在实践中,一般可以通过Skill创建器(例如Codex自带的 Skill Creator),来协助创建Skill,但是高质量的Skill的标准需要我们自己来把关,推荐通过下面五个流程来创建Skill:
- 判断这个任务值不值得封装
- 提取专家决策和常见****反模式
- 把指令写得简洁且约束合适
- 配齐模板、参考资料和脚本
- 用真实任务反复验证执行效果
编写高质量skill流程详解
一、判断任务值不值得做成skill
1. 任务里有没有“专家直觉”
如果一个任务里,熟手和新手的差距主要体现在边界判断、风险识别、优先级取舍,那它就很适合做成 Skill。
2. 任务是不是足够复杂
如果一个任务一句 Prompt 就能说清,或者三步以内就能完成,通常没必要专门做成 Skill。Skill 不是越多越好。它有维护成本,要写说明、配资源、做测试、反复迭代。
3. 任务会不会反复出现
Skill 的价值在复用。如果你的团队每周都会做类似的分析、审核、发布、改写或生成任务,那么把它沉淀成 Skill,长期收益通常很高。
当一个任务同时具备以上这三个特征时,建议投入去做成Skill。
二、提取 Skill 该写什么
确定任务需要做成skill后,按照下面步骤来提取Skill需要做什么
1. 提取决策树
高质量的 Skill 应该告诉 Agent:
- 什么条件下走方案 A
- 什么条件下切到方案 B
- 什么情况下应该停止、降级或者补充信息
2. 提取反模式和不要做的事情
在工程里,反模式往往非常重要,比如:
- 不要把来源不明的内容当成事实写进输出
- 不要在高风险操作里直接执行修改,应该先生成计划再验证
- 不要为了把结果写完整,擅自编造缺失信息
3. 提取模板和示例
如果任务对输出结构要求很高,那么可以使用模板来描述;如果任务对表达风格、组织方式要求很高,那就使用示例来说明。
三、写清楚指令
Skill里面的指令要符合三个原则:
1. 简洁
Skill不是独占上下文的,还要和 system prompt、对话历史、其他技能信息一起共享窗口,所以每一句话都要值回它的 token 成本。
原则很简单:模型本来就知道的东西,不要重复教;只有任务特有的判断、约束、入口和资源导航,才值得写进 Skill。
2. 自由度匹配
如果任务本身风险很高,比如批量改文件、数据库迁移、部署执行,那就应该给低自由度约束,必要时直接要求调用固定脚本。
如果任务本身需要分析、判断、归纳,比如代码审查、内容策划、方案评估,那就应该保留更高自由度,只给流程边界和质量标准。
3. 渐进式披露
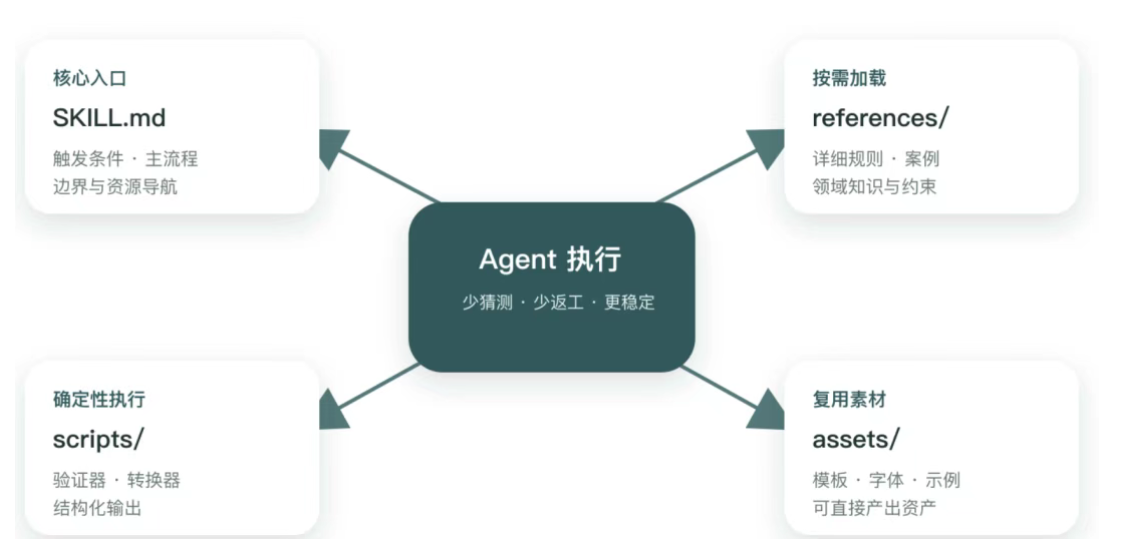
不要把所有细节都塞进SKILL.md,按照下面这些原则组织:
- 主文件里只保留核心流程、触发条件和资源导航
- 详细规则放到references/
- 需要确定性执行的动作放到scripts/
四、配好工具和资源
对一些具有标准流程的子任务,不要让大模型来猜,用工作流来写清楚任务要求。
1. 给 Agent建立工作流
在复杂任务里,checklist非常重要,因为任务链一长,如果没有中间进度和阶段目标,Agent 很容易漏步骤,一个工作流示例如下:先抽取输入、再运行检查、然后整理问题、修复后重新验证、最后再生成结果。
2. 把验证做成闭环
如果任务需要校验,Skill 里不要只写“执行完即可”,写成反馈循环:运行验证器、读取结果、修复问题、再次运行验证器、通过后再进入下一步。
3. 高风险操作先过计划,再执行
如果任务涉及大规模修改、高成本调用或者不可逆操作,最好再加一层“先验证计划”的前置检查。
4. 脚本要对 Agent 友好
Skill如果有脚本,要符合以下要求:
- 输出最好结构化,优先 JSON
- 错误信息里要带修复线索,不要只返回一个exit code
- 能降级就降级,不要一出错就直接崩
- 尽量幂等,避免 Agent 重复调用时把结果越做越乱
五、用真实任务验证,再迭代 Skill
在应用实践中,我推荐一套很实用的迭代方式,如下图所示:
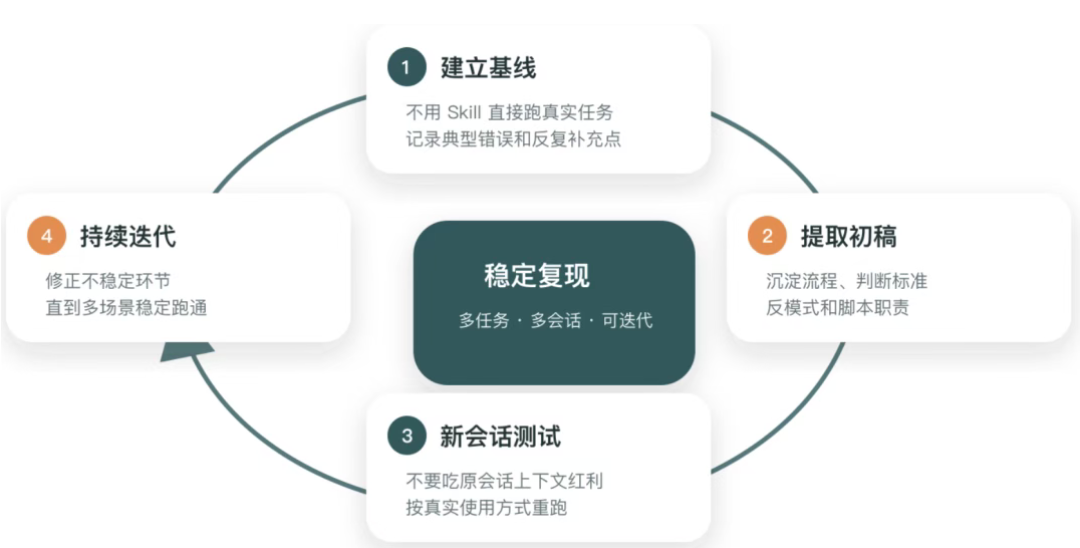
1. 先建立基线
先不用任何 Skill,让 Agent 直接做一次真实任务。
记录它会犯哪些典型错误,哪些信息需要你反复补充,这些失败样本,后面就是 Skill 的评测用例。
2. 再提取 Skill 初稿
根据上面提到的内容标准,整理Skill 的首版:哪些是固定流程;哪些是判断标准;哪些是常见错误;哪些应该由脚本负责
3. 用新会话重新测试
换一个全新的会话,按真实使用方式重新跑评测用例,如果在新会话里任务效果明显更好,说明 Skill 真正起作用了。
4. 持续迭代,直到结果稳定
这一步主要是验证不同场景,多次执行任务观察效果,当然也可以建立测评集,持续优化。