户会觉得"还不错,省了我不少时间"。
理解AutoGPT的价值不在于盲目追捧新技术,而是从工程角度思考它解决了什么问题、适用于什么场景、当前的局限在哪里。展现出对技术边界的清醒认知,比吹嘘它多么厉害要有价值得多。技术的演进从来不是一蹴而就的,AutoGPT展示了一种可能性,但真正落地还需要在稳定性、成本、安全性上做大量工作。保持对新技术的好奇心,同时用工程思维去审视它,这才是一个优秀技术人应有的态度。