精炼回答
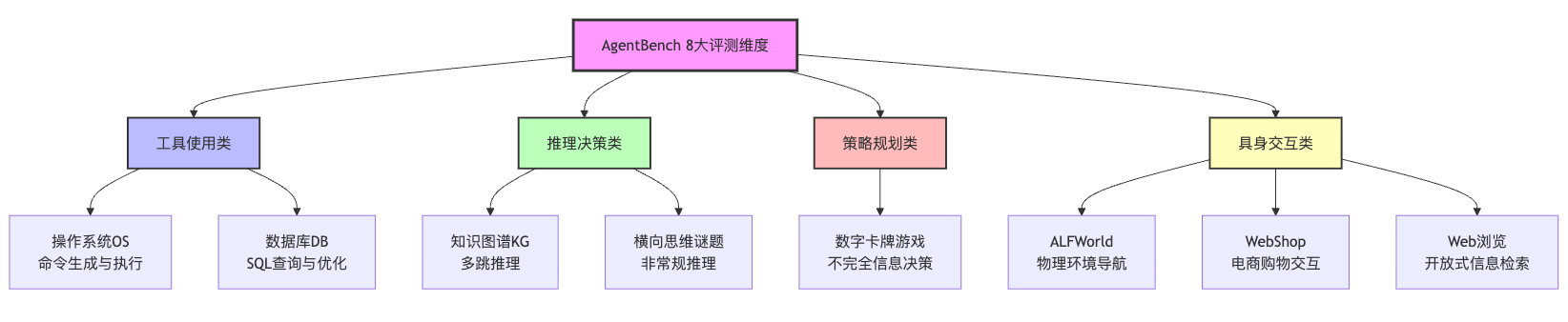
AgentBench是一个多维度的Agent评测框架,核心包含8个不同的交互环境来全面考察Agent能力。这些维度涵盖了操作系统交互(OS)、数据库操作(DB)、知识图谱问答(KG)、数字卡牌游戏、横向思维谜题、家庭环境导航(ALFWorld)、网页交互(WebShop)和网络浏览任务。这套体系跳出了传统静态QA评测的局限,通过真实环境交互来考察Agent在实际任务中的表现。
设计Agent的benchmark需要把握几个关键点:首先是环境的多样性,不能只测单一场景,要覆盖代码、推理、工具使用等不同能力维度;其次是交互的真实性,环境应该能提供实际反馈而非简单的问答对,比如让Agent真正操作文件系统或访问数据库,而不是模拟这些操作;第三是任务的渐进性,要包含从简单到复杂的不同难度级别,能区分出Agent的能力边界。
在具体实现上,benchmark需要定义清晰的成功指标,比如在WebShop任务中衡量商品购买的准确性,在代码任务中检查程序的正确性。同时要设计合理的评分机制,既考虑最终结果,也要关注中间步骤的合理性。另外,环境要有明确的状态转移和终止条件,避免Agent陷入无限循环。整个框架应该可复现、可扩展,方便研究者添加新的评测维度和任务类型。
扩展分析
多维度环境的设计哲学
面试时遇到这个问题,开场的回答框架很重要,建议用"定位-维度-设计"这个三段式结构来组织答案。很多同学容易直接就开始列维度,显得对问题理解不够深入,其实面试官更想听到你对整个评测体系的理解。开场先点明定位,可以说AgentBench是清华团队提出的一个专门评估LLM作为Agent能力的benchmark,它的核心思想是通过多环境交互来考察Agent在真实任务中的表现,而不是传统的静态QA评测。这句话就把AgentBench跟传统benchmark的区别说清楚了,展现你理解它的创新点。
讲8个维度时最忌讳的就是逐个罗列,那样显得特别生硬。更好的方式是按照能力类型来分组阐述。操作系统和数据库属于工具使用类,它们考察Agent能否正确调用系统级工具完成任务;知识图谱和横向思维谜题是推理决策类,重点看Agent的逻辑推理能力;数字卡牌游戏属于策略规划类,需要Agent在不完全信息下做出最优决策;而ALFWorld、WebShop和Web浏览则是具身交互类,强调Agent在真实环境中的多步导航和操作能力。这样归类后再展开,你的回答就有了清晰的逻辑主线。
拿操作系统这个维度来说,面试时可以这样解释:OS任务其实是让Agent像真正的系统管理员一样去完成文件操作、进程管理这些工作。这个维度的核心价值在于验证Agent能否理解自然语言指令,然后将其转化为精确的Shell命令。比如用户说"把上周修改过的日志文件打包备份",Agent需要理解时间条件、文件类型筛选和压缩操作这一连串的语义,最后生成类似find . -name "*.log" -mtime -7 | tar -czf backup.tar.gz -T -这样的命令。这就不是简单的代码生成,而是要在真实环境中执行并处理可能的错误反馈。
数据库维度也是同样的道理。面试官可能会问"数据库操作不就是SQL生成吗,有什么特别的",这时你需要点明差异:单纯生成SQL确实不难,但AgentBench里的数据库任务要求Agent先理解Schema结构,再根据自然语言查询意图写出正确的SQL,执行后还要根据返回结果判断是否需要调整查询策略。这是个典型的多轮交互过程,跟一次性生成SQL完全不是一回事。假设电商场景里遇到这样的需求:"帮我找出最近一个月销量下滑最严重的商品类目"。Agent需要先查询有哪些表,理解销量字段的定义,写出按月统计的SQL,执行后发现数据跨了多个分表,还得调整查询逻辑做聚合。这种动态调整能力才是Agent评测关注的重点。
知识图谱和横向思维谜题这两个维度,很多同学容易觉得比较学术,不知道怎么往实际应用上靠。面试时你可以这样讲:知识图谱任务考察的是Agent在结构化知识上的推理能力,比如问"姚明的妻子的教练是谁",Agent需要在图谱上做多跳推理。这个能力在实际系统中特别有用,比如电商的商品关联推荐,就需要在"用户-商品-类目-品牌"这样的图结构上做路径推理。而横向思维谜题则是测试Agent的非常规推理,传统LLM在标准题目上表现很好,但遇到需要跳出常规思维的问题就容易卡壳。比如经典的"一个人走进酒吧要了杯水,酒保拿枪指着他,他说谢谢后离开"这种谜题,需要Agent从有限信息中推理出隐藏的因果关系。这种能力对应到实际场景里,就是系统异常诊断时能否从反常现象中找到根因。
数字卡牌游戏这个维度特别能体现Agent的决策规划能力。面试时如果被问到,可以说这个任务的设计很巧妙,它给Agent一个不完全信息的博弈环境,对手的手牌是未知的,每一步决策都会影响后续的状态空间。这跟下围棋不太一样,它更强调在信息缺失情况下的概率推理和风险评估。如果面试官追问实际应用,你可以联系到业务决策场景:电商大促期间的库存分配策略就是类似的问题,你不知道竞品会怎么调价,但要根据历史数据和市场信号做出当前的最优决策,这就需要Agent具备在不确定性下的规划能力。
具身交互类的三个维度——ALFWorld、WebShop和Web浏览,其实是AgentBench最有特色的部分。面试时讲这块可以强调:这几个任务把Agent放到了真实的交互环境里,不再是纯粹的文本问答。ALFWorld模拟的是家庭环境中的物品操作,Agent要理解空间关系,比如"把桌上的杯子放到柜子里"需要先导航到桌子位置,拿起杯子,再导航到柜子,打开柜门,放入杯子。这一连串动作规划和执行反馈的闭环,就是典型的Agent行为模式。WebShop更接近实际应用,它不是简单的商品搜索,而是让Agent在一个真实的购物网站界面上操作,要会用筛选器、对比商品属性、加购物车、结算,整个流程跟人类用户一模一样。这就考察了Agent的工具使用、信息抽取和多步决策能力。Web浏览任务则更开放,给Agent一个目标比如"找出某个技术问题的最新解决方案",它需要自己决定搜索什么关键词,访问哪些网页,在页面上提取哪些信息,最后综合给出答案。这种开放式任务最能反映Agent在真实场景中的表现。
讲完这些维度,面试官很可能会问"那你觉得设计这样一个benchmark的难点在哪里"。这时候要把话题引到设计原则和方法论上。最大的挑战其实是平衡真实性和可控性。太真实的环境会导致评测结果不稳定,比如让Agent真的去访问互联网,每次返回的搜索结果可能都不一样,这样就没法比较不同模型的表现。但如果环境太受控又会失去实际意义。AgentBench的做法是构建半真实环境,比如WebShop用的是一个包含真实商品数据但环境固定的模拟网站,这样既保证了任务的真实性,又确保了评测的可复现性。
评测指标的设计也是面试常被问到的点。很多同学只会说"看任务成功率",这就显得理解不够深入。应该这样讲:单纯看成功率容易忽略过程的质量。比如两个Agent都完成了购物任务,一个用了5步精准操作,另一个随机点了20次碰巧买对了,它们的成功率一样但能力差距很大。所以好的评测指标应该是多维度的——任务完成度是基础,看最终结果是否满足要求;步骤效率反映Agent的规划能力,无效操作越少说明理解越准确;鲁棒性则是在任务变体上的表现,比如商品描述稍微改个说法,Agent还能不能找到正确商品。有些任务还会设置部分成功的评分,比如找到了类似但不完全匹配的商品,应该给部分分数而不是简单的对错判断。这样的细粒度评分更能反映Agent的真实能力边界。
数据构建这块经常被忽略,但其实很重要。面试时可以这样说明挑战:构建评测数据集有个三角困境——真实性、多样性和标注成本。真实任务往往很复杂,人工标注正确答案和所有可能的成功路径成本极高。AgentBench采用的策略是分层构建,简单任务用规则生成保证覆盖度,复杂任务从真实场景中采集并人工标注关键节点。如果面试官问怎么保证数据质量,你可以说:一个重要的原则是明确定义成功条件,比如操作系统任务最后会检查文件系统状态是否符合预期,数据库任务会验证查询结果的准确性。这种基于最终状态验证的方式,比逐步标注每个中间动作要可靠得多,也给Agent留出了探索不同解题路径的空间。
从理论到实践的落地方案
面试官如果对你前面的回答感兴趣,很可能会进一步追问"如果让你为公司的某个业务设计一套Agent评测体系,你会怎么做"。这种问题其实是在考察你能否把理论知识转化为实际方案,别慌张,按照一个清晰的思路来回答就好。
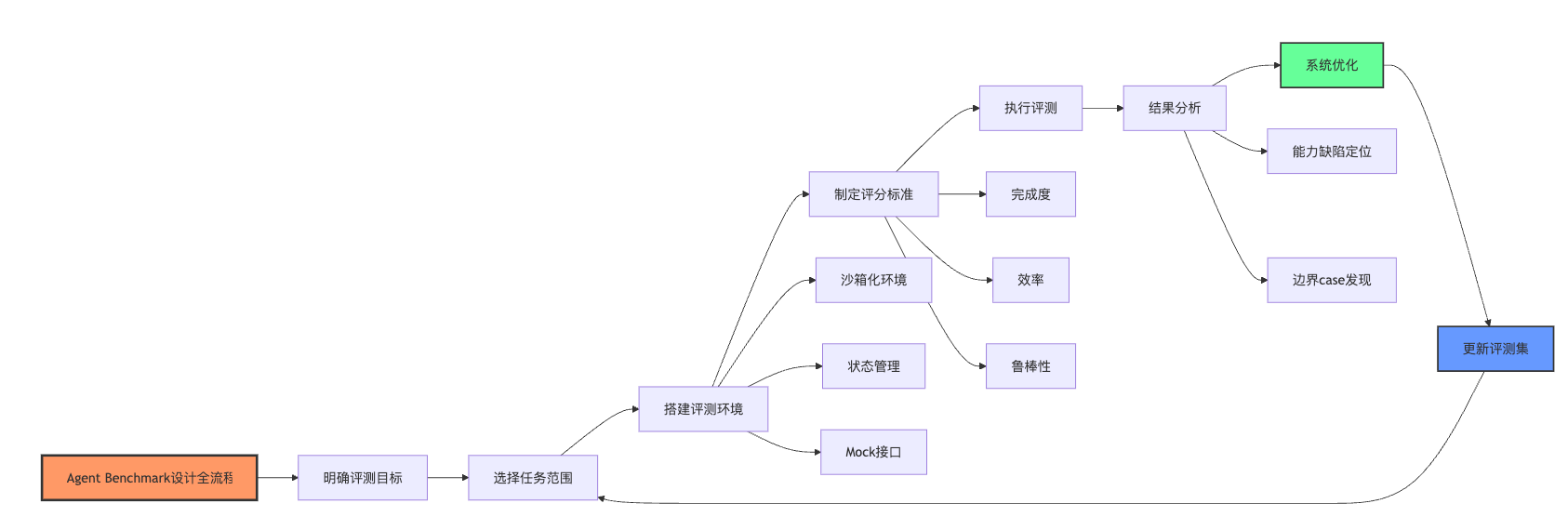
设计benchmark本质上是个系统工程,我会先明确评测目标,再确定任务范围,然后搭建评测环境,最后制定评分标准。这个四步框架说出来,面试官就知道你思路清晰。接下来可以展开说:比如要评测客服Agent的能力,第一步要明确是测它的问答准确性,还是多轮对话中的意图理解,或者是调用工具解决问题的能力。目标不同,后续的任务设计完全不一样。确定目标后,就要选择代表性任务,客服场景可能包括订单查询、退换货处理、商品咨询这几类典型任务,每类任务再按难度分成简单、中等、复杂三档,简单的可能就是直接查询订单状态,复杂的可能涉及多条件筛选加上售后政策判断。
任务选择这块有个关键原则,面试时要特别点出来:选任务不能只看业务频率,还要看能力覆盖。有些业务场景虽然量大但逻辑简单,测出来的区分度不高,反而是一些边缘场景能更好地暴露Agent的能力边界。拿订单查询举例,如果只测"查询订单X的物流状态"这种直给型问题,大部分Agent都能做对。但如果任务是"帮我看看我上个月买的那个黑色双肩包现在到哪了",Agent就需要先从历史订单里根据商品描述和时间范围筛选,再定位到具体订单去查物流,这才能测出真实的信息抽取和多步推理能力。所以任务设计要有区分度,既要有基准任务保证基本功能可用,也要有挑战性任务来拉开能力差距。
环境搭建这块面试官经常会深挖,因为这直接关系到评测的可行性。很多同学会说"搭个真实环境让Agent跑",但这样回答显得考虑不周。更好的表达是:评测环境需要在真实性和可控性之间找平衡,我会采用沙箱化的半真实环境。以客服场景为例,不能让Agent直接连生产数据库去查订单,一是有数据安全风险,二是每次查询结果可能不同导致评测不可复现。更好的方式是准备一个测试数据集,包含各种典型订单状态,然后mock一套查询接口,Agent调用接口时返回预设的数据。这里可以顺便提一句技术细节:接口的mock不能太简单,要模拟真实环境的各种情况,比如超时、部分字段缺失、需要分页查询这些边界情况,这样才能测出Agent的异常处理能力。
// Agent评测环境的沙箱化设计示例
publicclassAgentBenchmarkEnvironment{
privateMap<String,Order> mockOrderDatabase;
privateList<ActionLog> executionLogs;
privateint maxSteps;
publicAgentBenchmarkEnvironment(){
this.mockOrderDatabase =initMockDatabase();
this.executionLogs =newArrayList<>();
this.maxSteps =50;// 防止无限循环
}
// 初始化测试数据集
privateMap<String,Order>initMockDatabase(){
Map<String,Order> db =newHashMap<>();
// 预设各种典型场景的订单数据
db.put("ORDER001",newOrder("ORDER001","黑色双肩包",
OrderStatus.DELIVERED,LocalDateTime.now().minusDays(25)));
db.put("ORDER002",newOrder("ORDER002","蓝牙耳机",
OrderStatus.SHIPPING,LocalDateTime.now().minusDays(2)));
// 边界case:退款中的订单
db.put("ORDER003",newOrder("ORDER003","机械键盘",
OrderStatus.REFUNDING,LocalDateTime.now().minusDays(10)));
return db;
}
// Agent查询接口,模拟真实API行为
publicQueryResultqueryOrder(QueryRequest request){
executionLogs.add(newActionLog("QUERY", request));
// 模拟网络延迟和异常情况
if(Math.random()<0.1){
returnQueryResult.timeout();
}
// 根据查询条件过滤订单
List<Order> results = mockOrderDatabase.values().stream()
.filter(order ->matchQuery(order, request))
.collect(Collectors.toList());
returnnewQueryResult(results, executionLogs.size()< maxSteps);
}
// 评分逻辑
publicBenchmarkScoreevaluate(String taskId,List<String> agentActions){
Task task =TaskRegistry.getTask(taskId);
boolean success = task.verifyResult(mockOrderDatabase);
int steps = executionLogs.size();
double efficiency =calculateEfficiency(steps, task.getOptimalSteps());
returnnewBenchmarkScore(success, efficiency, executionLogs);
}
privatedoublecalculateEfficiency(int actualSteps,int optimalSteps){
if(actualSteps > maxSteps)return0.0;
returnMath.max(0,1.0-(actualSteps - optimalSteps)*0.1);
}
}状态管理是环境搭建里特别容易被忽略的点,面试时如果能主动提到会很加分。可以这样说:Agent的评测环境需要维护清晰的状态,每个任务开始时环境初始化到确定状态,Agent的每次操作都会改变环境状态,最后根据终止状态判断任务是否完成。举个具体例子更容易理解:退换货场景里,初始状态是用户有一个已签收的订单,Agent需要引导用户提供退货理由、上传凭证、选择退款方式,每完成一步环境状态就往前推进,最后检查是否成功创建了退货单。这个过程中要记录所有的状态变化,不仅为了判断结果,也方便后续分析Agent在哪一步出了问题。
评分标准这块是面试的高频考点,千万别只说一句"看成功率"就完了。应该这样展开:评分体系我会设计成多层次的,基础层是任务完成度,看最终结果对不对;第二层是过程质量,包括步骤效率和错误处理,比如Agent是一次性给出正确答案,还是试了好几次才对;第三层是泛化能力,同一类任务换个说法或者改点条件,Agent还能不能做对。商品推荐任务的评分可以这样设计——推荐的商品完全符合用户需求得满分10分,基本符合但有一两个属性不匹配得7分,推荐的类目正确但具体商品不合适得4分,完全答非所问得0分。同时引入效率系数,如果Agent用了超过5轮对话才完成任务,总分打8折。这种具体的评分规则说出来,面试官会觉得你真的思考过实操层面的问题。
讲到这里面试官可能会问"实际操作中会遇到哪些坑",这时候要展现你的实践经验或者对问题的预判能力。最常见的陷阱是过拟合特定任务表述,比如所有测试问题都是"帮我查询订单X"这种固定句式,Agent学会了模式匹配而不是真正理解意图,换个问法就不行了。任务描述要做多样性变换,同一个查订单的意图,可以说成"我的订单X在哪""想看看X这个单子的物流""帮忙查下X发货了没",让Agent必须理解深层语义才能做对。
另一个大坑是评测数据泄露,面试时提到这个会显得很专业:如果用公开数据集或者Agent训练时见过的场景来评测,很可能测出虚高的分数。比较稳妥的做法是定期更新评测集,至少要保证评测数据在Agent的训练截止日期之后产生。有些商品属性或者政策会随时间变化,比如某款手机的价格或者退货政策调整了,如果还用老的参考答案去评测,就失去了实际意义。所以评测集需要有版本管理和定期review机制。
人工标注成本的问题也值得一提,这能体现你对工程效率的考虑:复杂任务的标注成本确实很高,我会采用分层策略,简单任务用规则自动生成答案,比如订单查询这种确定性任务,可以直接根据数据库状态生成标准答案。中等难度任务用少量人工标注做种子集,然后用规则扩展变体。只有那些开放性强、需要主观判断的任务才投入人力精标,比如情感安抚类的对话就需要人工评估回复的合理性。
最后可以总结一个最佳实践:整个评测体系要做到可演进,业务在变化,Agent能力也在提升,评测基准不能是一成不变的。我会设计一个持续更新的机制,定期从线上case里抽取新的困难样本补充到评测集,淘汰掉已经没有区分度的简单任务,这样benchmark才能始终保持对Agent能力的有效评估。
深层挑战与前沿思考
前面咱们讲了AgentBench的维度和设计方法,基本把这道题的主干内容都覆盖了。但面试官问这个题目,其实还有个隐藏的考察点——你是否真正理解Agent评测这个领域的价值和挑战,是否对前沿技术有持续关注。如果你能在回答中自然地展现对一些深层问题的思考,会让面试官觉得你不仅知识储备足,思维深度也够。
安全性评估是个特别容易被忽视但又很重要的话题。面试时如果能主动提到这个点,会显得考虑很周全。可以这样引入:当前的benchmark主要关注Agent的能力边界,但实际部署时安全性同样关键。比如操作系统任务里,如果Agent生成了rm -rf /这种危险命令,或者在数据库查询中构造了SQL注入攻击,这些在功能测试中可能被忽略,但线上环境绝对不能容忍。安全性评测需要单独设计对抗性测试集,故意在任务描述里埋一些容易引发危险操作的诱导信息,看Agent会不会盲目执行。同时要检查Agent生成的中间结果,比如命令或代码执行前做静态扫描,这样既能评估Agent的安全意识,也能验证系统的防护机制是否到位。
随机性处理也是个面试官很爱追问的技术细节。Agent的输出往往带有随机性,特别是基于大模型的Agent,同样的输入可能给出不同的答案。处理随机性有几个常见策略,最直接的是固定随机种子做多次采样,然后看结果的稳定性。比如同一个任务跑10次,如果10次都成功那说明Agent很稳定,如果成功率只有60%就说明这个任务对它来说还不够可靠。有些任务可以接受输出的多样性,比如文本生成类的,这时候就不能简单看是否完全匹配,而要用语义相似度或者人工评估来判断。关键是要在benchmark设计时就明确哪些任务要求确定性输出,哪些允许多样性,然后用不同的评估标准。
如果你有相关的项目经验或实习经历,面试时一定要找机会自然地关联上。不用生硬地说"我在实习时做过",更好的方式是在回答问题时顺带提及。比如讲到环境搭建的复杂性时,可以说:我之前在项目中遇到过类似问题,当时要测试一个自动化运维Agent,最大的挑战就是模拟各种服务器故障场景。后来我们用容器技术搭了个可快速重置的测试环境,每次测试前自动拉起一个干净的系统状态,Agent操作完后检查日志和进程状态,这样既保证了测试的真实性,又解决了环境污染的问题。这种带着具体场景的叙述,比单纯说"我做过相关项目"要有说服力得多。
当前Agent评测的局限性也是个能展现你思考深度的点。面试时可以谈谈你看到的一些不足:现在的benchmark大多关注单个Agent在确定任务上的表现,但实际应用中经常需要多个Agent协作,或者Agent要在开放式目标下自主探索。这些场景的评测还没有成熟的方案。比如多Agent协同的评测,需要设计任务让不同Agent分工配合,这时候不仅要看最终结果,还要评估它们之间的通信效率和冲突处理能力。再比如长期任务的评测,像让Agent管理一个持续运行的系统,这种跨时间跨任务的能力评估,现有benchmark基本没覆盖。
工程成本和自动化程度的权衡也能体现你的工程思维。面试时可以这样表达:理想的benchmark应该全自动运行,但实际上很多复杂任务的评估还需要人工介入,这就带来了成本和效率的矛盾。我觉得可以采用分级策略,日常回归测试用完全自动化的简单任务集,快速验证基本功能没退化。每周或每月做一次深度评测,包含需要人工判断的复杂任务,这样既控制了人力成本,又保证了评测的覆盖度。同时逐步积累人工评估的结果,训练自动评分模型,慢慢把人工判断也自动化掉。
最后特别要提的是benchmark如何指导实际优化,这是面试官很看重的业务价值意识。评测不是为了发论文,最终要落到系统改进上。一个好的benchmark应该能定位出Agent的薄弱环节,比如发现它在多跳推理任务上表现不好,那就针对性地补充这类训练数据或者调整模型结构。假设评测发现Agent在处理模糊需求时成功率很低,那可能需要增强它的澄清询问能力,在遇到不确定的指令时主动跟用户确认,而不是盲目猜测。这种从评测结果到系统优化的闭环,才是benchmark真正的价值所在。这样回答既展现了你对技术的理解,也体现了对业务价值的关注,会让面试官觉得你是个能把技术落地的人。
面试准备时建议你把这8个维度各挑一两个细节记熟,不用每个都能展开,但至少每类能力要有个可以深入讲的例子。这样面试官无论问到哪个具体维度,你都能自然地引到自己熟悉的部分去讲,既展现了知识面的广度,又体现了某些点上的深度思考。记住,面试官不是要考你背过多少维度,而是想看你是否真正理解Agent评测的本质,能否把这套方法论应用到实际业务中去解决问题。