精炼回答
Zero-shot和Few-shot的核心区别在于是否在推理时提供示例。Zero-shot是直接给模型一个任务描述或指令,不提供任何示例,完全依赖模型预训练时学到的知识来完成任务。比如你直接问GPT"将这段文本分类为正面或负面情绪",模型需要自己理解任务并执行。Few-shot则是在prompt中先给模型几个输入输出的示例,让它通过这些例子理解任务模式,然后处理新输入。比如你先展示3个"文本-情绪标签"的配对样本,再让它分类新文本。
两者最大的区别是对模型能力的依赖程度不同。Zero-shot完全依赖预训练知识,Few-shot则是用示例来引导模型理解你的特定需求。就像解数学题,Zero-shot是直接看题目就做,Few-shot是老师先讲几道例题再让你做。题型常规时直接做就行,题型新颖时看例题效果会更好。
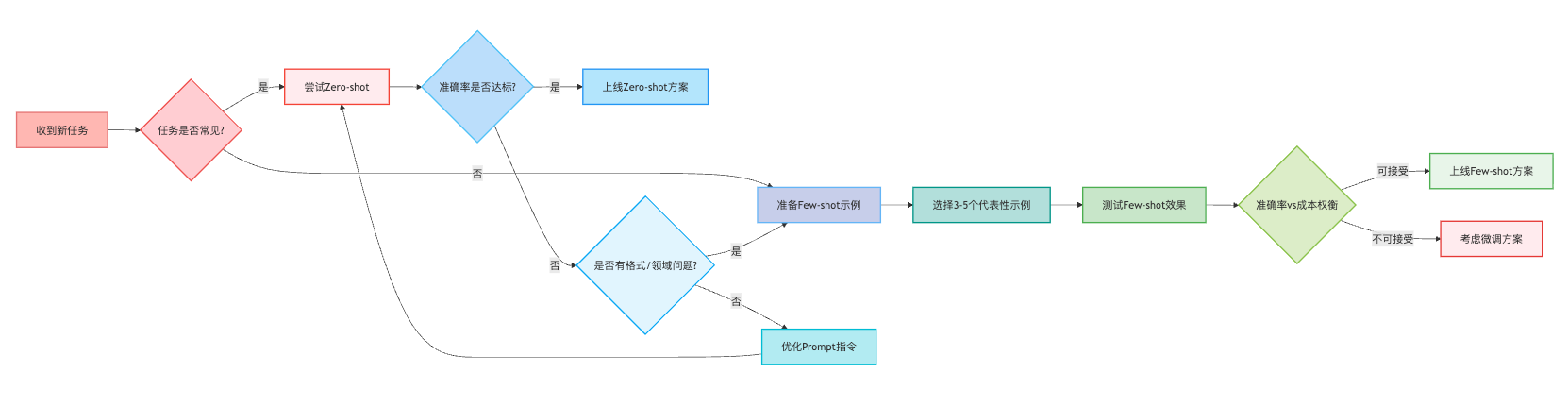
使用场景上,记住一个简单原则:优先用Zero-shot,效果不够再上Few-shot。因为Few-shot会消耗更多token,增加成本和响应时间,所以通用任务用Zero-shot就够了。但如果需要特定输出格式或者专业领域的任务,Few-shot的稳定性会好很多。比如做医疗报告的结构化抽取,字段名称和格式都很专业,用Few-shot给几个标准样本,模型的输出会稳定很多。实践中通常是先试Zero-shot,效果不理想再逐步加示例,找到性价比最优的配置。
扩展分析
深入分析原理差异
这两个概念在传统机器学习时代和现在的大模型时代,其实指的不是完全一样的事情。在传统机器学习时代,Zero-shot通常指的是模型在没见过某些类别的情况下进行分类,比如训练时只见过猫和狗,但要识别老虎,这时会用词向量的语义关系来推理。Few-shot则是针对新类别只有几个标注样本的场景,用元学习或者原型网络这类方法来快速适应。但在现在的大模型时代,这两个概念的含义发生了本质变化,它们更多指的是一种Prompt使用方式。
大模型的Zero-shot和Few-shot本质上都在利用同一种能力——In-Context Learning,也就是上下文学习能力。这是因为大模型在预训练时见过海量的文本模式,它学会了一种元能力:通过上下文推断任务意图。比如让模型做情感分类,Zero-shot时你直接说"判断这段评论是正面还是负面:这个商品质量真不错",模型会从"判断"、"正面"、"负面"这些词里理解任务,再结合预训练时见过的类似模式给出答案。Few-shot时你会先写"这个商品太差了→负面;物流很快→正面;"这样的例子,模型会从这些配对中更精确地理解你要的分类标准和输出格式。
这里有个很有意思的现象值得说一下。模型越大,Zero-shot能力通常越强,因为见过的知识更多。但Few-shot的收益曲线是有拐点的——并不是示例越多越好。通常3-5个精心设计的示例就能达到很好的效果,再增加示例收益会递减,甚至可能因为超出上下文窗口导致性能下降。这背后的原因是大模型的注意力机制在处理长文本时会有信息损失,而且过多示例可能引入噪声或者相互矛盾的模式。
Prompt设计在两种方法中扮演的角色差异也很关键。Zero-shot时,Prompt的关键是任务描述要清晰明确,用词要贴近模型预训练时的语料分布。比如说"翻译成英文"比"translate to English"对中文预训练模型可能效果更好。Few-shot时,Prompt设计的重点转移到示例的质量和多样性上。示例要覆盖不同的边界情况,格式要严格统一,甚至示例的排列顺序都会影响结果——这叫做顺序敏感性。很多人刚开始用Few-shot会踩坑,就是因为没注意到示例选择的科学性,随便挑几条数据就扔进去。 和传统的监督学习、迁移学习相比,这两种方法有本质不同。监督学习需要大量标注数据去更新模型参数,是一个显式的训练过程。Zero-shot和Few-shot都不更新参数,完全是通过Prompt来隐式地引导模型。迁移学习通常是在预训练模型基础上用特定任务的数据进行微调,比如BERT微调,这个过程会修改模型权重。而Zero-shot和Few-shot是保持模型冻结的,只是改变输入的方式。从成本角度看,监督学习和微调都需要标注数据和计算资源,Zero-shot最轻量只需要设计Prompt,Few-shot居中需要准备少量高质量示例。所以实际项目中经常是这样的决策路径:先试Zero-shot能不能满足需求,不行就准备几个示例用Few-shot,还不行才考虑收集数据做微调。
和传统的监督学习、迁移学习相比,这两种方法有本质不同。监督学习需要大量标注数据去更新模型参数,是一个显式的训练过程。Zero-shot和Few-shot都不更新参数,完全是通过Prompt来隐式地引导模型。迁移学习通常是在预训练模型基础上用特定任务的数据进行微调,比如BERT微调,这个过程会修改模型权重。而Zero-shot和Few-shot是保持模型冻结的,只是改变输入的方式。从成本角度看,监督学习和微调都需要标注数据和计算资源,Zero-shot最轻量只需要设计Prompt,Few-shot居中需要准备少量高质量示例。所以实际项目中经常是这样的决策路径:先试Zero-shot能不能满足需求,不行就准备几个示例用Few-shot,还不行才考虑收集数据做微调。
从GPT-3到现在的GPT-4、Claude这些模型,一个明显的趋势是Zero-shot能力越来越强,很多以前必须用Few-shot才能完成的任务,现在Zero-shot就能做得很好。这背后是模型规模、训练数据质量和对齐技术的进步。但Few-shot不会消失,它的价值在于为特定场景做定制化适配,尤其是那些需要严格遵守特定格式或业务规则的场景,比如法律文书生成、财务报表解析这类任务,Few-shot提供的模板化引导是刚需。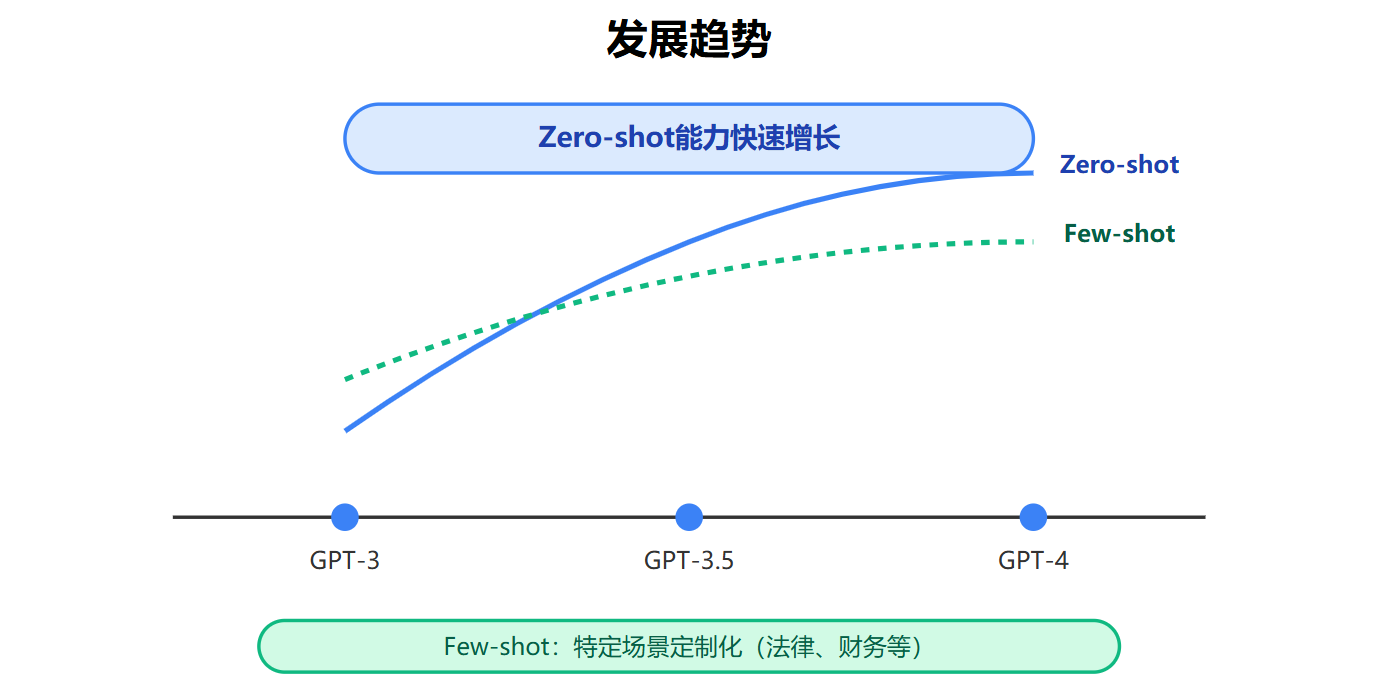
真实场景实战经验
我之前做过一个用户评论分析的需求,正好两种方法都试过。最开始我们用的是Zero-shot,因为任务本身很直白——判断用户评论是正面、负面还是中性。当时设计的Prompt很简单,就是"请判断以下评论的情感倾向,只回答正面、负面或中性",然后把评论内容跟上去。这个方案上线后整体准确率能到75%左右,对于快速验证需求已经够用了。
但后来发现一个问题,有些特定领域的评论模型总是判断错。比如用户说"这个耳机降噪效果一般般",模型经常判成中性,但其实在耳机这个品类里,"一般般"基本就是负面反馈。这时候我们切换成Few-shot,在Prompt里加了3个示例,都是类似这种隐含负面的表达,模型立刻就能理解这种微妙的语境差异了。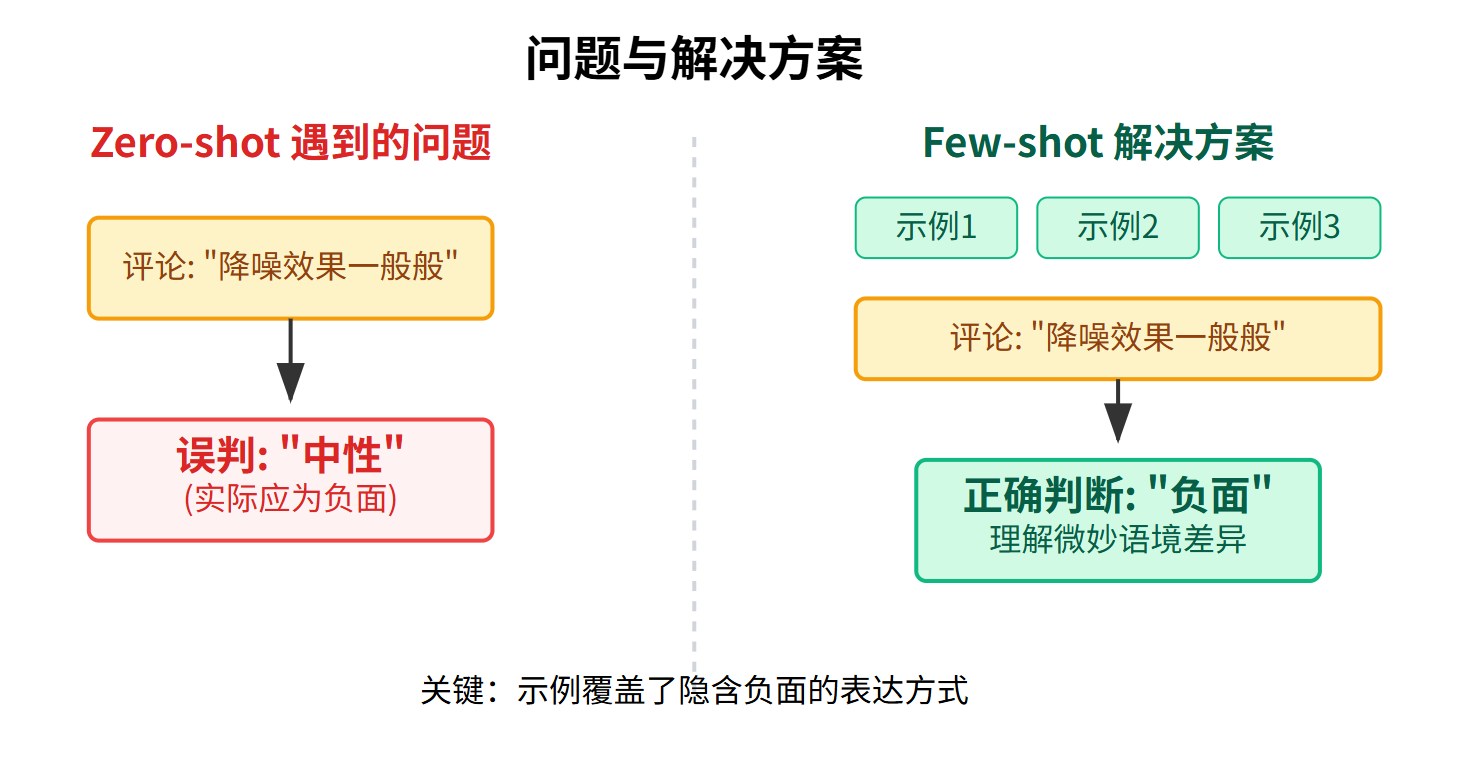 实现上其实不复杂,核心就是构造不同的Prompt。Zero-shot的代码思路很直接:
实现上其实不复杂,核心就是构造不同的Prompt。Zero-shot的代码思路很直接:
defzero_shot_classify(review):
prompt =f"""请判断以下评论的情感倾向,只回答:正面、负面或中性
评论:{review}
情感倾向:"""
response = call_llm_api(prompt)
return response.strip()Few-shot就是在前面加上几个示例,让模型先看到我们期望的输出模式:
deffew_shot_classify(review):
prompt =f"""请判断以下评论的情感倾向,只回答:正面、负面或中性
示例1:
评论:这款手机拍照效果惊艳,完全超出预期!
情感倾向:正面
示例2:
评论:耳机降噪效果一般般,性价比不高
情感倾向:负面
示例3:
评论:包装还行,但没什么特别的
情感倾向:中性
现在请判断:
评论:{review}
情感倾向:"""
response = call_llm_api(prompt)
return response.strip()示例的选择很讲究,我当时花了不少时间测试。最后发现3个示例就能达到最好的效果,示例太少模型理解不充分,太多又会稀释注意力。而且示例要覆盖不同的表达方式,不能都是很极端的表述。
选择用哪种方法我总结了一个快速判断标准。如果任务是常见的通用任务,比如翻译、摘要、基础分类,而且对输出格式要求不严格,直接上Zero-shot就行,这样成本最低响应最快。但如果出现这几种情况,就该考虑Few-shot了:需要特定的输出格式,比如要求返回JSON结构或者固定的字段,这时候示例能清晰定义格式;垂直领域的任务,模型可能对领域知识理解有偏差;发现Zero-shot效果不稳定,有时准有时不准,这说明模型对任务理解不够明确。
评估效果时我一般会先准备一个小的测试集,大概50-100条标注好的数据,分别跑Zero-shot和Few-shot,对比准确率。同时记录每次调用的token消耗,算一下成本。比如上次测试发现,Zero-shot准确率75%,每条消耗200 tokens;Few-shot准确率提升到88%,但每条消耗600 tokens,成本是3倍。这时候就要根据业务需求做决策,如果准确率要求不是特别高,Zero-shot的性价比明显更好。
我踩过几个坑值得分享出来。第一个坑是Zero-shot时指令写得太复杂,我以为越详细越好,结果发现简洁清晰的指令效果反而更稳定。第二个坑是Few-shot时示例格式不统一,有的示例用了冒号,有的用了箭头,模型输出就会乱套。第三个坑是没注意示例的代表性,我一开始随机挑了几条数据做示例,后来发现要挑那些边界case,比如容易误判的类型,这样示例才有引导作用。
实际项目中我们会做分层处理。对于高频的简单任务,比如基础的情感判断,用Zero-shot批量跑,成本控制很重要。对于低频但重要的任务,比如VIP客户的投诉分析,会用Few-shot甚至加上思维链提示,确保准确性。这种混合策略既保证了效果又控制了成本。
有个细节值得提醒,Few-shot的示例最好动态管理。我们后来做了一个示例库,根据不同的子场景维护不同的示例集。比如电子产品的评论和服装类的评论,用的示例就不一样。这样做虽然维护成本高一点,但效果提升很明显。整个技术选型的流程可以用下面这个决策图来表示:
面试中的应对策略
面试官问这道题,表面上是考察你对两个概念的理解,但实际上他想知道的是你有没有真正用过大模型,能不能在实际场景中做技术选型。很多同学回答得很学术,把概念讲得头头道道,但面试官追问"你们项目里怎么用的"就卡壳了。所以这道题的核心不是背定义,而是展现你的落地能力。
面试时要有个意识,面试官很可能会从不同角度追问。比较常见的追问方向是让你对比两种方法的效果差异,这时候千万别说"Few-shot肯定比Zero-shot好"这种绝对的话。面试官想听的是你在什么情况下选择哪个,权衡点是什么。你可以说"我会先用小规模数据测试,如果Zero-shot准确率能达到业务要求,就不会轻易切Few-shot,因为每次调用的token成本会翻倍甚至更多"。这种回答既体现了技术理解,又显示出你有成本意识。
另一个高频追问是让你举具体项目经验。 如果你确实做过相关项目,可以准备一个完整的叙述框架:遇到什么问题、尝试了哪种方法、效果如何、后来怎么优化的。就算没有真实项目经验,也可以说"我在课程作业里尝试过"或者"我做过一个demo验证了这个思路"。面试官能理解校招生经验有限,但你得展示出愿意动手实践的态度。拿个简单场景来说,比如做过一个简历筛选的小工具,最开始用Zero-shot让模型判断简历是否匹配岗位要求,后来发现对技术栈的判断经常不准,就切换到Few-shot给了几个标准案例,准确率立刻提升了。这种小案例说起来真实可信,也能让面试官看到你的思考过程。
回答这道题还有个技巧,就是主动把话题引导到你熟悉的领域。比如你之前用过某个开源模型做过实验,可以在回答时自然提到"我之前用LLaMA测试过这两种方法的效果差异",面试官如果对这个感兴趣就会深入问下去,这样你就能在自己的舒适区展开讨论了。或者你对某个垂直领域比较了解,比如法律文本或者医疗数据,可以说"在这类专业性很强的场景下,Few-shot的优势会特别明显,因为专业术语和输出格式的规范性要求很高"。这样既展示了知识面,又让面试官觉得你思考过实际应用场景。
最后一个加分项是展现你对技术趋势的关注。 面试时可以自然地提一句"现在很多新模型像Claude或者GPT-4的Zero-shot能力已经非常强了,以前需要Few-shot才能解决的问题现在直接Zero-shot就能搞定"。这种观察能让面试官感受到你不是只学课本知识,而是真的在关注行业动态。但注意别说得太多,点到为止就好,避免给自己挖坑。记住面试的核心是展示你能把技术方案落地并持续优化的能力,而不是单纯炫技或者背理论。